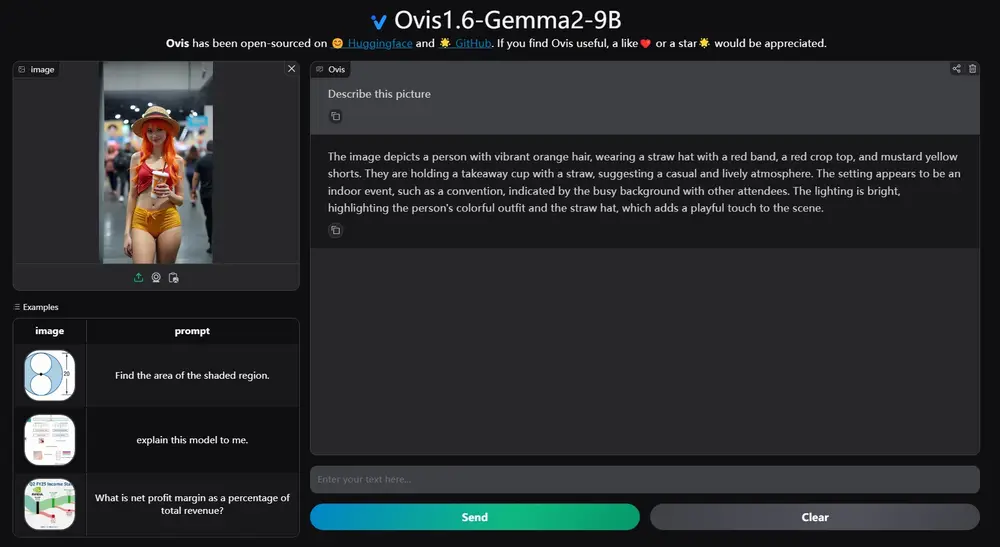
字节跳动、南洋理工大学S-Lab和北京邮电大学的研究人员推出大型多模态模型LLaVA-Video,专门设计来处理视频指令并进行视频内容理解。这个模型特别擅长于解析和生成与视频内容相关的语言描述,比如详细字幕、开放式问答和多项选择问答。
- 项目主页:https://llava-vl.github.io/blog/2024-09-30-llava-video
- GitHub:https://github.com/LLaVA-VL/LLaVA-NeXT
- 数据:https://huggingface.co/datasets/lmms-lab/LLaVA-Video-178K
- 模型:https://huggingface.co/collections/lmms-lab/llava-video-661e86f5e8dabc3ff793c944
主要功能
LLaVA-Video的主要功能包括:
- 视频字幕生成:为视频生成详细的描述性字幕。
- 视频问答:能够理解视频内容并回答有关视频的问题。
- 视频内容分析:分析视频内容并提供有用的反馈。
主要特点
- 高质量数据集:使用了特别为视频指令跟随设计的合成数据集LLaVA-Video-178K,包含178,510个视频和130万个指令样本。
- 动态视频选择:选择未剪辑的、具有显著动态变化的视频,以确保情节的完整性。
- 密集帧采样:采用每秒一帧的密集采样策略,以确保采样的帧足够丰富,能够代表视频。
- 多样化任务:数据集包括字幕、开放式问题和多项选择问题,以评估视频语言模型的感知和推理能力。
工作原理
LLaVA-Video的工作原理基于以下几个步骤:
- 视频源筛选:从多个视频源中筛选出动态且内容丰富的视频。
- 详细视频描述生成:使用GPT-4o模型系统地描述视频内容,生成不同级别的描述(每10秒、每30秒和视频结束时)。
- 视频问题回答:基于详细视频描述,生成各种类型的问题和答案对。
- 视频表示技术:开发了LLaVA-Video SlowFast技术,优化了在有限GPU内存约束下的视觉标记分配,允许在训练过程中包含更多的视频帧。
具体应用场景
LLaVA-Video可以应用于多种场景,例如:
- 视频内容审核:自动为视频内容生成描述和标签,帮助内容审核人员快速理解视频内容。
- 视频搜索和推荐:通过理解视频内容,帮助用户找到他们感兴趣的视频。
- 教育和培训:为教育视频提供详细的字幕和解释,增强学习体验。
- 娱乐和媒体:在视频制作和编辑过程中,自动生成视频描述和元数据,提高工作效率。
举例说明
假设你是一名视频博主,你上传了一个关于如何制作蛋糕的教学视频。LLaVA-Video可以观看你的视频,并生成以下内容:
- 详细字幕:描述视频中的每个步骤,比如“将鸡蛋和糖混合”,“加入面粉和牛奶”。
- 问答:回答观众可能提出的问题,例如“这个蛋糕需要烤多久?”。
- 内容分析:提供视频内容的反馈,比如“视频的光线和声音质量都很好,但背景有些杂乱”。
这样的功能可以帮助视频博主更好地理解他们的观众如何与视频内容互动,并提供更好的观看体验。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











