视觉-语言模型中的“隐形损耗”:我们如何测量图像信息的丢失?视觉-语言模型(Vision-Language Models, VLMs)如 LLaVA、Qwen-VL 等,在图像理解、视觉问答和图文生成等任务中表现优异。这些模型通常依赖一个核心流程:将图像通过视...多模态模型# 视觉-语言模型6个月前01610
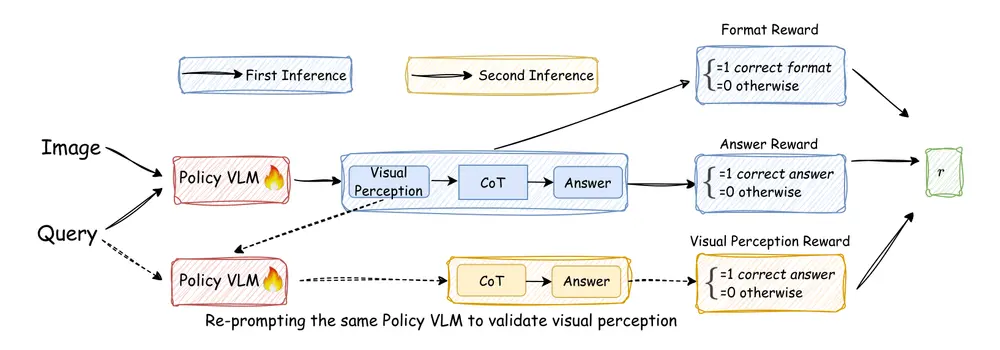
腾讯AI实验室联合两校发布Vision-SR1:自我奖励+推理分解,破解VLM视觉推理难题腾讯AI实验室联合马里兰大学帕克分校、华盛顿大学圣路易斯分校的研究团队,共同发布了新型视觉-语言模型(VLM)——Vision-SR1。该模型聚焦于解决传统VLM的核心痛点,通过创新的“自我奖励机制...多模态模型# Vision-SR1# 视觉-语言模型7个月前03280
LFM2-VL:轻量高效、面向设备端的视觉-语言模型在多模态大模型不断追求更高参数量和更强性能的当下,效率与部署可行性正成为实际应用的关键瓶颈。许多视觉-语言模型(VLM)虽在基准测试中表现优异,但其高计算成本和长推理延迟,使其难以在手机、可穿戴设备或...多模态模型# LFM2-VL# 视觉-语言模型8个月前03680
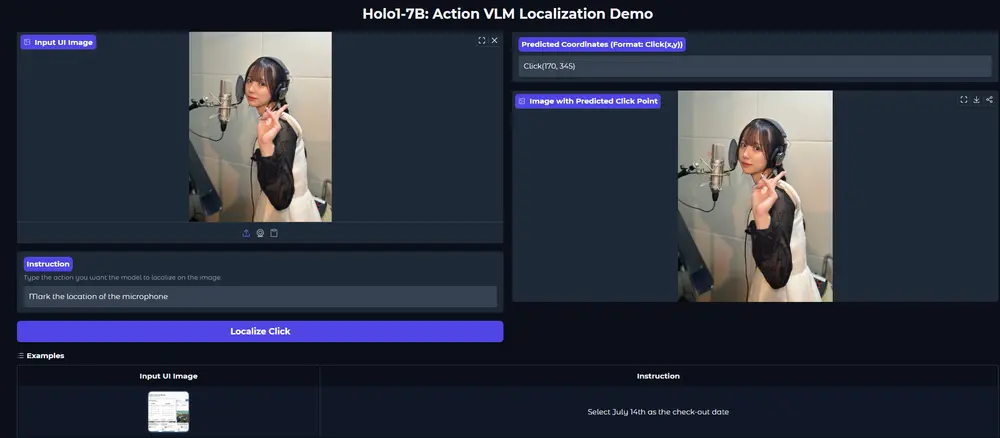
Holo1:HCompany开源高性能视觉-语言模型,赋能Surfer-H代理实现精准网页交互Holo1 是由 HCompany 开发的一款专为网络代理系统设计的 动作视觉-语言模型(VLM),作为 Surfer-H 网络代理的核心组件之一,它具备像人类用户一样与网页界面交互的能力。 模型:h...多模态模型# Holo1# 视觉-语言模型10个月前03430
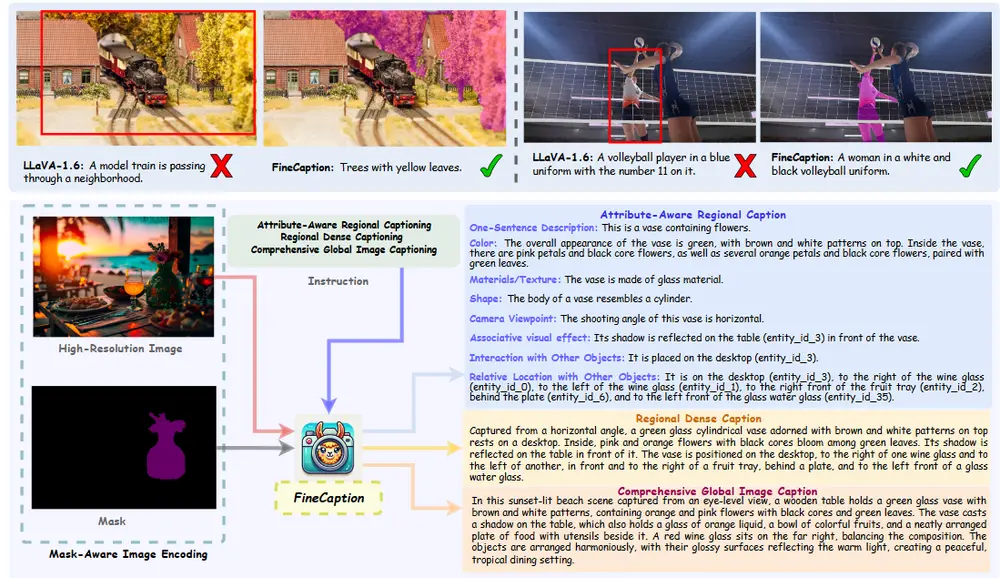
视觉-语言模型FINECAPTION:专注于在任意位置和任意粒度级别上进行组合式图像描述随着大型视觉语言模型(VLMs)的出现,多模态任务的发展取得了显著进展。这些模型在图像和视频字幕、视觉问答以及跨模态检索等应用中展现了强大的推理能力。然而,尽管VLMs具有卓越的表现,它们在细粒度图像...新技术# FINECAPTION# 视觉-语言模型1年前03440