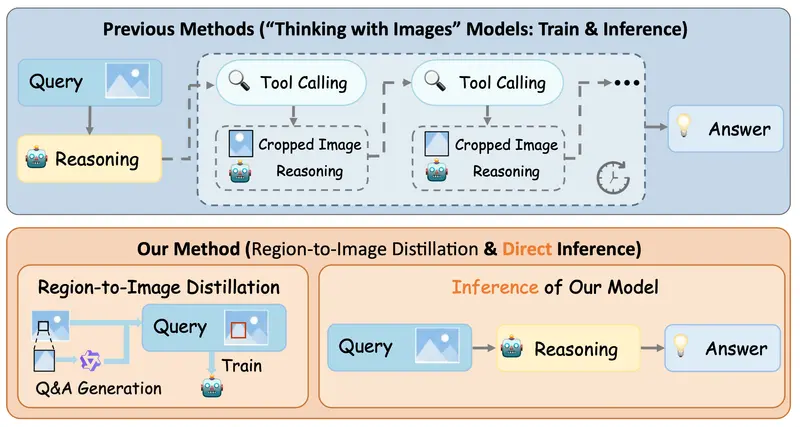
当前主流的“图像思考”方法,虽能通过迭代放大感兴趣区域提升细粒度感知能力,却存在致命短板——重复的工具调用与视觉重新编码,导致推理延迟居高不下,难以适配实际应用场景。
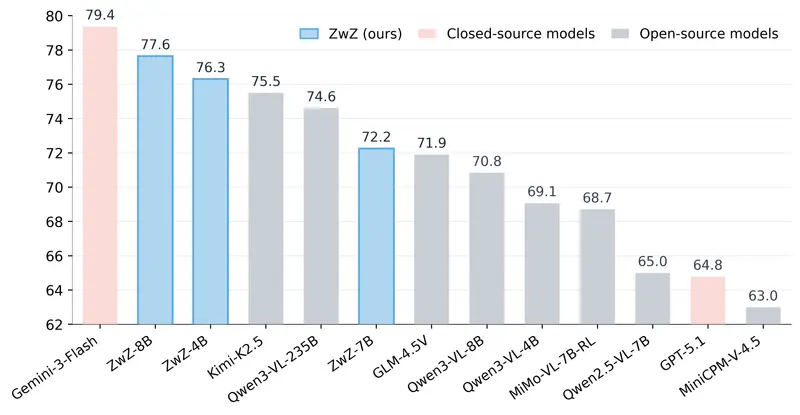
针对这一痛点,蚂蚁集团 inclusionAI 团队重磅推出 ZwZ系列模型(4B/7B/8B参数量版本),在开源多模态感知基准上实现全新最先进(SOTA)性能;同时发布 ZoomBench基准数据集,为细粒度多模态感知的评估提供了标准化、高难度的测试方案。
核心突破:“无需缩放的缩放”,彻底解决高延迟痛点
ZwZ模型的关键创新,在于提出区域到图像蒸馏技术,将“缩放”从“推理时的工具调用”,转变为“训练时的基础操作”,最终实现“无需缩放的缩放”——既保留细粒度感知精度,又彻底消除推理延迟。
其核心逻辑分为3步,简单易懂:
- 区域放大,合成高质量数据:将图像中的微裁剪区域放大,借助强大的教师模型,生成高精度的VQA(视觉问答)训练数据,捕捉细粒度特征;
- 边界框叠加,蒸馏回完整图像:将基于局部区域的监督信息,通过明确的边界框标注,蒸馏到完整图像的训练过程中;
- 单次 glance 感知:让参数量更小的学生模型(ZwZ系列),无需依赖任何推理时的缩放工具,仅通过一次前向传递,就能实现细粒度感知。
简单来说,就是“训练时把细节学透,推理时直接精准识别”,从根源上规避了重复工具调用带来的高延迟问题。
四大核心特性:精度与效率双突破
- 开源SOTA级精度:在多模态感知基准测试中,表现超越现有开源模型,拿下最先进性能,尤其在细粒度识别任务上优势显著;
- 极致推理效率:无需迭代缩放、无需工具调用,仅需一次前向传递即可完成推理,彻底消除推理时的额外开销,适配低延迟场景;
- 泛化能力出众:不仅在感知基准上表现优异,还能显著提升视觉推理、GUI智能体、AIGC检测等任务的分布外泛化能力,适配更多复杂场景;
- 配套ZoomBench基准:推出专属评估基准,为细粒度多模态感知提供标准化测试方案,填补行业空白。
模型与数据集:开源可获取,测试更精准
1. ZwZ系列模型(全开源)
模型基于Qwen系列VL模型优化,提供3个参数量版本,可按需选择部署,均已在Hugging Face开源下载:
| 模型名称 | 基础模型 | 下载链接 |
|---|---|---|
| ZwZ-4B | Qwen3-VL-4B | 🤗inclusionAI/ZwZ-4B |
| ZwZ-7B | Qwen2.5-VL-7B | 🤗 inclusionAI/ZwZ-7B |
| ZwZ-8B | Qwen3-VL-8B | 🤗 inclusionAI/ZwZ-8B |
2. ZoomBench基准数据集
配套推出的ZoomBench,是一个专注于细粒度多模态感知的挑战性基准,已在Hugging Face开源(inclusionAI/ZoomBench),核心特点如下:
- 规模与维度:包含845个高质量VQA样本,覆盖6个核心细粒度感知维度——细粒度计数、OCR文本/符号识别、颜色属性、结构属性、材质属性、物体识别;
- 双视角评估协议:每个样本同时提供完整图像和裁剪区域,可量化“全局-区域”的“缩放差距”,精准评估模型细粒度感知能力;
- 高可靠性:采用“Gemini-2.5-Pro生成+人工验证”的混合构建方式,确保样本质量与可扩展性;
- 高难度测试:现有主流模型(如Qwen2.5-VL-7B)在该基准上的平均准确率仅为42.5%,能有效区分模型的细粒度感知实力;
- 可解释性支持:配套注意力图分析,可评估模型预测是否基于任务相关的图像区域,助力模型优化。
核心价值:让细粒度多模态感知落地更简单
ZwZ系列模型的推出,打破了“细粒度感知=高延迟”的固有认知——通过训练方式的创新,让小参数量模型也能实现高精度、高效率的细粒度感知,无需复杂工具部署,大幅降低多模态感知技术的落地门槛。
无论是工业场景的细微缺陷检测、日常场景的精准图像识别,还是AI智能体的视觉感知、AIGC内容的精准检测,ZwZ模型都能适配,再加上开源可获取的特性,将加速细粒度多模态感知技术的普及与应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











