
随着多模态大语言模型(MLLMs)的发展,扩展到单一领域之外的能力对于满足更通用和高效AI的需求至关重要。然而,之前的全模态模型在语音处理方面存在不足,忽视了其与视觉、文本等其他模态的深度整合。为了解决这一问题,香港中文大学、香港科技大学和思谋科技的研究人员提出了Lyra,这是一个高效的多模态大语言模型(MLLMs),专注于增强多模态能力,特别是高级长语音理解、声音理解、跨模态效率和无缝语音交互。Lyra通过利用多光源扩散模型来模拟不同方向的点光源照明下的图像,从而改善对物体表面法线和物理基础渲染(PBR)材料的估计。
- 项目主页:https://lyra-omni.github.io
- GitHub:https://github.com/dvlab-research/Lyra
- 模型:https://huggingface.co/zszhong/Lyra_Base_9B
- Demo:https://103.170.5.190:17860
例如,用户想要了解某个科学讲座的主要内容。用户可以提供该讲座的录音文件,Lyra能够处理长达数小时的音频内容,并生成总结性的文本摘要。例如,如果讲座是关于“恒星的演化和形成”,Lyra不仅能够识别出讲座中的关键科学概念,还能够提供关于恒星生命周期、恒星形成环境等主题的详细信息。这种能力使得Lyra在处理复杂、长时间的语音内容方面表现出色,为用户提供了一种高效获取信息的方式。
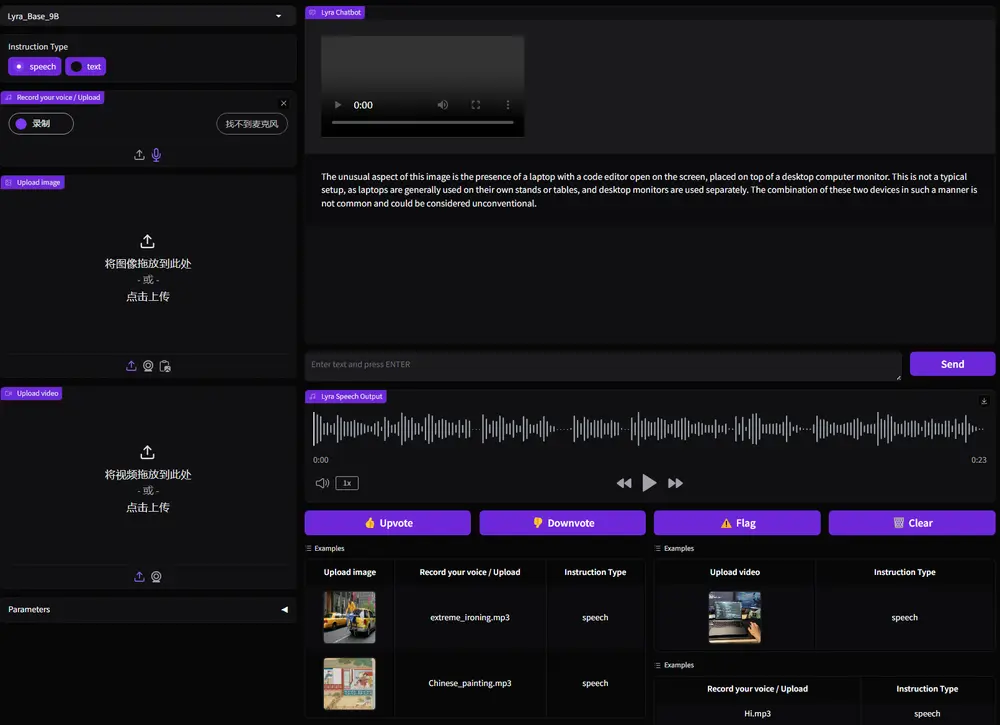
主要功能
- 语音理解与生成:Lyra能够理解和生成语音指令,处理长达数小时的语音输入。
- 视觉理解:模型可以处理和理解图像内容,与语音模态进行交互。
- 跨模态效率:通过多模态LoRA和潜在的多模态提取器,提高跨模态任务的效率。

Lyra的核心创新
1. 利用现有开源大型模型和多模态LoRA
为了减少训练成本和数据需求,Lyra采用了以下策略:
- 基于现有开源大模型:Lyra并不是从头开始训练一个新的模型,而是基于现有的开源大型语言模型(如LLaMA、Vicuna等),并在其基础上进行微调。这不仅减少了训练时间和计算资源的需求,还使得Lyra能够继承这些预训练模型的强大语言理解和生成能力。
- 多模态LoRA(Low-Rank Adaptation):研究人员提出了一种多模态LoRA技术,允许模型在不增加过多参数的情况下,适应不同模态的输入。通过仅调整模型中的一小部分参数,Lyra能够在保持高效的同时,实现对多种模态的鲁棒处理。这种低秩适配方法显著降低了训练成本和数据需求。
2. 潜在多模态正则化和提取器
为了加强语音与其他模态之间的关系,Lyra引入了潜在多模态正则化和多模态特征提取器:
- 潜在多模态正则化:通过引入一种新的正则化方法,Lyra能够在训练过程中鼓励模型学习到不同模态之间的潜在一致性。具体来说,该方法通过最小化不同模态表示之间的差异,确保模型能够更好地理解语音、图像和文本之间的关联。
- 多模态特征提取器:Lyra使用了专门设计的特征提取器,能够从语音、图像和文本中提取出高层次的语义信息,并将这些信息融合在一起。这种跨模态的信息融合使得Lyra能够在复杂的多模态任务中表现出色,例如语音-图像匹配、语音-文本翻译等。
3. 构建高质量、广泛的数据集
为了使Lyra能够处理复杂的长语音输入,并实现更强大的全认知能力,研究人员构建了一个高质量、广泛的数据集:
- 150万多个模态数据样本:Lyra的数据集包括超过150万个来自不同模态(语言、视觉、音频)的数据样本,涵盖了多种场景和任务。这些数据样本经过精心筛选和标注,确保了数据的质量和多样性。
- 12K长语音样本:特别值得一提的是,Lyra的数据集中包含了12,000多个长语音样本,这些样本长度从几秒到几分钟不等,涵盖了各种语音场景,如演讲、对话、音乐等。通过训练这些长语音样本,Lyra能够更好地理解长时间的语音输入,并生成连贯的多模态响应。
工作原理
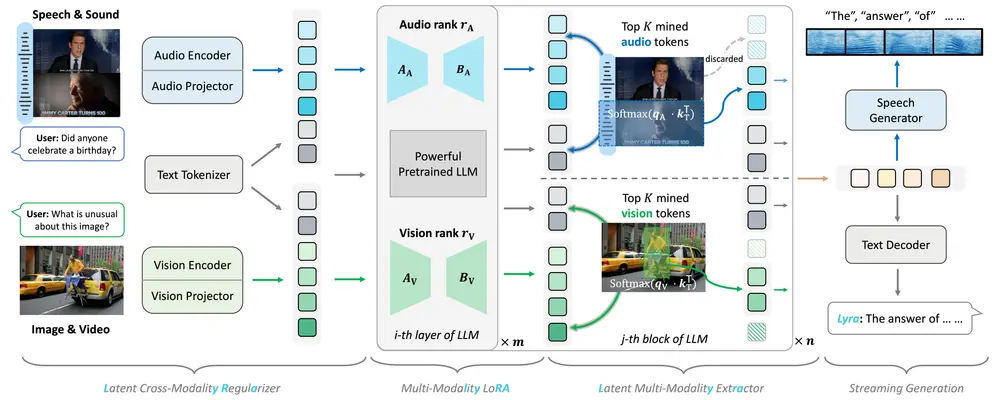
