PaliGemma 是谷歌推出的新一代视觉语言模型家族,其设计灵感来源于PaLI-3,能够接收图像与文本输入并生成文本输出。PaliGemma建立在包括SigLIP视觉模型和Gemma语言模型在内的开放组件之上,旨在为各种视觉语言任务提供领先水平的微调性能。这包括图像和短视频字幕、可视化问答、理解图像中的文本、对象检测和对象分割。谷歌团队已推出三种类型的模型:预训练(PT)模型、混合模型和微调(FT)模型,这些模型分辨率各异,提供多种精度以便使用。
- 官方介绍:https://huggingface.co/blog/zh/paligemma
- 模型地址:https://huggingface.co/collections/google/paligemma-release-6643a9ffbf57de2ae0448dda
- Demo:https://huggingface.co/spaces/big-vision/paligemma
PaliGemma 是什么?
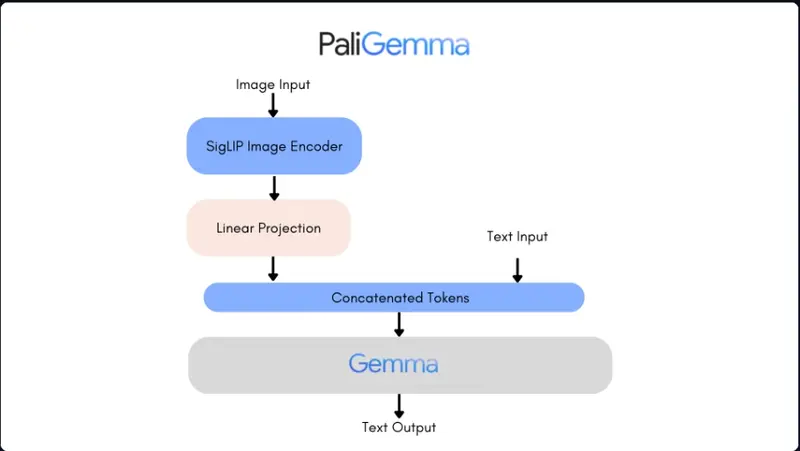
PaliGemma是一系列具有视觉和语言处理能力的模型,由 SigLIP-So400m 作为图像编码器和 Gemma-2B 作为文本解码器构成。SigLIP 是一个顶尖的模型,可以同时解析图像和文本。它的工作方式类似于 CLIP,包括图像和文本编码器的联合训练。与 PaLI-3相似,PaliGemma 模型在图像-文本数据上进行预训练后,可轻松针对下游任务(如图像标题生成或指代分割)进行微调。Gemma是一个专为文本生成设计的解码器模型。通过线性适配器将 SigLIP 的图像编码功能与 Gemma 结合,使 PaliGemma 成为一个功能强大的视觉语言模型。
PaliGemma 的发布包括三种模型类型:
- PT 检查点:预训练模型,可用于下游任务的微调;
- 混合检查点:已针对任务混合进行微调的PT模型,适合使用自由文本提示进行通用推理,仅限研究使用;
- FT 检查点:针对不同学术基准进行微调的模型,提供多种分辨率,仅限研究使用。
这些模型提供三种分辨率(224x224、448x448、896x896)和三种精度(bfloat16、float16、float32)。每个版本都包含给定分辨率和任务的检查点,每种精度有三个版本。每个版本的main分支包含float32检查点,而bfloat16和float16版本则包含相应精度的检查点。同时提供了与 transformers 兼容的模型,以及原始 JAX 实现的版本。高分辨率模型因输入序列较长而需要更多内存。虽然它们可能有助于执行细粒度任务,如 OCR,但对大多数任务的质量提升较小。224 版本已足够应对大多数场景。
