新上海 AI 实验室发布 InternVL-U:40 亿参数统一多模态模型,理解、推理、生成与编辑全能合一在人工智能领域,模型往往面临“专才”与“全才”的抉择:有的擅长理解图片内容,有的精于生成精美画作,但鲜有模型能同时精通“看、想、画、改”四项技能。 上海人工智能实验室正式推出 InternVL-U,一...多模态模型# InternVL-U# 上海 AI 实验室25分钟前000
新谷歌发布 Gemini Embedding 2:首个原生多模态嵌入模型,支持文本/图像/音视频统一检索谷歌今日通过 Gemini API 和 Vertex AI 正式开放 Gemini Embedding 2 的公开预览。这是谷歌首个基于 Gemini 架构构建的原生多模态嵌入模型,能够将文本、图像...多模态模型# Gemini Embedding 2# 多模态嵌入模型# 谷歌1天前080
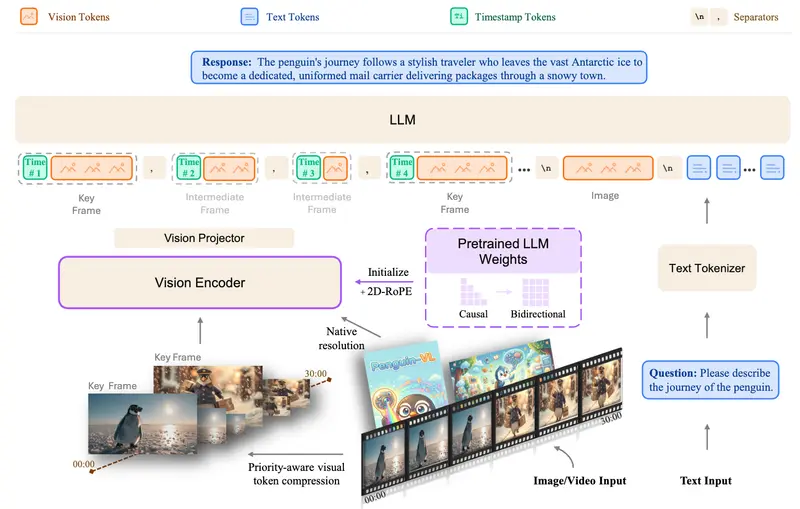
腾讯开源 Penguin-VL:抛弃 CLIP,用大语言模型初始化视觉编码器,重塑多模态效率极限“当所有人都在堆砌数据和参数时,腾讯选择了一条更本质的路:重新设计视觉编码器,让‘看’和‘想’在同一个空间里对话。” 在视觉语言模型(VLM)领域,主流范式长期依赖通过大规模对比学习(如 CLIP、S...多模态模型# Penguin-VL# Penguin-VL-2B# Penguin-VL-8B3天前0150
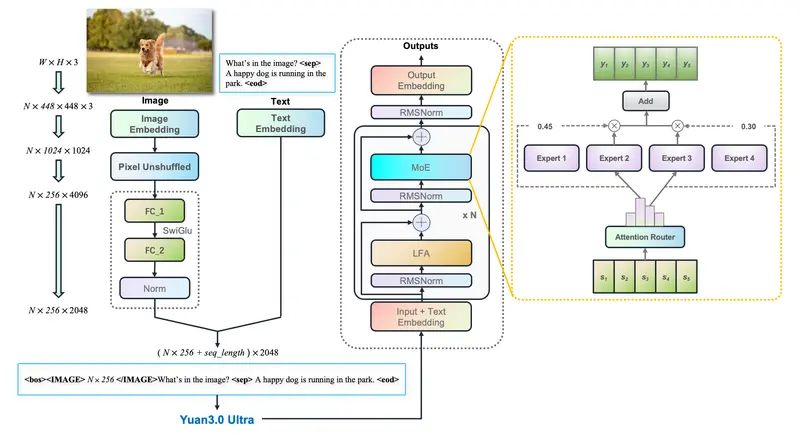
浪潮开源源 3.0 Ultra:1515B 参数巨无霸瘦身至 68B 激活,企业级 RAG 与表格理解全面超越 GPT-4o“大模型的未来不在于无限堆砌参数,而在于如何让每一分算力都产生价值。” 浪潮旗下 YuanLab.ai 团队正式开源 源 3.0 Ultra (Yuan3.0 Ultra)。这是一款从零开始预训练的超...多模态模型# Yuan3.0 Ultra# 浪潮# 源 3.0 Ultra3天前060
