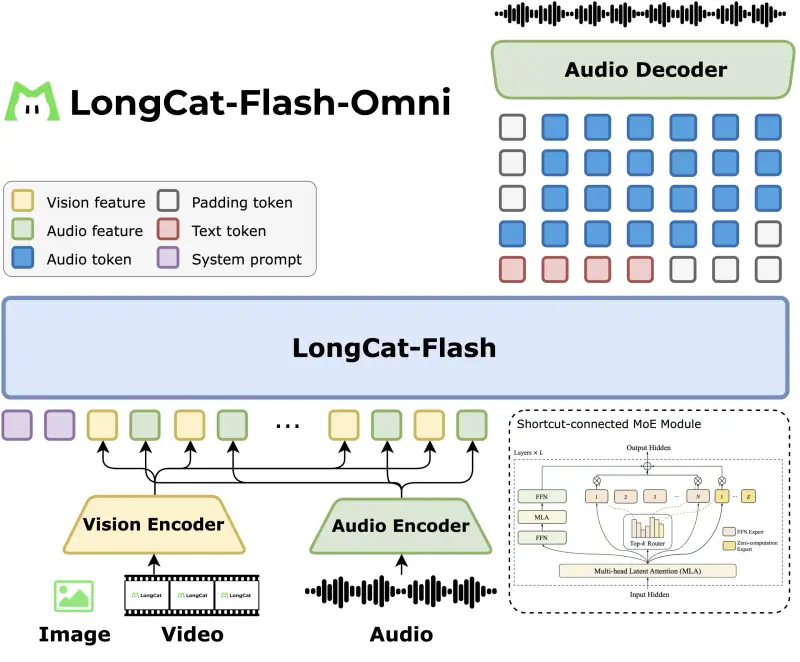
来自深度求索(DeepSeek-AI)、香港大学、清华大学和北京大学的研究人员提出了一种名为JanusFlow的创新框架,该框架将图像理解和生成统一在一个模型中。JanusFlow引入了一个极简的架构,结合了自回归语言模型和校正流(rectified flow,一种在生成建模中的最先进方法)。研究的关键发现表明,校正流可以在大语言模型框架内直接训练,而无需复杂的架构修改。(相关:深度求索推出新颖自回归框架 Janus: 具有图像生成功能的 13 亿多模态模型)
- GitHub:https://github.com/deepseek-ai/Janus
- 模型:https://huggingface.co/deepseek-ai/JanusFlow-1.3B
- Demo:https://huggingface.co/spaces/deepseek-ai/JanusFlow-1.3B
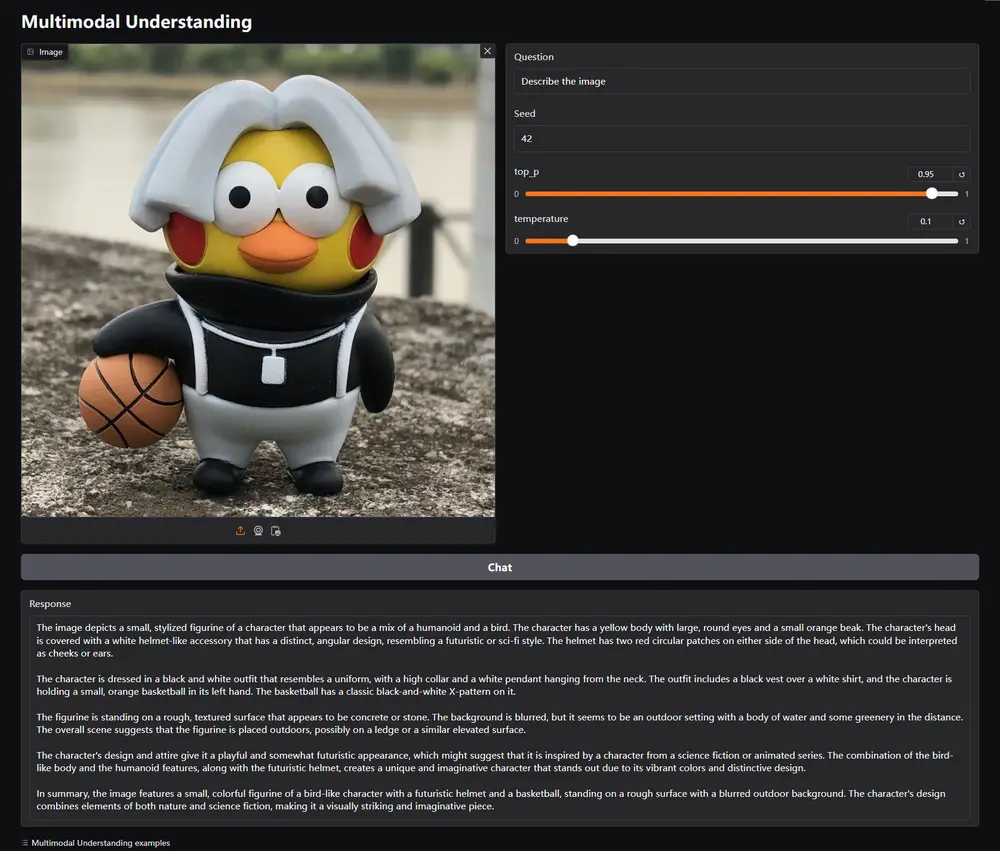
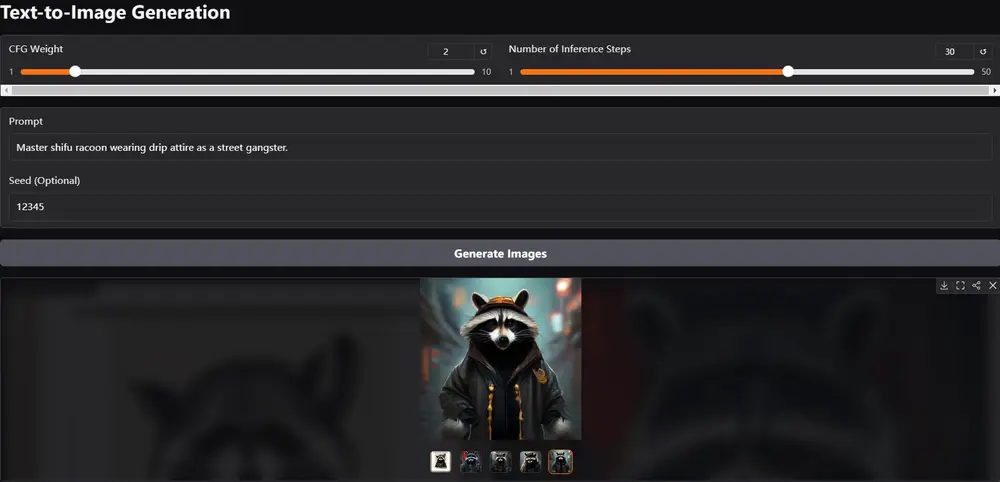
例如,用户想要生成一张图片,文本提示是“一个穿着燕尾服、带着魔法帽的男人,背景是充满活力的背景,复杂的纹理和丰富的色彩,真实风格,正面视图”。JanusFlow能够理解这个复杂的指令,并生成一张符合描述的图像。这展示了JanusFlow在理解和执行详细文本指令方面的能力。
主要功能:
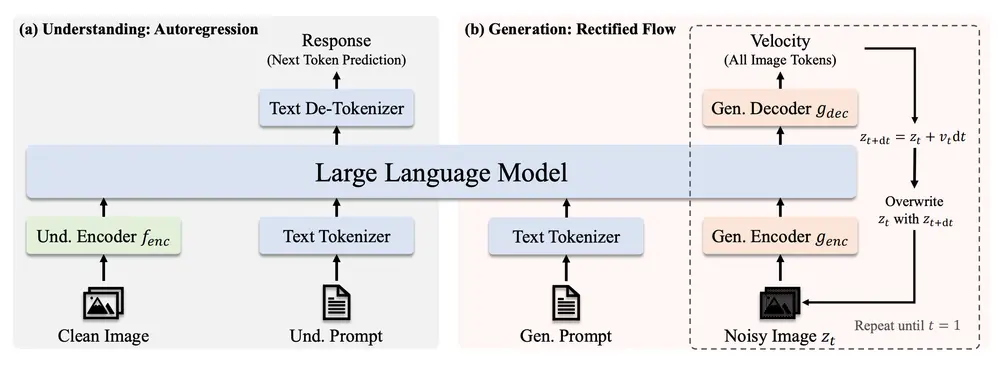
多模态理解: JanusFlow能够处理包含文本和图像数据的输入序列,并自回归地预测下一个标记,以理解和回应图像内容。 图像生成: 给定文本条件,JanusFlow能够使用校正流从高斯噪声开始迭代更新,生成相应的图像。

关键架构与策略
JanusFlow基于大语言模型(LLM),通过自回归方式处理输入序列,包括文本和图像数据。对于图像生成,模型使用校正流从噪声中逐步生成图像,通过预测速度向量来更新状态。此外,JanusFlow采用了两个关键策略:解耦理解编码器和生成编码器,以及在训练期间对齐它们的表示。