模型功能
PaliGemma 是一个单轮视觉语言模型,不适用于对话场景,最佳应用是针对特定用例进行微调。你可以通过设置任务前缀,如“detect”或“segment”,来配置模型解决的任务。预训练模型即是通过这种方式训练的,赋予其丰富的功能(问题回答、图像标题生成、图像分割等)。然而,这些模型并非设计为直接使用,而是通过微调以适应特定任务,使用类似的提示结构。对于交互式测试,你可以使用已对多任务进行微调的“mix”系列模型。
以下是使用混合检查点展示的一些功能示例。
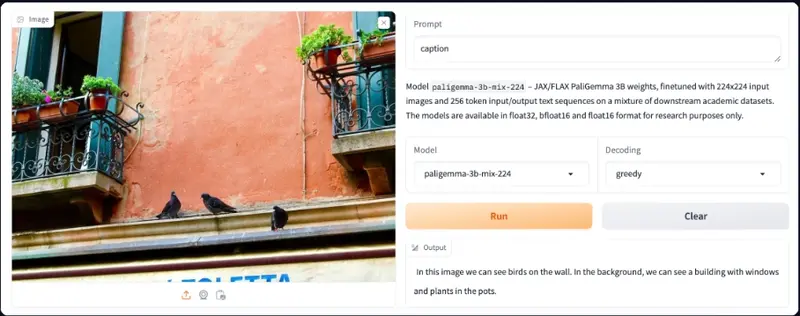
图像标题生成
当被提示时,PaliGemma 能够为图像生成标题。你可以尝试使用混合检查点进行各种标题生成提示,看看它们如何反应。
视觉问题回答
PaliGemma 能够回答关于图像的问题,只需将你的问题连同图像一起传入即可。
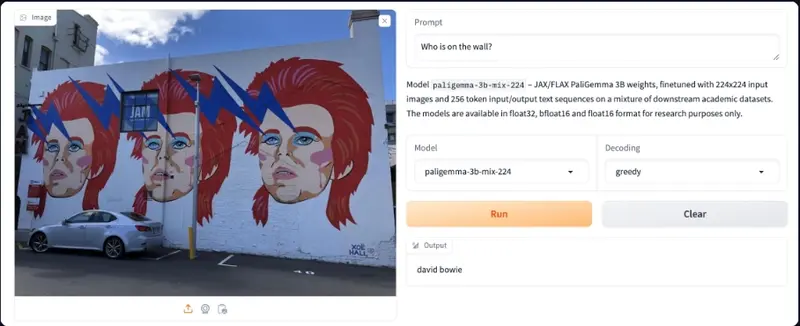
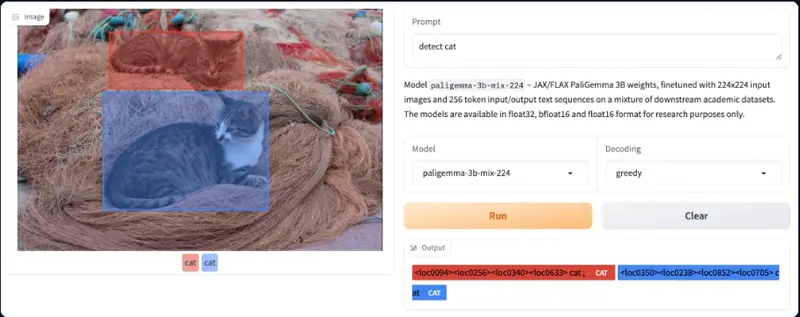
检测
PaliGemma 可以使用detect [entity]提示来检测图像中的实体。它会以特殊的<loc[value]>令牌形式输出边界框坐标的位置,其中value是一个表示归一化坐标的数字。每次检测都由四个位置坐标代表——_y_min, x_min, y_max, x_max_,后跟检测到的框中的标签。要将这些值转换为坐标,你需要首先将数字除以1024,然后将y乘以图像高度,x乘以宽度。这将给你提供相对于原始图像大小的边界框坐标。
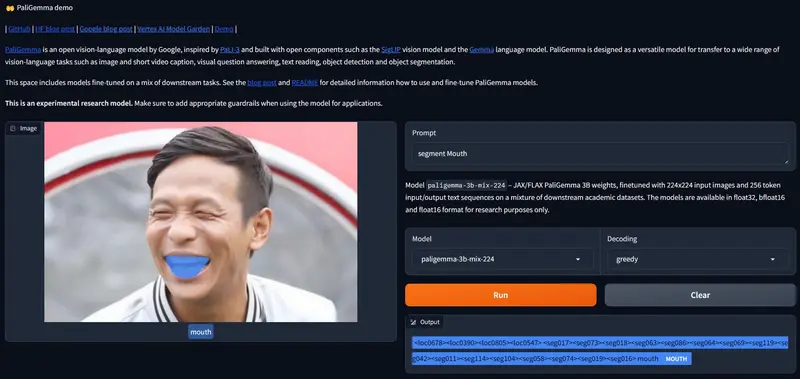
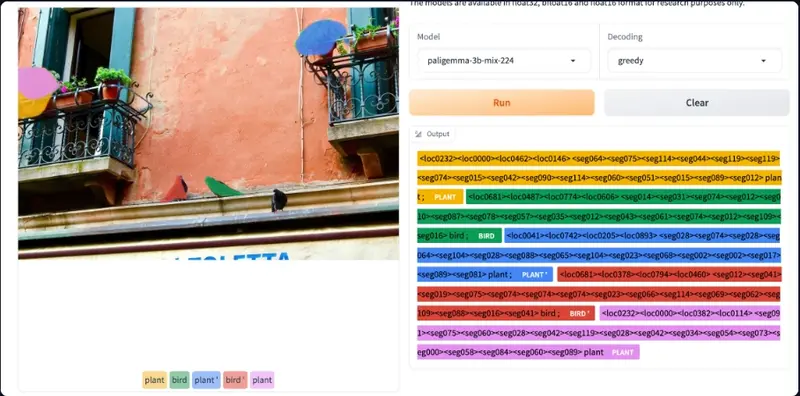
指代表达分割
PaliGemma 混合检查点也能够在给定segment [entity]提示时对图像中的实体进行分割。这称为指代表达分割,因为我们使用自然语言描述来引用感兴趣的实体。输出是位置和分割标记的序列。位置标记代表如上所述的一个边界框。分割标记可以进一步处理,生成分割掩模。
文档理解
PaliGemma 混合检查点具备出色的文档理解与推理能力。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