微软发布 Phi-4-Reasoning-Vision-15B:150 亿参数的“小而美”多模态推理专家在视觉语言模型(VLM)竞相追逐千亿参数、万亿训练词元的今天,微软反其道而行之,发布了 Phi-4-reasoning-vision-15B。 官方介绍:https://www.microsoft.c...多模态模型# Phi-4-Reasoning-Vision-15B# 微软3天前0120
OmniLottie:全球首个端到端多模态矢量动画生成器,文字/图片/视频一键转可编辑 Lottie在数字设计领域,动画是灵魂,但高质量动画的制作门槛却高不可攀。现有的 AI 视频生成工具大多输出“死视频”(MP4/GIF)——无法放大、无法修改颜色、无法提取元素。而设计师钟爱的 Lottie 矢量...多模态模型# Lottie# OmniLottie# 矢量动画1周前0350
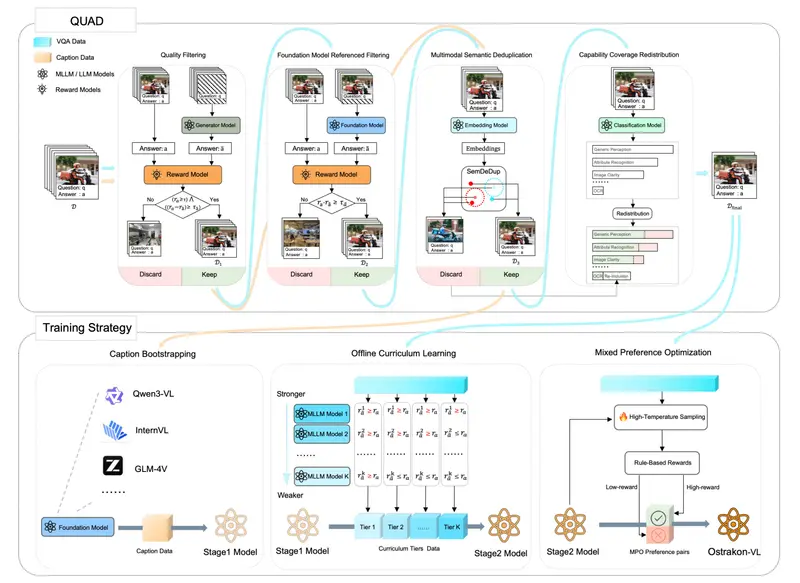
淘宝闪购开源“白泽”大模型Ostrakon-VL:基于 Qwen3-VL 打造餐饮风控神器,免费开放全行业使用在食品安全日益受到重视的今天,如何利用 AI 技术实现高效、精准的数字化治理,成为外卖平台与餐饮零售行业共同面临的挑战。今日,淘宝闪购正式宣布,将其专为餐饮服务与零售门店打造的风控治理垂直领域大模型...多模态模型# Ostrakon-VL# 淘宝闪购# 白泽2周前0250
ZUNA:开源 3.8 亿参数脑电图基础模型,支持去噪、重建与上采样脑电图(EEG)研究长期面临着一个棘手难题:信号噪声大、电极脱落导致数据缺失、以及高密度采集成本高昂。传统处理方法往往依赖复杂的数学插值或手工设计的滤波器,不仅效果有限,还难以适应多变的实际场景。 Z...多模态模型# ZUNA2周前0300
