
阿里通义实验室发布了Qwen 模型家族的旗舰视觉语言模型Qwen2.5-VL,对比此前发布的 Qwen2-VL 实现了巨大的飞跃。欢迎访问 Qwen Chat 并选择 Qwen2.5-VL-72B-Instruct 进行体验。此外,通义实验室在 Hugging Face 和 ModelScope 上开源了 Qwen2.5-VL 的 Base 和 Instruct 模型,包含 3B、7B 和 72B 在内的 3 个模型尺寸。
- GitHub:https://github.com/QwenLM/Qwen2.5-VL
- 模型: Hugging Face 和 ModelScope
- demo: https://chat.qwenlm.ai

Qwen2.5-VL 的主要特点如下所示:
- 感知更丰富的世界:Qwen2.5-VL 不仅擅长识别常见物体,如花、鸟、鱼和昆虫,还能够分析图像中的文本、图表、图标、图形和布局。
- Agent:Qwen2.5-VL 直接作为一个视觉 Agent,可以推理并动态地使用工具,初步具备了使用电脑和使用手机的能力。
- 理解长视频和捕捉事件:Qwen2.5-VL 能够理解超过 1 小时的视频,并且这次它具备了通过精准定位相关视频片段来捕捉事件的新能力。
- 视觉定位:Qwen2.5-VL 可以通过生成 bounding boxes 或者 points 来准确定位图像中的物体,并能够为坐标和属性提供稳定的 JSON 输出。
- 结构化输出:对于发票、表单、表格等数据,Qwen2.5-VL 支持其内容的结构化输出,惠及金融、商业等领域的应用。
模型性能
阿里通义实验室对视觉语言模型进行了全面的评估,比较了 SOTA 模型以及同尺寸规模模型中表现最好的模型。在旗舰模型 Qwen2.5-VL-72B-Instruct 的测试中,它在一系列涵盖多个领域和任务的基准测试中表现出色,包括大学水平的问题、数学、文档理解、视觉问答、视频理解和视觉 Agent。值得注意的是,Qwen2.5-VL 在理解文档和图表方面具有显著优势,并且能够作为视觉 Agent 进行操作,而无需特定任务的微调。

在较小的模型方面,Qwen2.5-VL-7B-Instruct 在多个任务中超越了 GPT-4o-mini,而 Qwen2.5-VL-3B 作为端侧 AI 的潜力股,甚至超越了之前版本 Qwen2-VL 的 7B 模型。


模型能力案例
1. 万物识别
Qwen2.5-VL 显著增强了其通用图像识别能力,大幅扩大了可识别的图像类别量级。不仅包括植物、动物、著名山川的地标,还包括影视作品中的 IP,以及各种各样的商品。

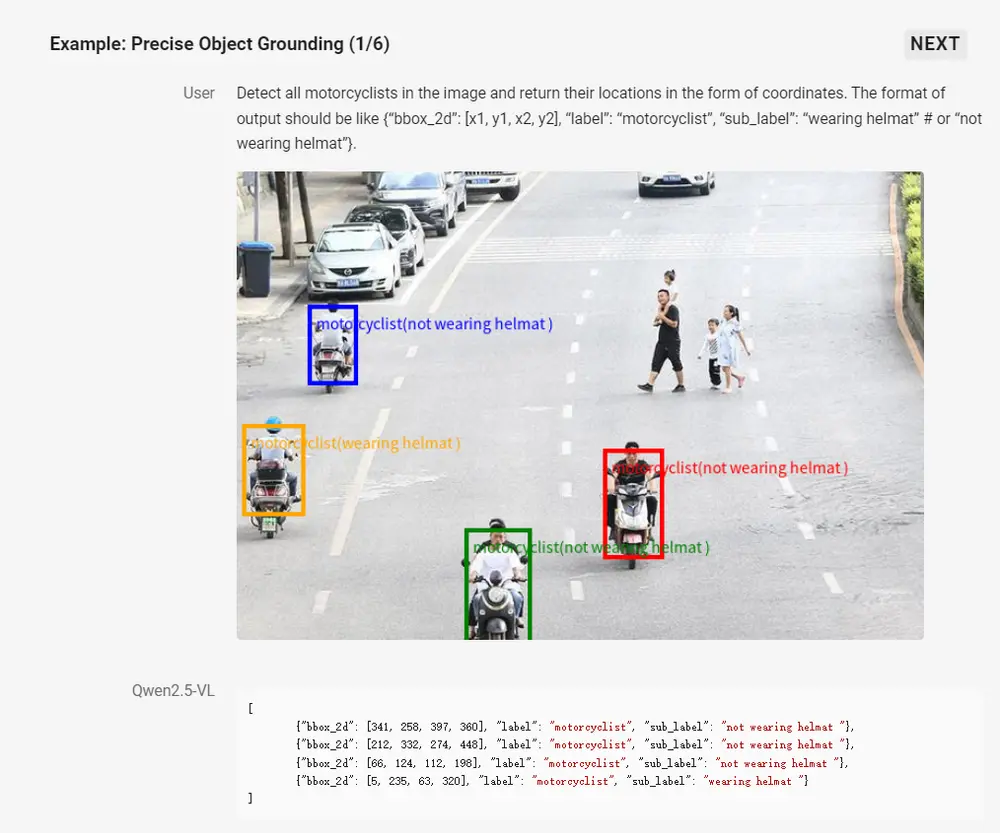
2. 精准的视觉定位
Qwen2.5-VL 采用矩形框和点的多样化方式对通用物体定位,可以实现层级化定位和规范的 JSON 格式输出。增强的定位能力为复杂场景中的视觉 Agent 进行理解和推理任务提供了基础。
3. 全面的文字识别和理解
Qwen2.5-VL 将 OCR 识别能力提升至一个新的水平,增强了多场景、多语言和多方向的文本识别和文本定位能力。同时,在信息抽取能力上进行大幅度增强,以满足日益增长的资质审核、金融商务等数字化、智能化需求。

