
SPIN-Diffusion是一种新型文生图模型的微调算法。这个算法特别适用于那些只有单个图像与文本提示(prompt)相关联的数据集,它通过一种自我博弈(self-play)的机制,让模型不断地与自己的早期版本竞争,从而实现自我改进。这种方法不需要人类偏好数据,为那些只有有限数据集的用户提供了一个有用的工具。
SPIN-Diffusion的特别之处在于,它不需要很多人的喜好数据来告诉计算机什么样的图片更好。它只需要一些基本的图片和对应的文字描述,就可以自己学会如何画出更符合描述的图片。这对于那些没有大量数据集的人来说非常有用,因为他们可以用这个方法来训练自己的计算机画画模型,而不需要收集大量的人类评分数据。
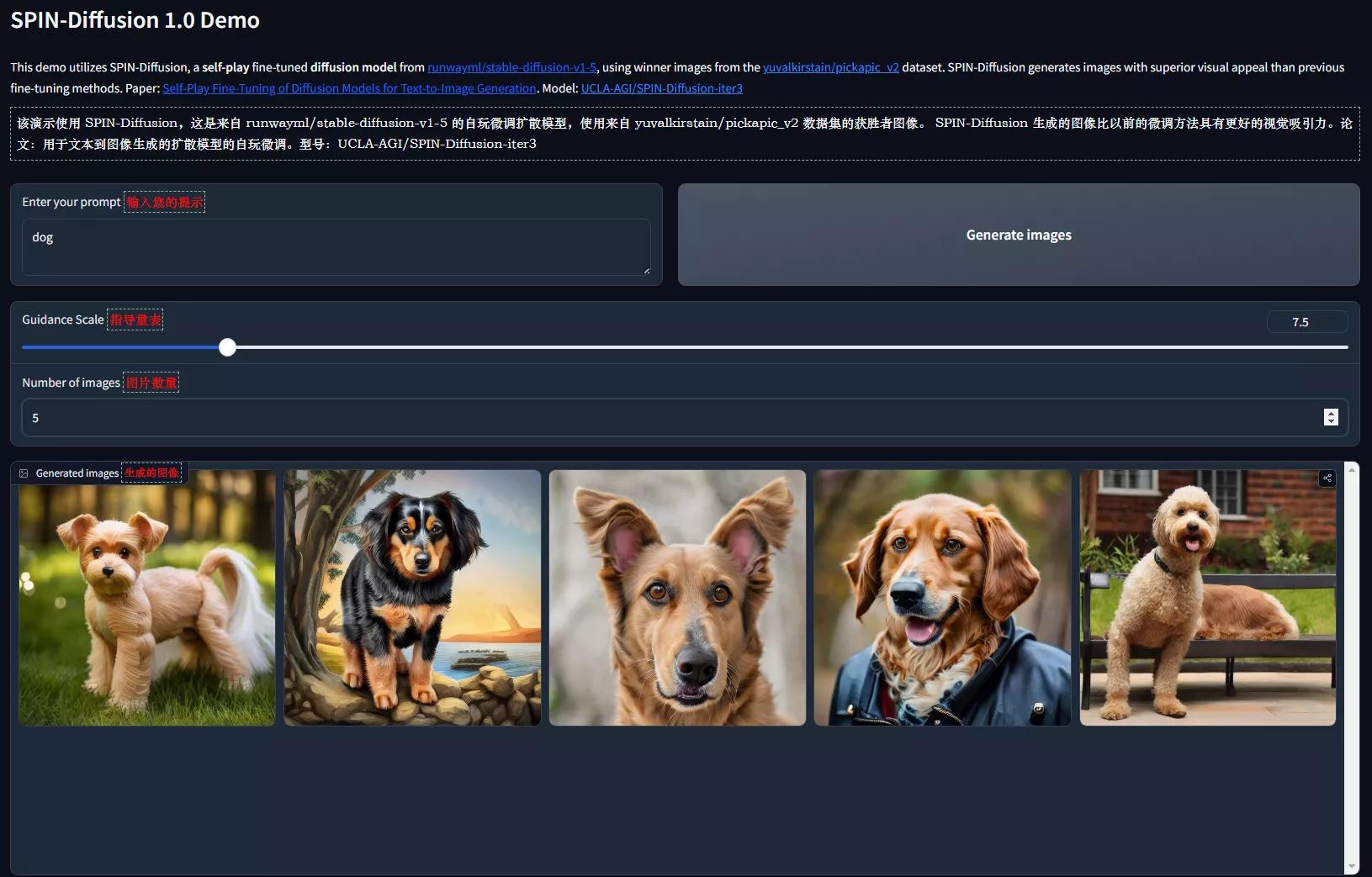
主要功能:
- 自我博弈微调: SPIN-Diffusion通过让模型与自己的早期版本竞争,实现自我改进,从而提高图像生成的质量。
- 无需人类偏好数据: 与需要大量人类偏好数据的强化学习方法不同,SPIN-Diffusion不需要额外的数据,只需要高质量的图像-文本对。

主要特点:
- 迭代改进: 模型通过自我博弈过程,每一轮迭代都会比上一轮表现得更好。
- 理论支持: 论文提供了理论分析,证明了SPIN-Diffusion的优化过程在理论上是收敛的,且达到的模型性能无法通过传统的监督微调(SFT)进一步提高。
