
近年来,随着机器学习技术的飞速发展,视觉-语言模型(VLM)的需求不断增加。这些模型能够处理图像和文本的组合任务,如图像描述、问答和故事生成等。然而,大多数现有的VLM需要大量的计算资源和内存,这限制了它们在轻量级设备上的应用。为了解决这一问题,Hugging Face推出了轻量级多模态模型SmolVLM,旨在在性能和资源需求之间取得平衡。
- 官方详解:https://huggingface.co/blog/smolvlm
- 模型:https://huggingface.co/collections/HuggingFaceTB/smolvlm-6740bd584b2dcbf51ecb1f39
- Demo:https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
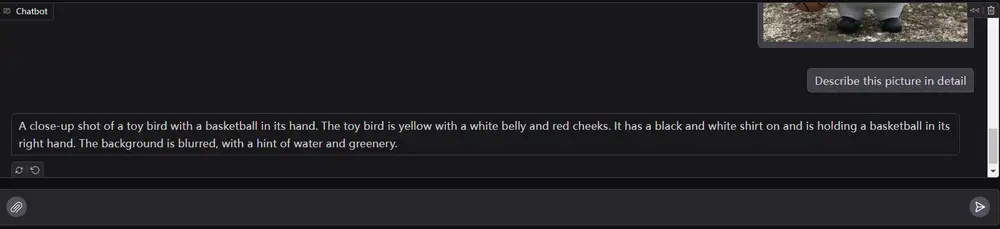
SmolVLM 概述
SmolVLM 是一个参数量为20亿的小型多模态模型,被誉为同规模模型中的State-of-the-Art(SOTA)。它能够接受任意图片和文字的组合作为输入,并生成文字输出。SmolVLM的主要特点包括:
- 轻量级架构:SmolVLM基于Hugging Face之前推出的视觉模型IDEFICS 3,但进行了多项优化,使其更适合轻量级设备。
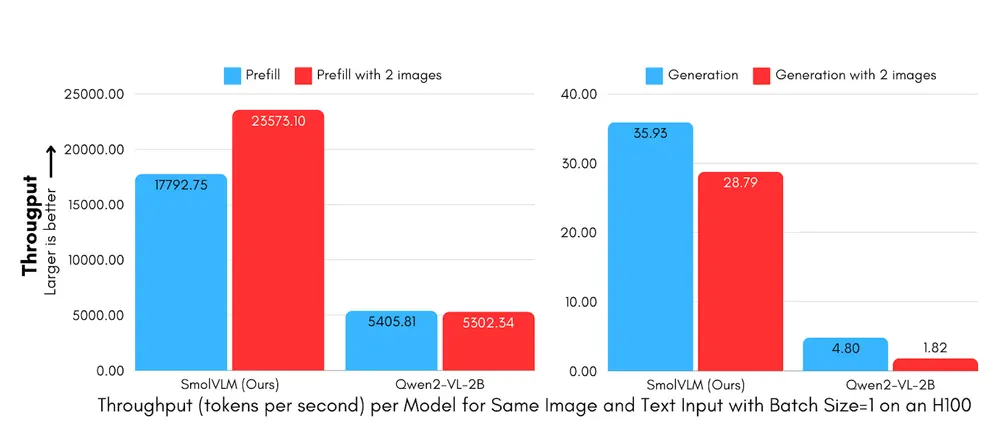
- 高效能:SmolVLM在相同的GPU内存使用和令牌吞吐量下优于其他模型,特别是在令牌生成速度方面,比Qwen2-VL快7.5到16倍。
- 多模态任务支持:SmolVLM能够回答关于图片的问题、描述图片内容,根据多张图片生成故事,也可以作为纯语言模型使用。
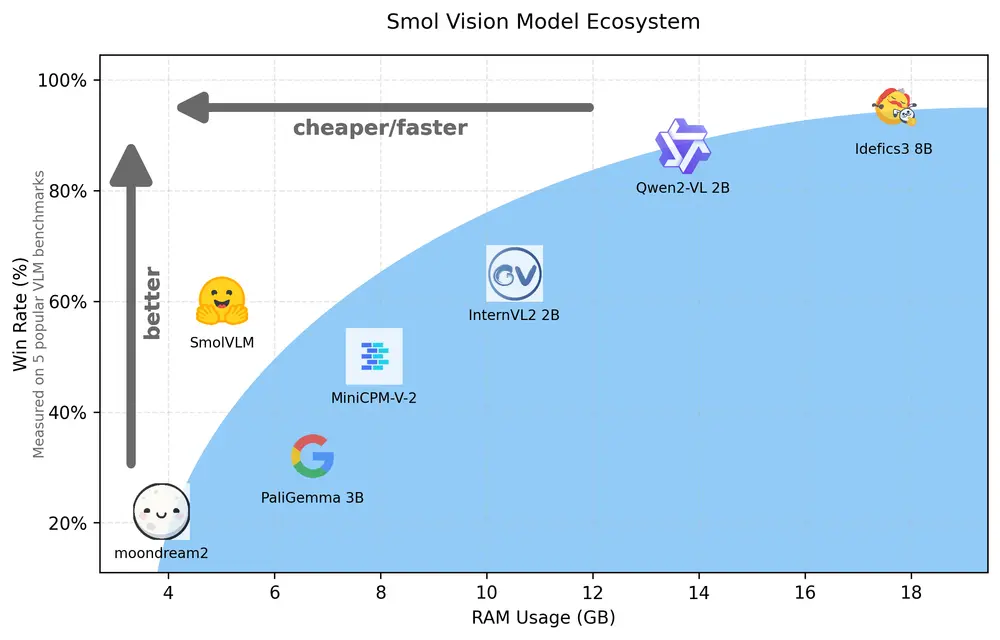
技术细节
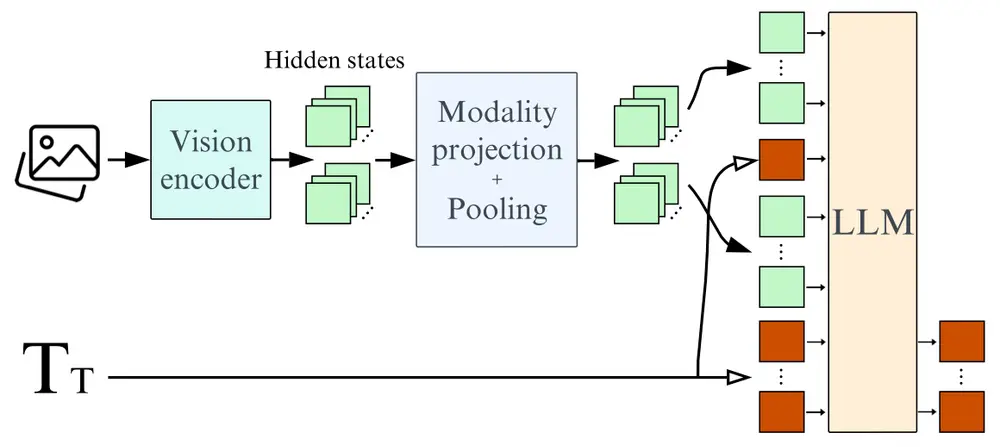
架构优化