4. Qwen特色的文档解析
在 Qwen2.5-VL 中,阿里通义实验室在设计了一种更全面的文档解析格式,称为 QwenVL HTML 格式,它既可以将文档中的文本精准地识别出来,也能够提取文档元素(如图片、表格等)的位置信息,从而准确地将文档中的版面布局进行精准还原。基于精心构建的海量数据,QwenVL HTML 可以对广泛的场景进行鲁棒的文档解析,比如杂志、论文、网页、甚至手机截屏等等。

5. 增强的视频理解
Qwen2.5-VL 的视频理解能力经过全面升级,在时间处理上,阿里通义实验室引入了动态帧率(FPS)训练和绝对时间编码技术。这样一来,模型不仅能够支持小时级别的超长视频理解,还具备秒级的事件定位能力。它不仅能够准确地理解小时级别的长视频内容,还可以在视频中搜索具体事件,并对视频的不同时间段进行要点总结,从而快速、高效地帮助用户提取视频中蕴藏的关键信息。

6. 能够操作电脑和手机的视觉 Agent
通过利用内在的感知、解析和推理能力,Qwen2.5-VL 展现出了不错的设备操作能力。这包括在手机、网络平台和电脑上执行任务,为创建真正的视觉代理提供了有价值的参考点。
模型更新
与 Qwen2-VL 相比,Qwen2.5-VL 增强了模型对时间和空间尺度的感知能力,并进一步简化了网络结构以提高模型效率。
时间和图像尺寸的感知
在空间维度上,Qwen2.5-VL 不仅能够动态地将不同尺寸的图像转换为不同长度的 token,还直接使用图像的实际尺寸来表示检测框和点等坐标,而不进行传统的坐标归一化。这使得模型能够直接学习图像的尺度。在时间维度上,引入了动态 FPS (每秒帧数)训练和绝对时间编码,将 mRoPE id 直接与时间流速对齐。这使得模型能够通过时间维度 id 的间隔来学习时间的节奏。

更简洁高效的视觉编码器
视觉编码器在多模态大模型中扮演着至关重要的角色。阿里通义实验室从头开始训练了一个原生动态分辨率的 ViT,包括 CLIP、视觉-语言模型对齐和端到端训练等阶段。为了解决多模态大模型在训练和测试阶段 ViT 负载不均衡的问题,我们引入了窗口注意力机制,有效减少了 ViT 端的计算负担。在ViT 设置中,只有四层是全注意力层,其余层使用窗口注意力。最大窗口大小为 8x8,小于 8x8 的区域不需要填充,而是保持原始尺度,确保模型保持原生分辨率。此外,为了简化整体网络结构,我们使 ViT 架构与 LLMs 更加一致,采用了 RMSNorm 和 SwiGLU 结构。
下一步
在不久的将来,阿里通义实验室将进一步提升模型的问题解决和推理能力,同时整合更多模态。这将使模型变得更加智能,并推动阿里通义实验室向着能够处理多种输入类型和任务的综合全能模型迈进。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