1. 极简架构
JanusFlow的核心架构包括两个主要组件:
自回归语言模型:用于处理文本生成和理解任务。 校正流:一种先进的生成建模方法,用于图像生成任务。
通过将这两个组件结合,JanusFlow能够在同一个模型中实现图像理解和生成的统一。
2. 解耦理解和生成编码器
为了进一步提高模型的性能,JanusFlow采用了两个关键策略:
解耦理解和生成编码器:通过解耦图像理解和生成的编码器,模型可以更好地专注于各自的任务,从而提高整体性能。 对齐表示:在统一训练期间对齐理解和生成编码器的表示,确保两者之间的协同作用,提高模型的整体一致性。
实验结果
广泛的实验表明,JanusFlow在其各自领域中与专用模型相比实现了可比或更优越的性能,同时在标准基准上显著优于现有的统一方法。以下是实验结果的几个亮点:
图像理解任务:JanusFlow在图像分类、物体检测等任务上表现出色,与专门的图像理解模型相比,性能相当甚至更优。 图像生成任务:在图像生成任务中,JanusFlow生成的图像质量高,细节丰富,与专门的图像生成模型相比,表现优异。 综合性能:在标准基准测试中,JanusFlow显著优于现有的统一方法,展示了其在多任务处理中的高效性和多功能性。
意义与未来展望
JanusFlow代表了向更高效和多功能的视觉-语言模型迈出的重要一步。通过将图像理解和生成统一在一个模型中,JanusFlow不仅简化了模型的架构,还提高了模型的性能和适用性。这项工作为未来的研究提供了新的方向,特别是以下几点:
模型扩展:未来可以探索将JanusFlow应用于更多任务,如视频理解和生成、多模态对话系统等。 性能优化:通过进一步优化解耦和对齐策略,可以进一步提高模型的性能和效率。 应用场景:JanusFlow在实际应用中具有广泛的应用前景,如虚拟现实、增强现实、内容创作等。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