- 高效计算: 提出了一种近似目标函数,减少了计算资源的需求,使得模型训练更加高效。
工作原理:
SPIN-Diffusion的核心思想是让模型在每一轮迭代中,都试图生成比上一轮更好的图像。这个过程涉及到两个主要步骤:
- 生成真实和合成的扩散轨迹: 在每一轮迭代中,模型会生成真实的扩散轨迹(来自目标数据分布)和合成的扩散轨迹(来自模型的当前版本)。
- 更新模型参数: 通过比较真实和合成轨迹,模型学习如何更好地模仿真实轨迹。这个过程涉及到一个优化问题,目标是最大化模型生成的图像与真实图像之间的相似度。
应用场景:
- 内容创作: SPIN-Diffusion可以用于生成高质量的图像,适用于游戏、电影、广告等行业的内容创作。
- 个性化图像生成: 用户可以提供文本描述,模型会生成与描述相符的个性化图像。
- 数据集有限的研究: 对于那些只有少量数据集的研究者,SPIN-Diffusion提供了一种有效的微调方法,可以在有限的数据上训练出高质量的模型。
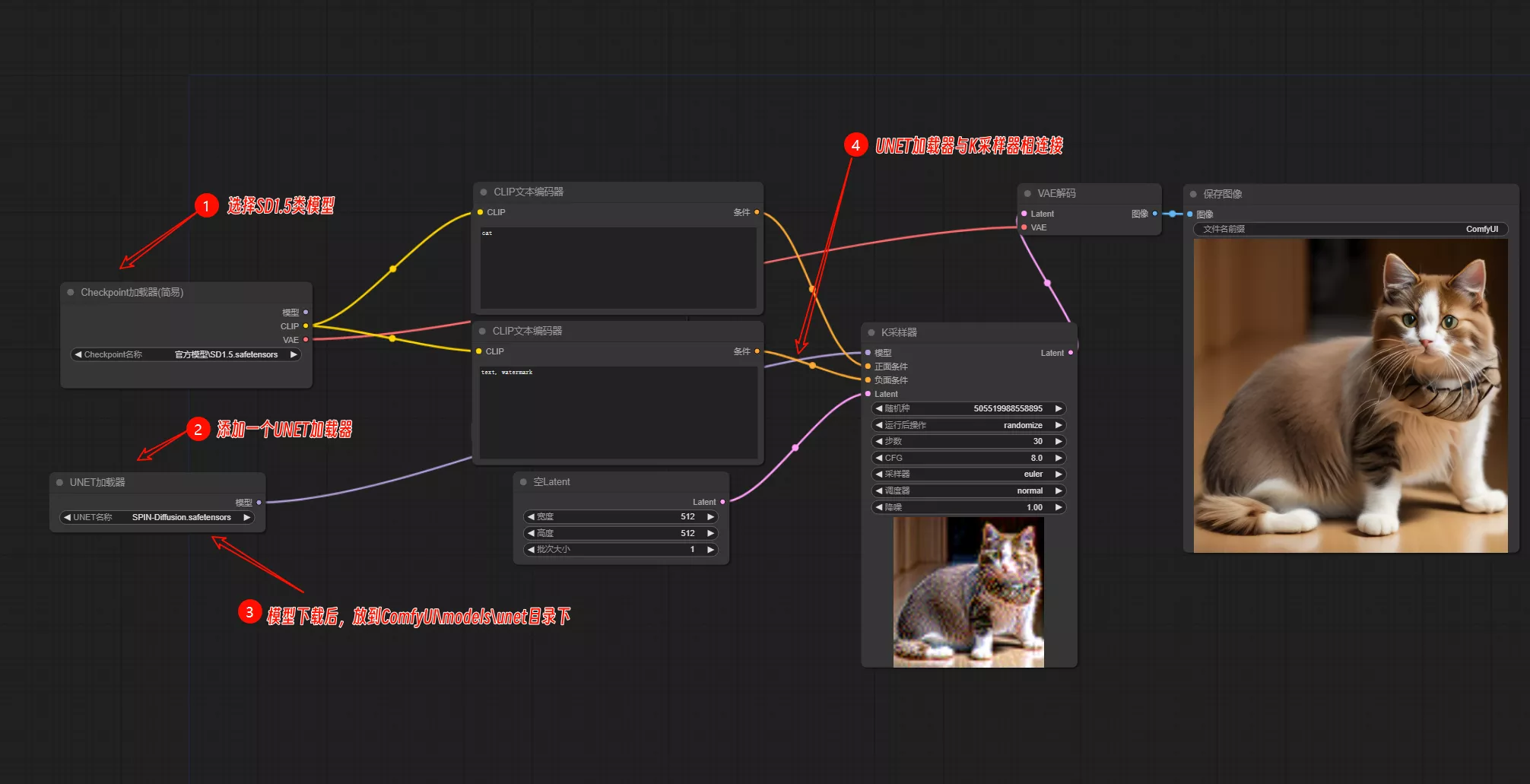
本地运行
可在ComfyUI上运行,在默认工作流上添加一个UNET加载器就行。ComfyUI的使用可参考:ComfyUI教程
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











