
今年一月底,阿里通义实验室推出了 Qwen2.5-VL 系列模型,凭借其卓越的性能和广泛的应用潜力,迅速获得了社区的广泛关注和积极反馈。在此基础上,团队通过强化学习持续优化模型,并于近期开源了备受期待的 32B 参数规模的新模型——Qwen2.5-VL-32B-Instruct。这一举措不仅进一步推动了多模态模型的发展,也为社区带来了更多创新的可能性。
- 项目主页:https://qwenlm.github.io/zh/blog/qwen2.5-vl-32b
- 模型:https://huggingface.co/Qwen/Qwen2.5-VL-32B-Instruct
Qwen2.5-VL-32B-Instruct 的特点
1. 更符合人类主观偏好的回复
相比此前发布的 Qwen2.5-VL 系列模型,新推出的 32B 模型在输出风格上进行了显著调整。回答更加详细、格式更加规范,并且更符合人类的偏好。这一改进使得模型在生成文本时能够更好地满足用户的需求,提升用户体验。
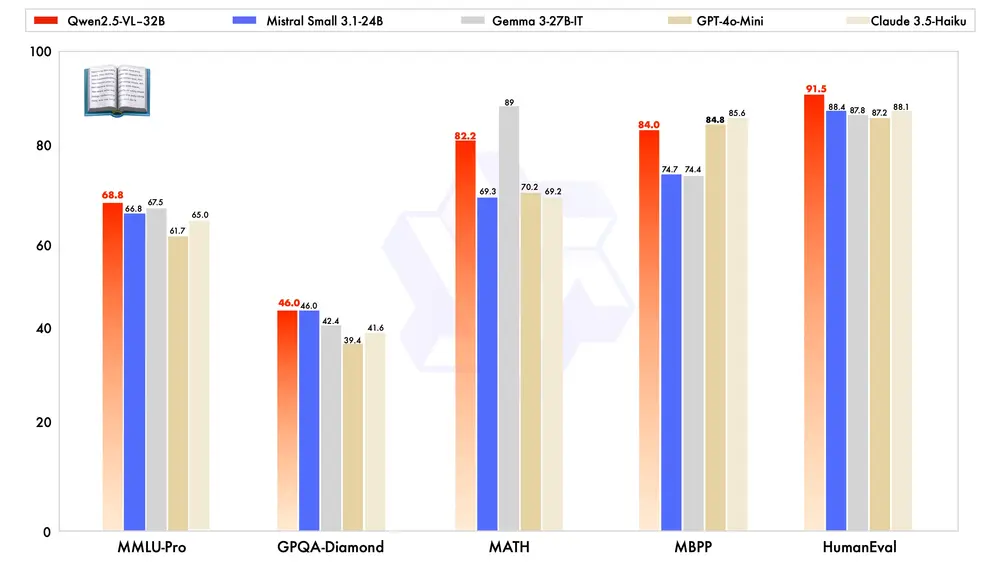
2. 显著提升的数学推理能力
Qwen2.5-VL-32B-Instruct 在复杂数学问题的求解上表现出色,准确性显著提升。这一改进使得模型在处理复杂的数学问题时更加可靠,能够为用户提供更准确的答案。
3. 更强的图像细粒度理解与推理能力
在图像解析、内容识别以及视觉逻辑推导等任务中,Qwen2.5-VL-32B-Instruct 表现出更强的准确性和细粒度分析能力。这一改进使得模型在处理图像相关任务时更加精准,能够更好地理解和推导图像内容。
性能表现
1. 多模态任务中的卓越表现
与业内先进的同规模模型进行比较,包括近期推出的 Mistral-Small-3.1-24B 和 Gemma-3-27B-IT,Qwen2.5-VL-32B-Instruct 展现出了明显的优势,甚至超越了更大规模的 Qwen2-VL-72B-Instruct 模型。尤其是在多模态任务中,例如 MMMU、MMMU-Pro 和 MathVista,这些任务强调复杂的多步骤推理,Qwen2.5-VL-32B-Instruct 表现尤为突出。
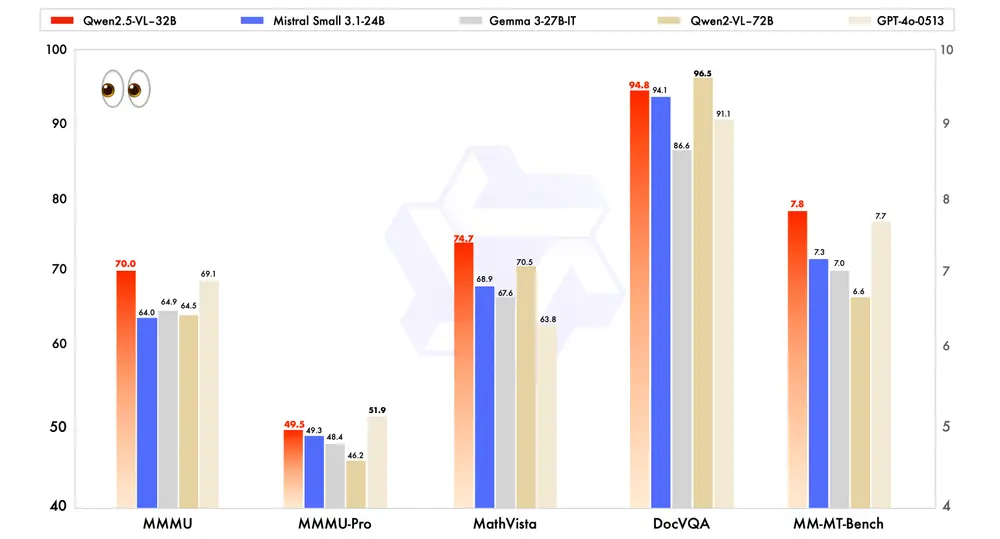
2. 主观用户体验评估中的显著进步
在注重主观用户体验评估的 MM-MT-Bench 基准测试中,Qwen2.5-VL-32B-Instruct 相较于其前代 Qwen2-VL-72B-Instruct 取得了显著进步。这一改进表明,新模型在生成内容的自然度和用户满意度方面有了显著提升。
3. 纯文本能力的最优表现
除了在视觉能力上的优秀表现,Qwen2.5-VL-32B-Instruct 在纯文本能力上也达到了同规模的最优表现。这一改进使得模型在处理文本任务时更加高效和准确,能够为用户提供高质量的文本生成服务。
开源与社区支持
Qwen2.5-VL-32B-Instruct 采用 Apache 2.0 协议开源,这意味着社区用户可以自由使用、修改和分发该模型。开源不仅促进了技术的共享和传播,也为社区带来了更多的创新机会。通过开源,开发者可以基于 Qwen2.5-VL-32B-Instruct 进行定制化开发,探索更多应用场景。
下一步计划
尽管 Qwen2.5-VL-32B 在强化学习框架下优化了主观体验和数学推理能力,但团队的下一步研究将聚焦于长且有效的推理过程,以突破视觉模型在处理高度复杂、多步骤视觉推理任务中的边界。这一研究方向将为多模态模型的发展带来新的突破,进一步提升模型在复杂任务中的表现能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











