
腾讯AI实验室联合马里兰大学帕克分校、华盛顿大学圣路易斯分校的研究团队,共同发布了新型视觉-语言模型(VLM)——Vision-SR1。该模型聚焦于解决传统VLM的核心痛点,通过创新的“自我奖励机制”与“推理分解”设计,显著提升视觉推理能力,同时减少视觉幻觉(生成与图像不符的内容)和语言捷径(依赖文本先验而非图像信息)问题,为多场景视觉-语言任务提供更精准的解决方案。
为什么需要Vision-SR1?传统VLM的三大痛点
在Vision-SR1出现前,传统视觉-语言模型在处理复杂视觉推理任务时,常面临以下关键问题,导致输出准确性与可靠性不足:
- 视觉感知依赖弱:多数VLM在预训练后期才融合视觉编码器与大语言模型(LLM)主干,训练过程中易倾向于依赖LLM的文本推理能力,而非从图像中提取关键信息,比如面对“图表数据查询”时,可能仅凭常见数据规律作答,忽略图像实际内容;
- 视觉幻觉频发:由于对图像细节捕捉不充分,模型可能生成与图像内容矛盾的描述,例如将“红色汽车”误判为“蓝色汽车”,或无中生有添加图像中不存在的元素;
- 外部奖励局限大:部分改进方案依赖外部大语言模型提供感知奖励,但这种方式不仅会引入外部模型的偏见,还会因多模型交互增加推理延迟,难以满足实时性需求。
Vision-SR1的设计初衷,正是针对上述痛点,通过“让模型自主验证视觉感知”“拆分推理流程”,实现更精准、高效的视觉-语言协同。
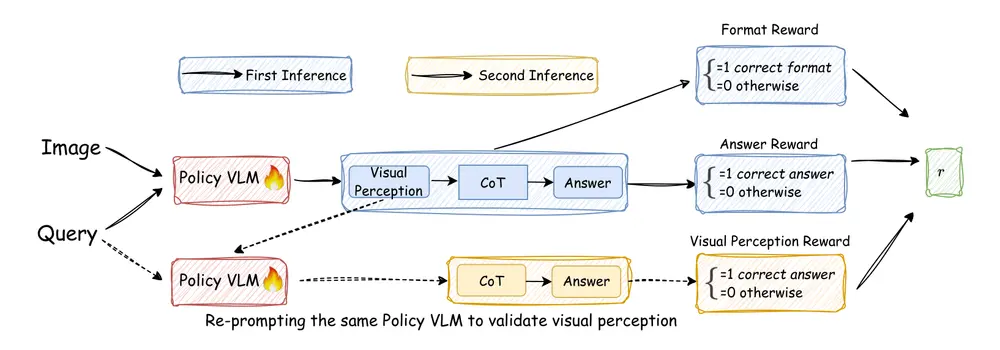
核心创新:两大设计破解VLM推理难题
Vision-SR1的性能突破,源于“推理分解”与“自我奖励机制”两大核心创新,两者相互配合,从流程与反馈两方面优化模型推理逻辑:
1. 推理分解:拆分为“视觉感知+语言推理”两步走
传统VLM的推理过程是“视觉-语言”混合同步进行,易导致视觉信息被语言先验覆盖。Vision-SR1则将推理流程明确拆分为两个阶段,确保视觉感知的独立性与完整性:
- 第一阶段:视觉感知生成
模型首先仅基于输入图像,生成一份“自包含视觉感知描述”——这份描述需涵盖回答后续问题所需的所有视觉细节,比如面对“计算图表中2023年销售额”的问题时,模型会先提取“图表类型为柱状图、2023年对应柱子高度为500万元”等关键视觉信息,不依赖任何文本先验; - 第二阶段:语言推理输出
模型以“视觉感知描述”为唯一输入,进行语言逻辑推理并生成最终答案。此时推理的依据完全来自前期提取的视觉信息,从流程上避免“语言捷径”。
2. 自我奖励机制:模型自主验证,无需外部依赖
为进一步强化“准确视觉感知”的重要性,Vision-SR1设计了不依赖外部信号的自我奖励框架,核心逻辑可概括为“生成-验证-奖励”三步:
- 生成视觉感知:如前所述,模型先基于图像生成视觉感知描述;
- 自主验证准确性:模型通过“重新提示”自身——仅使用刚才生成的视觉感知描述,尝试还原问题答案。若能得出正确结果,说明这份视觉感知描述是完整且准确的;
- 计算自我奖励:根据验证结果为模型打分——验证成功则给予高奖励,鼓励模型继续生成高质量视觉感知;验证失败则降低奖励,倒逼模型优化视觉信息提取能力。
这种机制不仅消除了外部模型带来的偏见与延迟,还能随模型能力提升动态调整奖励标准,避免“奖励黑客”(模型钻规则空子而非真正提升能力)问题。
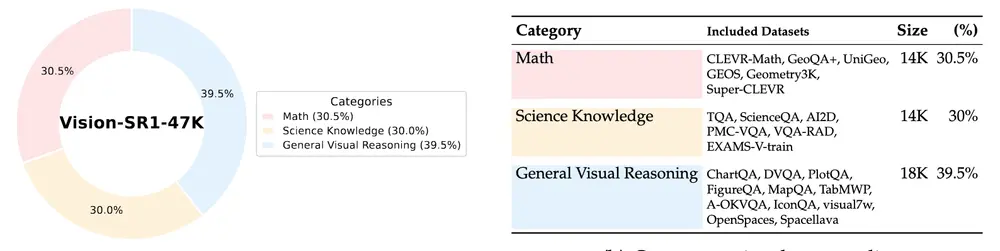
数据集支撑:两大专属数据集保障训练效果
高质量的训练数据是模型性能的基础。研究团队从23个数据来源中筛选、整理,构建了两个专为Vision-SR1设计的数据集,覆盖“监督微调”与“强化学习”全训练流程:
| 数据集名称 | 核心用途 | 覆盖领域 | 特点 |
|---|---|---|---|
| Vision-SR1-Cold-9K | 监督微调(SFT) | 通用视觉理解、科学知识、多模态数学推理 | 数据量精炼(9K样本),聚焦基础能力校准 |
| Vision-SR1-47K | 强化学习(RL) | 同上,且包含更复杂的视觉推理场景 | 数据量更大(47K样本),侧重高阶推理能力提升 |
两个数据集均采用“平均分配领域”的原则,确保模型在通用场景与专业场景(如科学图表解读、数学题图像分析)中均能均衡发展,避免偏向性。
测试表现:多维度超越基线模型
在多个权威视觉-语言基准测试中,Vision-SR1的表现全面优于现有基线模型(包括Vision-R1、Perception-R1、Visionary-R1等),核心优势集中在以下三方面:
- 综合推理性能领先
在Vision-SR1-47K数据集的多任务测试中,模型平均性能比经典基线模型Vision-R1提升1.4个百分点,尤其在“科学知识图像解读”“多模态数学推理”等复杂任务中,优势更为明显; - 语言捷径率(LSR)显著降低
通过LSR指标(衡量模型依赖文本先验而非图像的程度)分析,Vision-SR1在多模态数学推理任务中,语言捷径率较基线模型下降约12%,证明其“以视觉信息为核心”的推理逻辑有效落地; - 文本推理能力不受损
传统改进VLM视觉能力的方案,常导致文本推理能力下降。而Vision-SR1在提升视觉推理性能的同时,文本推理测试得分与基线模型基本持平,实现“多模态能力平衡提升”。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











