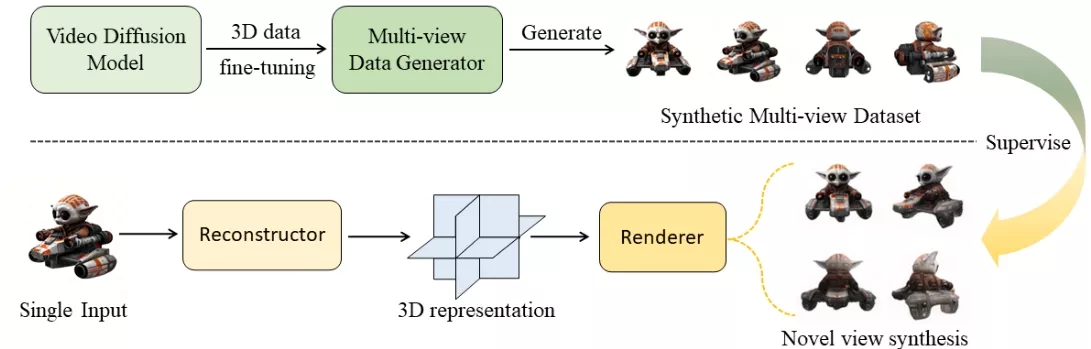
来自Meta和牛津大学的研究团队推出新型3D生成模型VFusion3D,它利用预训练的视频扩散模型来创建可扩展的3D生成模型。这项技术的核心在于解决3D数据稀缺的问题,因为3D数据不像图片、文本或视频那样容易获取,这限制了3D生成模型的发展。
VFusion3D在接近300万个合成多视角数据上进行训练,仅需几秒钟便能从单张图像生成3D资产。与当前最先进的前馈3D生成模型相比,VFusion3D的性能卓越,且在用户测试中,超过70%的用户更偏好我们的结果。

主要功能和特点:
- 高质量3D重建: VFusion3D能够从单张图片中快速生成高质量的3D资产。
- 高效性: 该模型可以在几秒钟内从一张图片生成3D对象,并且用户在超过70%的时间里更喜欢VFusion3D生成的结果,而不是其他现有技术生成的结果。
- 数据生成: 通过微调视频扩散模型,VFusion3D能够生成大规模的合成多视角数据集,用于训练3D生成模型。
工作原理:
- 视频扩散模型微调: 首先,研究者们使用少量3D数据对视频扩散模型进行微调,使其能够生成多视角的视频数据。
- 数据集生成: 利用微调后的视频扩散模型和大量文本提示,生成包含300万个多视角视频的合成数据集。
- 3D生成模型训练: 使用合成的多视角数据集训练VFusion3D模型,使其能够从单张图片中重建3D表示,并渲染新的视角。
具体应用场景:
- 增强现实(AR)/虚拟现实(VR)/混合现实(MR): VFusion3D可以用于创建这些领域中的3D内容,提供更加丰富和逼真的用户体验。
- 3D游戏开发: 游戏开发者可以利用VFusion3D快速生成游戏内的3D模型,提高开发效率。
- 动画制作: VFusion3D能够帮助动画师从概念艺术或单张图片中创建3D角色和场景,加速动画制作流程。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...