
InternVL 2.5 是由上海人工智能实验室、商汤科技研究院、清华大学、南京大学、复旦大学、香港中文大学和上海交通大学等多家机构联合推出的一款先进的多模态大语言模型(MLLM)。该模型基于此前发布的 InternVL 2.0 构建,继承了其核心架构,同时在训练策略、测试配置以及数据质量方面进行了显著增强。通过系统性地研究模型规模与性能之间的关系,研究人员深入探讨了视觉编码器、语言模型、数据集大小和测试时配置对模型表现的影响。
- GitHub:https://github.com/OpenGVLab/InternVL
- 模型:https://huggingface.co/collections/OpenGVLab/internvl-25-673e1019b66e2218f68d7c1c
- Demo:https://huggingface.co/spaces/OpenGVLab/InternVL
InternVL 2.5旨在处理和理解来自多种模态(如文本、图像和视频)的信息,它在多个领域(包括自然语言处理、计算机视觉和人机交互)中展现出了突破性的潜力。该模型通过系统地探索模型扩展和性能之间的关系,包括视觉编码器、语言模型、数据集大小和测试时配置的变化如何影响模型的整体性能。

主要改进
- 模型规模与性能的关系:研究人员系统地探索了不同规模的视觉编码器和语言模型对多模态任务的影响。结果显示,随着模型规模的增加,模型在多模态理解和生成任务中的表现显著提升。然而,过大的模型可能会导致过拟合或计算资源的浪费,因此研究人员找到了一个平衡点,使得 InternVL 2.5 在性能和效率之间达到了最佳的权衡。
- 数据质量的提升:数据是多模态模型成功的关键因素之一。InternVL 2.5 在数据收集和预处理阶段引入了更严格的质量控制措施,确保了数据的多样性和准确性。此外,研究人员还扩展了数据集的规模,涵盖了更多的领域和语言,从而提高了模型的泛化能力。
- 测试时配置优化:在测试阶段,研究人员引入了多种策略来优化模型的表现。例如,通过 Chain-of-Thought(CoT)推理技术,模型能够在复杂任务中逐步推理,最终得出更准确的答案。此外,研究人员还探索了不同的解码策略,如采样和束搜索,以提高生成文本的质量。
主要特点
- 性能提升:InternVL 2.5在多个基准测试中展现出与领先的商业模型(如GPT-4o和Claude-3.5-Sonnet)相媲美的竞争力,特别是在多学科推理、文档理解、多图像/视频理解、现实世界理解、多模态幻觉检测、视觉定位、多语言能力和纯语言处理等方面。
- 开源贡献:作为首个在MMMU基准测试中超过70%准确率的开源MLLM,InternVL 2.5通过链式推理(Chain-of-Thought, CoT)展示了强大的测试时扩展潜力。
- 数据质量关注:在从InternVL 2.0升级到2.5的过程中,数据集大小翻倍,并通过严格过滤显著提高了数据质量。
工作原理
InternVL 2.5遵循“ViT-MLP-LLM”范式,结合了预训练的InternViT(视觉变换器)和各种大小的预训练语言模型(如InternLM 2.5和Qwen 2.5)。它使用一个随机初始化的2层MLP(多层感知器)投影器将视觉编码器与语言模型连接起来。模型还应用了像素重组操作,将每个448×448图像块产生的1024个视觉标记减少到256个标记,以增强高分辨率处理的可扩展性。
性能评估
InternVL 2.5 在多个基准测试中展示了卓越的性能,尤其是在以下几个方面:
- 多学科推理:在涉及多个学科的推理任务中,InternVL 2.5 表现出了强大的跨领域理解能力,能够准确地解析复杂的多模态输入并生成合理的答案。
- 文档理解:对于长文档的理解和摘要生成任务,InternVL 2.5 展示了出色的阅读和理解能力,能够捕捉到文档中的关键信息,并生成简洁明了的摘要。
- 多图像/视频理解:在处理多张图像或视频序列时,InternVL 2.5 能够准确地识别和理解其中的场景、动作和事件,提供了高质量的描述和解释。
- 现实世界理解:针对现实世界的复杂场景,InternVL 2.5 能够结合视觉和语言信息,进行准确的语义理解和推理,帮助用户更好地理解周围环境。
- 多模态幻觉检测:在多模态幻觉检测任务中,InternVL 2.5 表现出了较高的准确性,能够有效区分真实和虚假的多模态输入,避免产生误导性的输出。
- 视觉定位:在视觉定位任务中,InternVL 2.5 能够根据给定的图像或视频片段,准确定位物体或场景的位置,适用于导航、机器人等领域。
- 多语言能力:InternVL 2.5 支持多种语言,包括但不限于中文、英文、法文、德文等,展现了强大的跨语言理解和生成能力。
- 纯语言处理:除了多模态任务,InternVL 2.5 在纯语言处理任务中也表现出色,能够生成流畅、自然的语言文本,适用于对话系统、翻译等应用。
基准测试结果
- MMMU 基准测试:InternVL 2.5 是首个在 MMMU(Multi-Modal Multi-Understanding)基准测试中超过 70% 的开源 MLLM,通过 CoT 推理实现了 3.7 个百分点的提升。
- 与商业模型对比:InternVL 2.5 在多个基准测试中与领先的商业模型如 GPT-4 和 Claude-3.5-Sonnet 相媲美,甚至在某些任务上超过了这些模型。
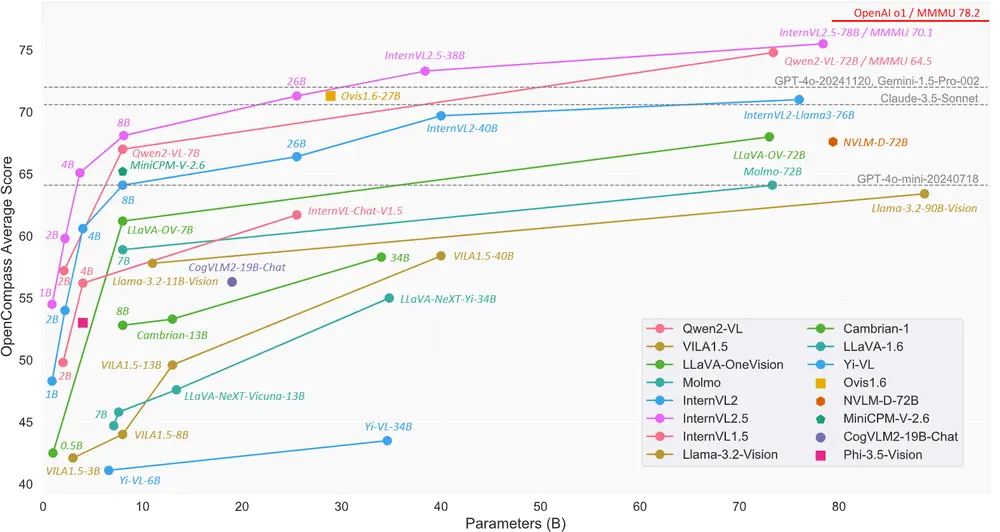
测试时扩展潜力
InternVL 2.5 还展示了强大的测试时扩展潜力。研究人员发现,通过增加推理步骤或使用更复杂的解码策略,模型的性能可以进一步提升。这为未来的模型优化和应用提供了广阔的空间。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











