
Nexa AI 最新发布了 OmniVision-968M,这是一款专为边缘设备设计的视觉语言模型,它通过技术创新,将图像标记数量大幅减少,显著降低了延迟和计算负担,还提升了处理速度,为边缘计算领域带来了革新。
- 模型:https://huggingface.co/NexaAIDev/omnivision-968M
- Demo:https://huggingface.co/spaces/NexaAIDev/omnivlm-dpo-demo
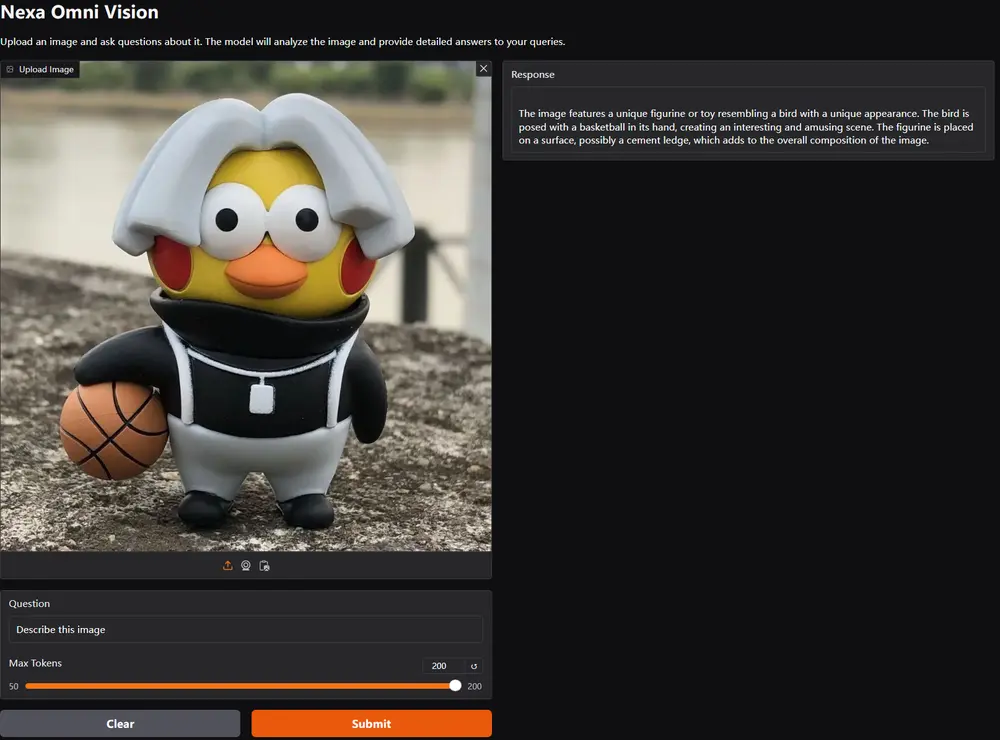
关键架构解析
基础语言模型:Qwen2.5-0.5B-Instruct,负责处理文本输入。 视觉编码器:SigLIP-400M,具有384分辨率和14×14的补丁大小,生成图像嵌入。 投影层:多层感知器(MLP),将视觉编码器的嵌入与语言模型的标记空间对齐,实现图像标记数量减少9倍。