加州理工推出Conversational Image Segmentation:对话式图像分割,让 AI 真正听懂“这个稳不稳”、“那个能不能坐”在传统的计算机视觉中,AI 擅长回答“这是什么?”(分类)或“它在哪里?”(检测/分割)。如果你问它:“把左边那个红色的杯子框出来”,它能做得很好。 但如果你问:“哪个行李箱可以单独拿走而不弄倒整堆行...多模态模型# Conversational Image Segmentation# 对话式图像分割3周前0150
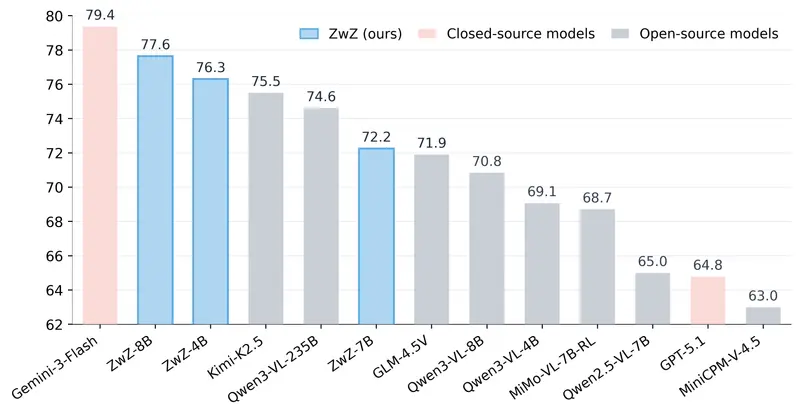
蚂蚁集团开源 ZwZ 模型:无需迭代缩放,单次 glance 实现细粒度多模态感知SOTA当前主流的“图像思考”方法,虽能通过迭代放大感兴趣区域提升细粒度感知能力,却存在致命短板——重复的工具调用与视觉重新编码,导致推理延迟居高不下,难以适配实际应用场景。 针对这一痛点,蚂蚁集团 incl...多模态模型# ZwZ# 蚂蚁集团4周前0150
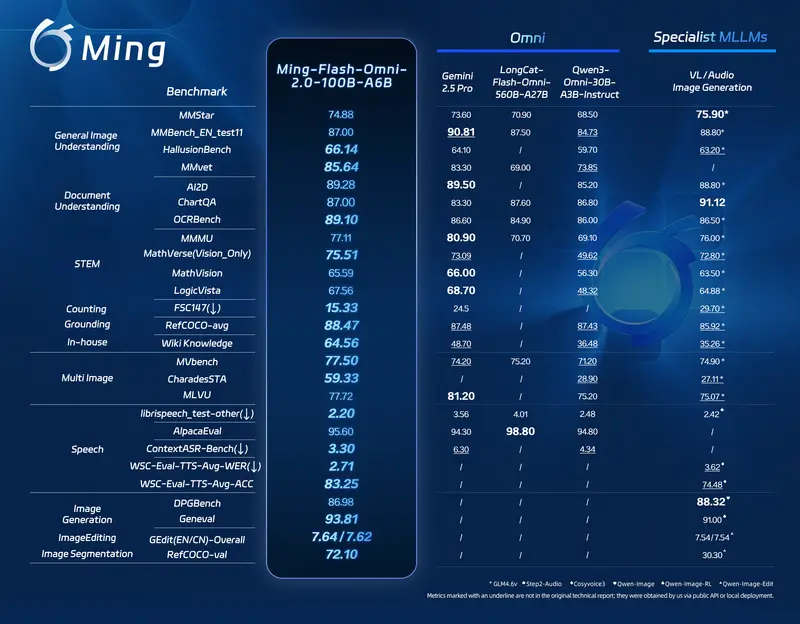
蚂蚁集团发布Ming-flash-omni 2.0 :100B MoE 多模态全能模型,支持视觉百科、沉浸式语音、高动态图像生成与编辑蚂蚁集团 inclusionAI 团队正式推出 Ming-flash-omni 2.0,搭载全新 Ling-2.0 混合专家(MoE)架构,以总参数 100B、激活参数 6B 的高效配置,在开源全能型...多模态模型# Ming-flash-omni 2.04周前080
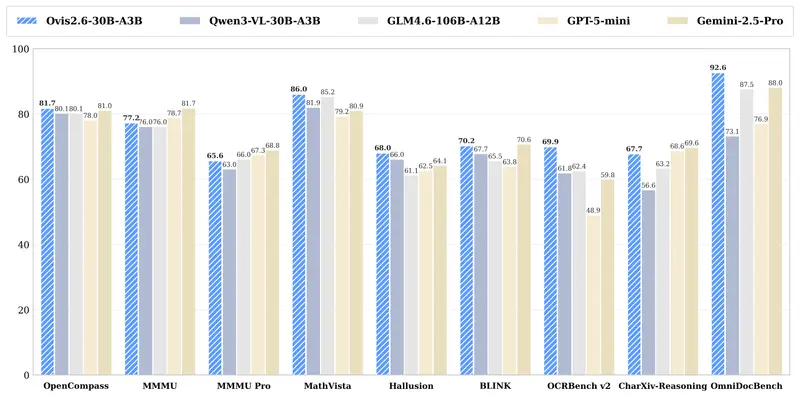
阿里国际发布 Ovis2.6-30B-A3B:MoE 架构多模态大模型,低成本实现高性能视觉理解阿里国际正式推出 Ovis2.6-30B-A3B 多模态大语言模型,作为 Ovis 系列的最新迭代版本,它在 Ovis2.5 基础上全面升级主干架构与多模态能力,以更低推理成本实现更强的长上下文、高分...多模态模型# Ovis2.6-30B-A3B# 多模态大模型4周前0130