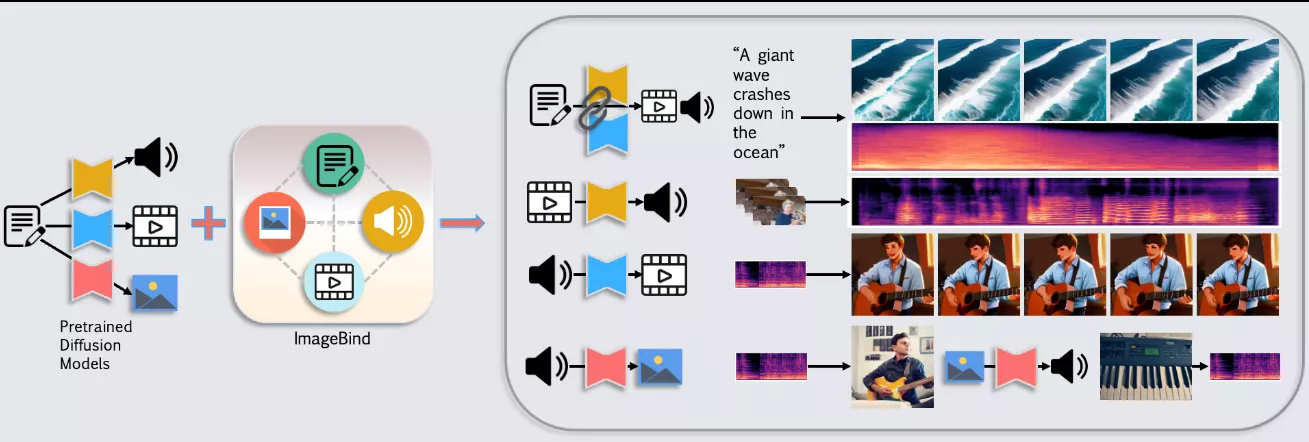
香港科技大学和腾讯 PCG ARC 实验室推出基于优化框架的跨模态视频-音频生成方法Seeing and Hearing,它能够同时生成视频和音频内容。方法的主要创新点在于,通过预训练的多模态模型(如ImageBind)建立不同模态生成模型之间的联系,实现多模态的联合生成。具体来说,在生成一个模态时,同时输入另一个模态的噪声潜在和条件,对齐器可以计算两者在共享嵌入空间中的距离,并将其反向传播以获得生成潜在的梯度。这样可以引导生成过程,使其结果更加符合条件。
想象一下,你想要创造一个场景,比如“海洋中巨浪拍打岸边”,不仅需要视觉上的波浪效果,还需要伴随的海浪声。传统的技术通常分别处理视频和音频,但这种方法将两者结合起来,使得生成的内容更加丰富和真实。
主要功能:
- 同时生成与文本描述相匹配的视频和音频内容。
- 支持多种生成任务,包括视频到音频(V2A)、音频到视频(A2V)、图像到音频(I2A)以及联合视频-音频(Joint-VA)生成。
主要特点:
- 利用预训练的ImageBind模型,将视觉和音频内容在共享的潜在表示空间中对齐。
- 通过优化策略和损失函数,提高了生成内容的质量和对齐度。
- 不需要在大规模数据集上进行训练,资源消耗较低。
工作原理:
- 使用预训练的扩散模型(如AudioLDM和AnimateDiff)作为基础,这些模型能够分别生成视频或音频内容。
- 引入一个多模态潜在对齐器(Diffusion Latent Aligner),它在生成过程中逐步调整视觉和音频的潜在表示,使它们在ImageBind的共享嵌入空间中更接近。
- 在生成过程中,通过最小化不同模态样本在共享空间中的距离,实现语义对齐。
应用场景:
- 电影和视频制作:可以用于生成电影预告片或短片,提供视觉和听觉的双重体验。
- 游戏开发:为游戏场景创建配套的音效和动画,提升游戏体验。
- 虚拟现实(VR)和增强现实(AR):在这些沉浸式环境中,同步的视觉和音频内容可以增强用户的沉浸感。
- 教育和培训:可以用于创建教学视频,通过视觉和听觉的结合,提高学习效果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











