
来自清华和极佳科技的研究人员联手推出了全新的视频生成通用世界模型WorldDreamer。它可以完成自然场景和自动驾驶场景多种视频生成任务,例如文生视频、图生视频、视频编辑、动作序列生视频等。
这个模型的核心功能是理解和预测现实世界中的动态环境,从而能够创造出逼真的视频内容。它能够处理多种任务,包括将文本转换为视频、将图片转换为视频、视频修复、视频风格化以及基于动作生成视频。
.webp)
主要功能:
- 文本到视频(Text to Video):根据描述性文本生成相应的视频。
- 图片到视频(Image to Video):从一个静态图片出发,生成连续的视频帧。
- 视频修复(Video Inpainting):在视频中填补或修改特定区域。
- 视频风格化(Video Stylization):改变视频的风格,比如给视频添加秋天的风格效果。
- 动作到视频(Action to Video):基于初始帧和未来的动作指令,生成相应的视频。
主要特点:
- 通用性:WorldDreamer不局限于特定场景,能够处理多种动态环境,如自然景观和驾驶环境。
- 速度优势:与基于扩散模型的方法相比,WorldDreamer在视频生成速度上有显著提升,大约快3倍。
- 多模态交互:模型能够整合文本和动作信号,通过交叉注意力机制在世界模型内部进行交互。
.webp)
工作原理:
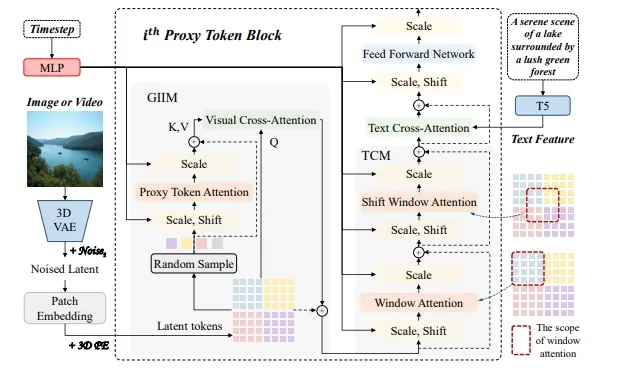
WorldDreamer的工作原理基于以下几个关键步骤:
- 视觉信号编码:首先,将图片和视频转换成离散的视觉标记(tokens)。
- 标记掩蔽(Token Masking):随机掩蔽一部分视觉标记,保留未掩蔽的标记用于预测。
- 多模态提示:将文本和动作输入编码成嵌入(embeddings),作为多模态提示。
- 预测掩蔽标记:使用空间时间分块变换器(STPT)预测掩蔽的视觉标记。
- 视频生成与编辑:预测出的视觉标记由视觉解码器处理,生成或编辑视频。
WorldDreamer通过其强大的视频生成能力,为多个领域提供了创新的可能性,尤其是在需要大量视觉内容生成的场合。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