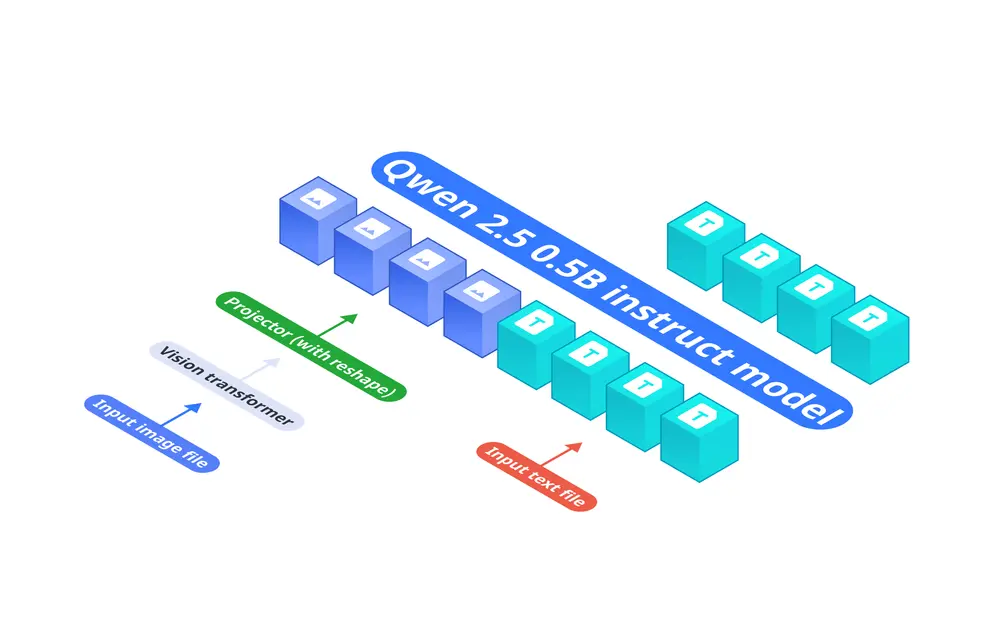
技术亮点
图像标记减少:通过将图像标记数量大幅削减,OmniVision-968M 实现了处理速度的显著提升和计算资源的有效节省。 直接偏好优化(DPO)训练:利用先进的训练方法来提高模型的准确性和可靠性,减少幻觉现象的发生。 高效的数据源利用:确保模型训练基于高质量的数据,进一步提升了模型的表现。
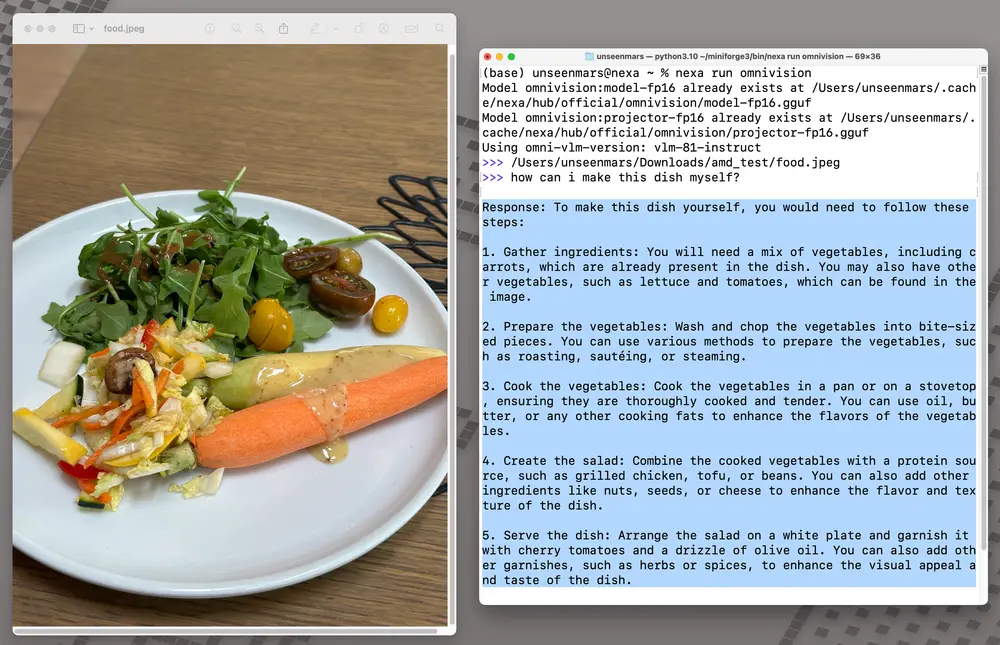
应用前景
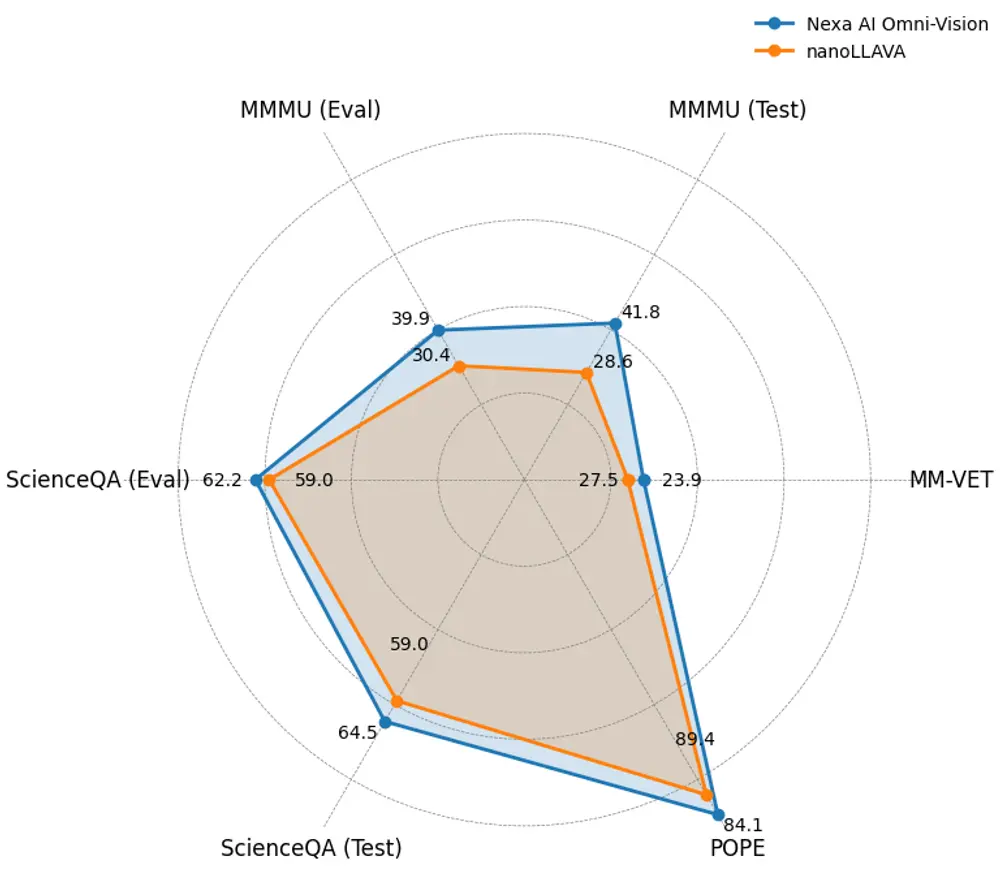
OmniVision-968M 的发布标志着几个方面的显著进步。首先,推理所需的计算资源大幅减少,这对于网络受限环境中的VLM实施尤为重要。DPO训练策略有助于最小化幻觉问题,确保模型既高效又可靠。初步基准测试显示,OmniVision-968M 在推理时间上减少了35%,同时在视觉问题回答和图像字幕等任务中保持了甚至提高了准确性。这些进步预计将推动医疗保健、智慧城市和汽车等行业的AI应用。
结语
Nexa AI 的 OmniVision-968M 解决了人工智能行业长期以来的需求:一个能够在边缘设备上无缝运行的、高度高效的视觉语言模型。通过减少图像标记、优化 LLaVA 的架构,并引入 DPO 训练以确保可信赖的输出,OmniVision-968M 代表了边缘AI的新前沿。这个模型让我们更接近于实现普遍AI的愿景——智能、连接的设备可以在本地执行复杂的多模态任务,而无需持续的云支持。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











