Meta今日推出V-JEPA(Video Joint-Embedding Predictive Architecture)模型,一种通过观看视频来教机器理解和模拟物理世界的方法,以迈向利用对世界的学习理解来计划、推理和完成复杂任务的AI愿景。
这种方法的核心思想是利用视频内容的预测来训练模型,而不是依赖于预先训练的图像编码器、文本、负样本、重建或其他形式的监督。简单来说就是让计算机通过观看大量视频,学习如何理解和解释这些视频中的视觉信息,而不需要人工标注或指导。
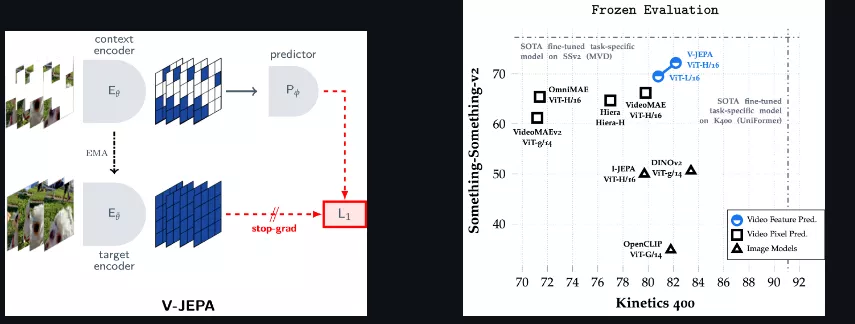
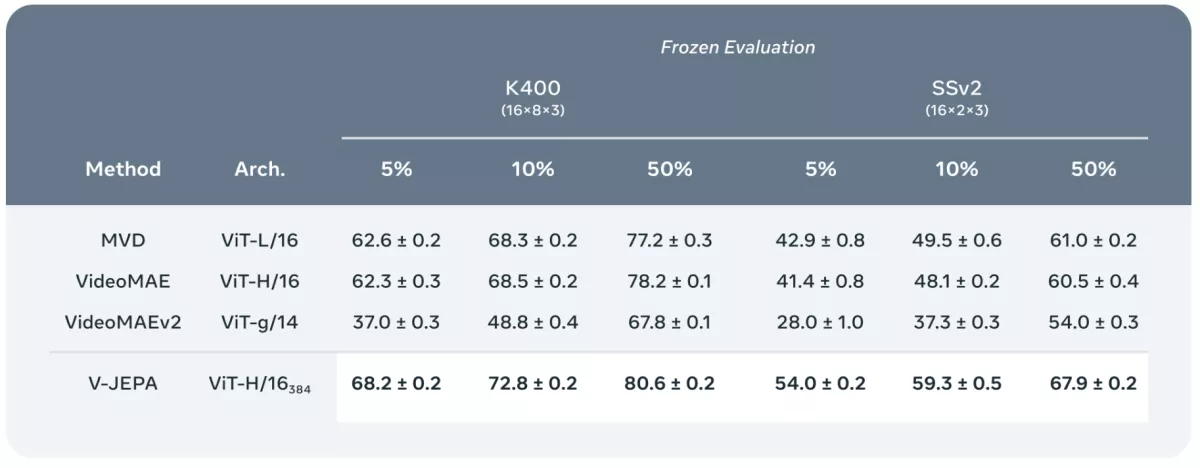
结果表明,其顶级V-JEPA模型在kinect-400上成绩达到82.0%,在Something-Something-v2上达到72.2%,在ImageNet1K上达到77.9%,比肩或超过此前的领先视频模型。
主要功能:
V-JEPA的主要功能是训练视觉模型,使其能够理解和预测视频中的连续帧。这种方法不依赖于任何外部的标注信息,而是通过让模型自己观察视频并预测其中的一部分内容来学习。
主要特点:
- 自监督学习: V-JEPA是一种自监督学习方法,这意味着它不需要人工标注的数据来训练模型。
- 特征预测: 模型通过预测视频中某些区域(被遮挡的部分)的内容来学习,而不是直接预测像素值。
- 多模态学习: V-JEPA结合了视频和图像数据,提高了模型在多种任务上的性能。
- 高效学习: 相比于像素级预测,V-JEPA在训练过程中需要处理的样本数量更少,但仍然能够达到良好的性能。
工作原理:
V-JEPA的工作原理可以分为以下几个步骤:
- 视频处理: 首先,视频被分割成一系列帧,然后这些帧被转换成一系列的“tokens”(类似于图像中的像素块)。
- 编码器和预测器: 视频的一部分(x)被输入到编码器中,编码器学习这些tokens的表示。同时,另一部分(y)被用来训练预测器,预测器尝试从x的表示中预测y的表示。
- 预测和训练: 在训练过程中,模型通过最小化预测表示和实际表示之间的差异来学习。这个过程不涉及反向传播,而是通过一个称为“stop-gradient”的操作来防止信息回流,从而防止模型崩溃。
- 特征空间预测: V-JEPA在特征空间(而不是像素空间)进行预测,这使得模型能够忽略不相关的细节,专注于学习视频中的关键信息。
应用场景:
V-JEPA可以应用于多种视频和图像任务,包括但不限于:
- 动作识别: 在视频中识别人物的动作,如Kinetics-400数据集上的任务。
- 视频理解: 在Something-Something-v2数据集上,理解视频中的复杂动作序列。
- 图像分类: 在ImageNet数据集上对静态图像进行分类。
- 视频内容分析: 对视频内容进行更深层次的理解,如场景识别、物体跟踪等。
V-JEPA提供了一种新的视角来理解和处理视频数据,它通过自监督学习的方式,使得模型能够在没有人工标注的情况下学习到丰富的视觉表示。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