Lyra的架构由以下几个主要组件构成:
- 潜在的跨模态正则化器:通过最小化语音令牌和对应文本令牌之间的潜在距离,使得语音模态的令牌尽可能接近其转录文本。
- 多模态LoRA:通过低秩适配器有效地保留开源大型模型在特定模态中的强能力,同时发展其在语音模态中的能力。
- 潜在的多模态提取器:动态选择与文本查询相关的多模态令牌,丢弃冗余的多模态令牌,以提高训练和推理的效率。
- 长语音能力的整合:通过构建长语音SFT数据集和采用特殊的预处理方法,使模型能够处理长达数小时的语音输入。
实验结果
1. 视觉-语言、视觉-语音和语音-语言基准测试中的表现
实验结果表明,Lyra在多个视觉-语言、视觉-语音和语音-语言基准测试中达到了最先进的性能。具体来说:
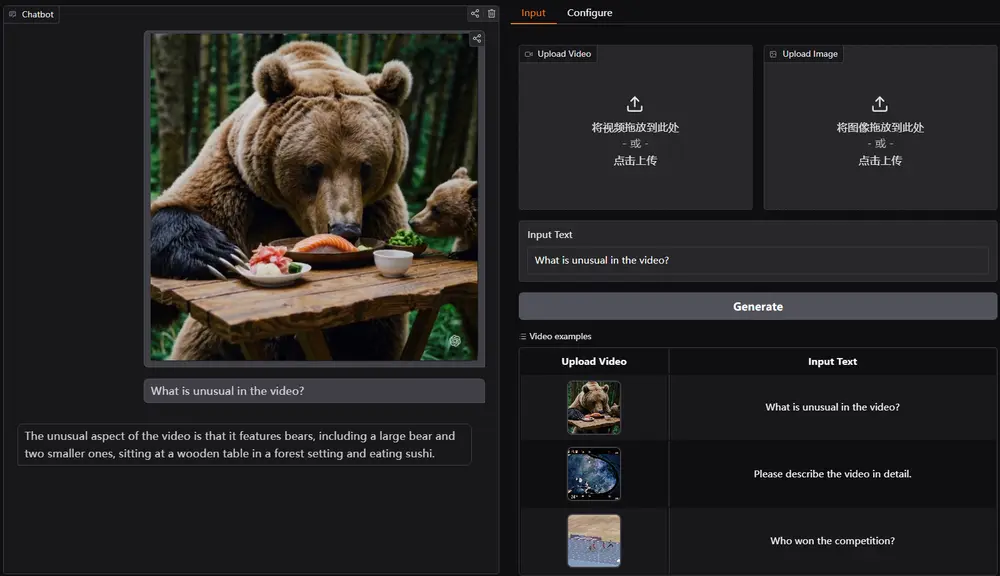
- 视觉-语言任务:在图像字幕生成、视觉问答等任务中,Lyra的表现优于现有的多模态模型,尤其是在处理复杂场景时,Lyra能够生成更加准确和自然的描述。
- 视觉-语音任务:在语音-图像匹配、语音-图像生成等任务中,Lyra展示了强大的跨模态理解能力,能够根据语音输入生成与之相关的高质量图像。
- 语音-语言任务:在语音识别、语音翻译等任务中,Lyra的表现尤为突出,特别是在处理长语音输入时,Lyra能够保持较高的准确性和流畅性。
2. 计算资源和训练数据的高效利用
尽管Lyra在多个任务中取得了卓越的性能,但它使用的计算资源和训练数据远少于其他全模态模型。具体来说:
- 计算资源:Lyra的训练过程只需要较少的GPU资源,能够在较短的时间内完成训练。
- 训练数据:Lyra使用的训练数据量仅为其他全模态模型的几分之一,但仍然能够达到甚至超越它们的性能。这得益于Lyra的多模态LoRA技术和潜在多模态正则化方法,使得模型能够在有限的数据上进行有效的学习。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