- 语言骨干:SmolVLM的语言骨干由Llama 3.1 8B更换为SmolLM2 1.7B,这使得模型更加轻量化。
- 图像编码:SmolVLM采用了更强大的图像压缩技术,包括像素混合(pixel shuffle)策略和更大的patch,以提高编码效率和推论速度,同时减少内存占用。
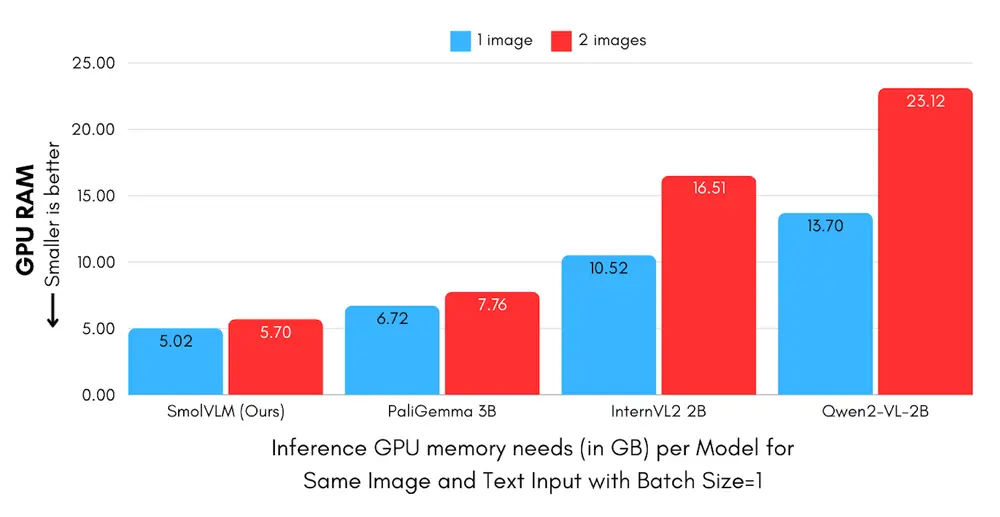
性能优势
- 预填充吞吐量:SmolVLM的预填充吞吐量比Qwen2-VL快3.3到4.5倍。
- 生成吞吐量:SmolVLM的生成吞吐量比Qwen2-VL快7.5到16倍。
- 内存效率:SmolVLM在处理多模态任务时,能够更有效地利用GPU内存,避免了设备过载的问题。
测试与评估
多模态理解:SmolVLM在多模态理解任务中表现出色,特别是在处理图像描述和问答任务时。
基准测试:SmolVLM在CinePile基准测试中得分27.14%,介于两个更资源密集型的模型InternVL2(2B)和Video LlaVa(7B)之间。尽管SmolVLM未在视频数据上进行训练,但其表现与专门为这些任务设计的模型相当。
资源效率:SmolVLM在GPU RAM使用效率方面超过了大多数同规模模型,包括InternVL2、PaliGemma、MM1.5、moondream和MiniCPM-V-2。
开源与社区支持
Hugging Face不仅发布了SmolVLM模型,还提供了三个不同版本的模型检查点:
- SmolVLM-Base:可供微调的基础模型。
- SmolVLM-Synthetic:使用合成数据集微调的版本。
- SmolVLM Instruct:经过指令微调的版本,适合终端用户互动使用。
所有模型检查点、训练数据集、训练方法及工具均以Apache 2.0授权开源,鼓励社区参与和进一步开发。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...










