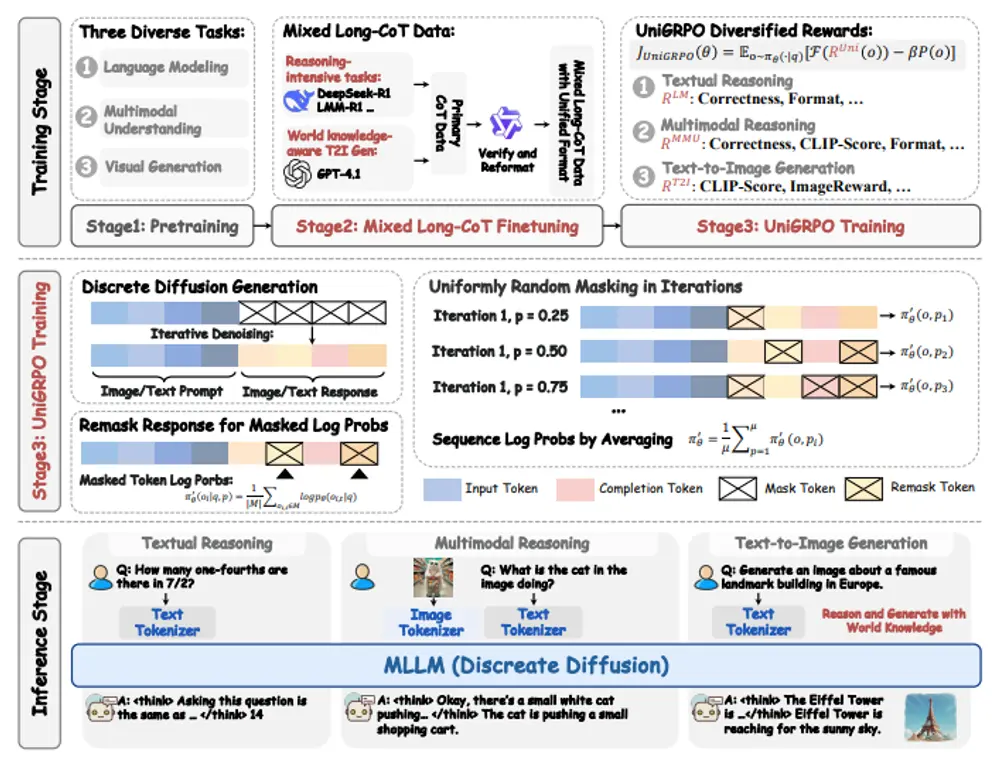
指令引导的图像编辑方法通过在自动合成或手动标注的图像编辑对上训练扩散模型,展示了显著的潜力。然而,这些方法在实际应用中仍然存在明显的不足。滑铁卢大学和威斯康星大学麦迪逊分校的研究人员识别了导致这一差距的三个主要挑战,并推出了一个名为OMNI-EDIT的图像编辑通用模型,它通过专家监督来构建,能够执行多种图像编辑任务。这个模型的设计目标是解决现有图像编辑方法在实际应用中的局限性,如编辑技能有限、数据集噪声大、以及对分辨率和宽高比的限制。
- 项目主页:https://tiger-ai-lab.github.io/OmniEdit
- GitHub:https://github.com/TIGER-AI-Lab/OmniEdit
- 模型:https://huggingface.co/collections/TIGER-Lab/omniedit-6732d8e381c3e56b0a2106d5
例如,一个设计师想要将一张图片中的红色汽车替换为蓝色汽车,并改变图片的风格为水彩画。使用OMNI-EDIT,设计师只需提供相应的文本指令,模型就能够自动执行这些编辑任务,生成满足要求的图像。这展示了OMNI-EDIT在理解和执行复杂编辑指令方面的能力。

主要挑战
编辑技能有限:现有模型由于合成过程的偏差,导致编辑技能受限。 数据噪声和伪影:这些模型通常在噪声和伪影较多的数据集上进行训练,主要是因为使用了简单的过滤方法,如CLIP评分。 分辨率和宽高比限制:现有数据集局限于单一的低分辨率和固定的宽高比,限制了模型处理实际用例的多功能性。
OMNI-EDIT的主要贡献
1、多任务专家模型训练:
任务覆盖:OMNI-EDIT利用七个不同专家模型的监督进行训练,每个模型专注于特定的编辑任务,如添加、移除、交换等。这种多任务训练确保了模型能够无缝处理多种编辑需求。
2、高质量数据采样:
重要性采样:OMNI-EDIT采用基于大型多模态模型(如GPT-4o)提供的评分进行重要性采样,而不是简单的CLIP评分。这种方法显著提高了训练数据的质量,减少了噪声和伪影的影响。
3、新型编辑架构:
EditNet:OMNI-EDIT引入了一种新的编辑架构——EditNet,旨在提高编辑成功率。EditNet通过优化任务特定的编辑精度,减少了基线模型中常见的过度编辑和错误。
4、多样化分辨率和宽高比:
多功能性:OMNI-EDIT在具有不同分辨率和宽高比的图像上进行训练,确保模型能够处理任何实际图像。这种灵活性使其在处理非标准宽高比的图像时表现优异。
工作原理
OMNI-EDIT基于扩散模型,这类模型通过逐步添加高斯噪声到数据中来定义前向(扩散)过程,并学习逆转这一过程的分布。在OMNI-EDIT中,这一过程被用来根据文本指令编辑图像。模型通过专家模型提供的例子和重要性采样来训练,以确保它能够理解和执行各种编辑任务。
测试与评估
为了验证OMNI-EDIT的性能,研究人员精心策划了一个测试集,包含不同宽高比的图像和各种编辑指令,以涵盖不同的任务。测试结果显示,OMNI-EDIT在自动评估和人类评估中均显著优于现有模型。
自动评估:OMNI-EDIT在VIEScore(视觉编辑评分)等自动评估指标上表现出色。 人类评估:人类评估的感知质量(PQ)评分进一步证实了OMNI-EDIT在生成高质量编辑结果方面的优势。
实际应用和未来展望
多样化应用场景
OMNI-EDIT的多功能性和高质量编辑能力使其成为多种应用场景的理想选择,包括但不限于:
虚拟现实(VR)环境:在虚拟世界中实时生成和编辑图像。 媒体制作:电影、电视和广告中的图像编辑和特效制作。 互动设计:游戏和交互式应用中的动态图像处理。
未来发展方向
尽管OMNI-EDIT已经取得了显著的成果,但研究团队认识到未来还有进一步提升的空间。未来的工作方向包括:
利用更先进的基线模型:如Flux等模型,以进一步提高编辑性能。 持续优化数据质量和模型:通过更精细的数据筛选和模型调优,不断提升OMNI-EDIT的性能和适用性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











