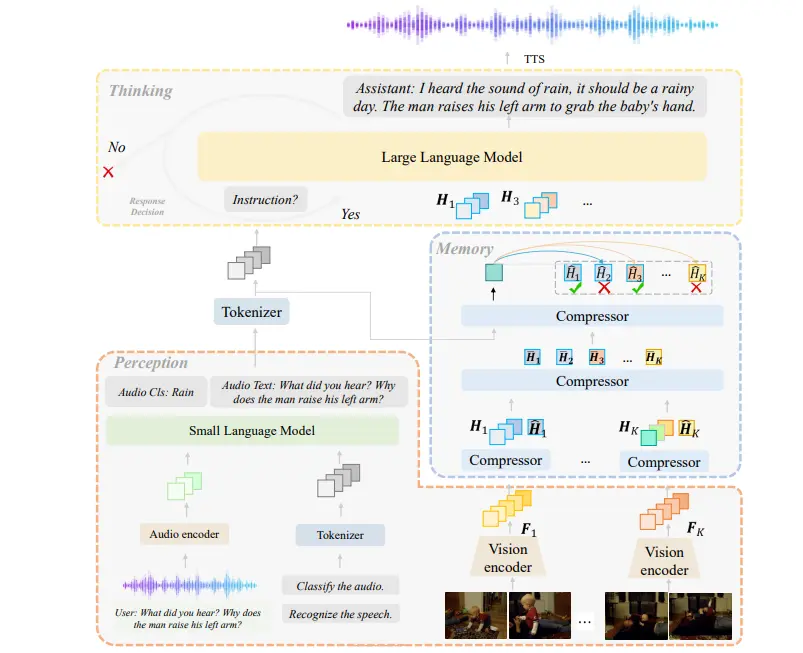
字节跳动和马里兰大学帕克分校的研究人员推出新型开源大型多模态模型LLaVA-Critic,它被设计成一个全能的评估者,用于评估各种多模态任务的性能。多模态任务通常涉及理解和生成与图像、视频和文本相关的信息。通过这种方式,LLaVA-Critic不仅帮助评估现有模型的表现,还能帮助生成模型更好地理解和生成人类偏好的内容。
- 项目主页:https://llava-vl.github.io/blog/2024-10-03-llava-critic
- GitHub:https://github.com/LLaVA-VL/LLaVA-NeXT
- 模型:https://huggingface.co/collections/lmms-lab/llava-critic-66fe3ef8c6e586d8435b4af8
例如,你是一名艺术家,你创作了一幅画,想要了解不同观众可能如何解读它。LLaVA-Critic可以分析你的画作,然后生成几种不同的解释,比如艺术爱好者可能会从技术角度欣赏,宠物爱好者可能会因为画中有他们喜欢的动物而感到高兴,而普通观众可能会觉得这是一种幽默的表达。
主要功能
LLaVA-Critic的主要功能是评估其他多模态模型的表现,具体来说有两个关键应用:
- 作为评委(LMM-as-a-Judge):它可以为视觉聊天等任务中的模型响应提供可靠的评分和排名,与商业模型(如GPT模型)的表现相当。
- 偏好学习(Preference Learning):它可以生成奖励信号,用于增强模型与人类偏好的一致性,从而提升模型的表现。
主要特点
- 开源:LLaVA-Critic是开源的,这意味着研究人员和开发者可以自由访问和使用它的代码、数据集和模型。
- 高质量的评估:它经过了大量多样化的评估标准和场景的训练,可以提供详细且公正的评分。
- 自我提升:通过偏好学习,LLaVA-Critic可以帮助模型自我改进,更好地符合人类的评估标准。
工作原理
LLaVA-Critic的工作原理基于以下步骤:
- 训练数据:它使用一个高质量的批评指令遵循数据集进行训练,这个数据集包含了多种评估标准和场景。
- 评估任务:在给定一个多模态指令(如图像和问题对)时,LLaVA-Critic能够生成评分和排名,以及提供评分的详细理由。
- 偏好信号:在偏好学习中,LLaVA-Critic评估模型生成的多个候选响应,并生成奖励信号,用于指导模型的训练。
具体应用场景
LLaVA-Critic可以应用于多种场景,例如:
- 视觉聊天评估:评估聊天机器人在视觉聊天任务中的表现,比如回答有关图片的问题。
- 内容生成:在生成图片描述或视频字幕的任务中,LLaVA-Critic可以评估生成内容的准确性和相关性。
- 模型微调:在偏好学习中,LLaVA-Critic可以作为反馈机制,帮助模型学习如何生成更符合人类偏好的响应。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











