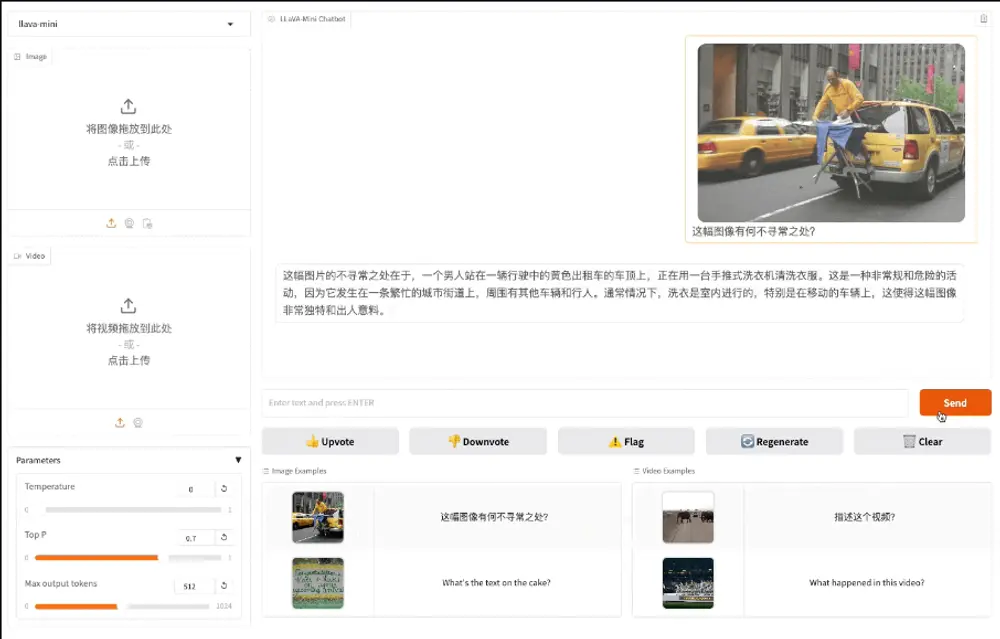
中国科学院计算技术研究所智能信息处理重点实验室(ICT/CAS)、中国科学院人工智能安全重点实验室和中国科学院大学的研究人员推出高效大型多模态模型LLaVA-Mini,旨在通过最小化视觉令牌(vision tokens)的数量来提高模型的计算效率和响应速度,同时保持对图像和视频的高质量理解能力。例如,在一个实时问答系统中,用户可以通过上传图片或视频来提问,LLaVA-Mini 能够快速理解视觉内容并生成准确的文字回答,如识别图片中的物体或解释视频中的场景变化。

- 图像理解:LLaVA-Mini 能够理解高分辨率图像中的视觉信息,包括物体识别、场景理解等。例如,在处理一张包含复杂场景的图片时,模型可以识别出图片中的主要物体及其相互关系。
- 视频理解:模型支持对视频内容的理解,能够处理长视频并捕捉视频中的动态变化和时间信息。例如,在分析一段视频时,LLaVA-Mini 可以识别视频中的关键事件和动作序列。
- 多模态交互:LLaVA-Mini 可以将视觉信息与文本指令相结合,实现多模态交互任务。例如,用户可以通过输入文本指令来引导模型对图像或视频进行特定的分析或生成特定的回答。
- 极简视觉令牌:LLaVA-Mini 将每张图像的视觉令牌压缩到仅一个,显著减少了输入到大型语言模型(LLM)的令牌数量,从而大幅降低了计算复杂度和内存消耗。
- 模态预融合:通过在 LLM 处理之前将视觉信息与文本信息进行预融合,LLaVA-Mini 保留了更多的视觉信息,避免了在压缩过程中丢失关键细节。
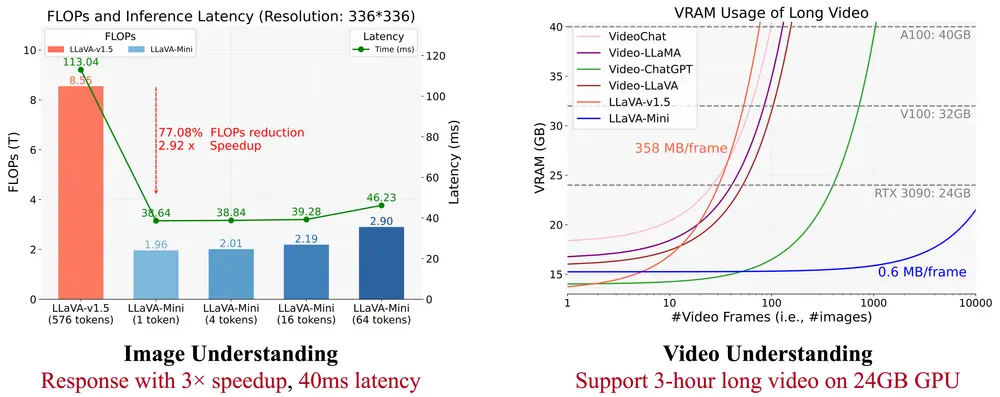
- 高效计算:模型在保持高性能的同时,显著减少了计算量(FLOPs)和响应延迟,能够在 40 毫秒内完成图像理解任务,并支持在 GPU 上处理超过 10,000 帧的视频。
- 视觉标记压缩:利用查询 - 基于的压缩模块,引入可学习的压缩查询与视觉标记进行交互,通过交叉注意力机制选择性地提取重要视觉信息,将多个视觉标记压缩为少量标记(如压缩至 1 个),同时引入 2D 正弦位置编码保留图像的空间信息。
- 模态预融合:在 LLM 前添加模态预融合模块,由多个 Transformer 块组成。该模块将视觉标记和文本标记进行拼接并处理,使文本标记提前融合相关视觉信息,弥补了压缩过程中可能的信息损失,确保模型在减少视觉标记的情况下仍能保持良好的性能。
- 模型训练:采用与 LLaVA 类似的两阶段训练过程。在视觉 - 语言预训练阶段,冻结压缩和模态预融合模块,仅训练投影模块以学习视觉和语言表示的对齐;在指令调整阶段,引入压缩和模态预融合模块,并端到端地训练除冻结的视觉编码器外的所有模块,使其能够基于极少的视觉标记执行各种视觉任务。
- 图像理解与问答:可应用于图像识别、图像内容描述、视觉问答等任务,如在智能助手、图像搜索引擎等场景中,帮助用户理解图像中的信息并回答相关问题。例如,在电商平台中,识别商品图片的细节和属性,为用户提供准确的商品信息。
- 视频理解与分析:适用于视频内容分析、视频问答、视频摘要生成等任务,如在视频监控、在线教育、视频编辑等领域,实现对视频的高效理解和处理。例如,在视频监控中,自动识别视频中的异常行为或事件,并及时发出警报。