大语言模型(LLM)在开放域问答、信息检索等任务中展现出强大潜力。然而,面对需要多步骤推理、工具调用和外部验证的复杂任务,仅靠模型的静态知识和简单提示工程往往力不从心。
现有方法如检索增强生成(RAG)或基于结果的强化学习(RL),虽然能在一定程度上提升性能,但仍面临三大瓶颈:
- 推理过程不可控:无法监督中间步骤的质量
- 奖励稀疏:只有最终答案正确才给奖励,难以指导过程优化
- 梯度冲突:错误答案会反向惩罚整个推理链,导致训练不稳定
为解决这些问题,蚂蚁集团研究团队提出 Atom-Searcher —— 一种全新的强化学习框架,专注于优化推理过程本身,而不仅仅是追求最终答案。
它不依赖“黑箱式”的长篇思考,而是将复杂任务拆解为一系列可评估、可干预的“原子化思想”单元,并通过细粒度奖励机制引导模型逐步构建高质量的推理路径。
核心突破:两大创新破解传统技术痛点
Atom-Searcher的优势源于对“推理过程”的深度优化,而非仅关注最终结果,其核心创新集中在两大方向:
1. 原子化思想:让LLMs的推理更透明、可扩展
传统LLMs生成的推理内容多为单一“大块思想”,既难以解释,也无法灵活适配复杂任务。Atom-Searcher提出的“原子化思想”范式,将推理过程拆解为(观察)、(假设检验)、(风险分析)等细粒度功能单元,带来三大价值:
- 类人推理:分步思考模式更贴近人类解决问题的逻辑,推理过程更易理解;
- 资源可扩展:测试时可根据任务复杂度,灵活调配计算资源,应对更复杂查询;
- 监督锚点:为推理奖励模型(RRM)提供明确的评估对象,让深度研究任务与奖励机制精准对接。
2. 过程监督强化学习:解决奖励稀疏与梯度冲突
基于结果的强化学习(RL)常因“最终答案错误而惩罚整个推理链”,导致奖励稀疏(有效反馈少)、梯度冲突(错误定位难)。Atom-Searcher通过三层设计破解这一问题:
- 细粒度奖励(ATR):RRM为每个原子化思想独立打分,提供密集的过程级反馈,避免“一错全罚”;
- 课程式奖励策略:动态调整过程奖励(ATR)与结果奖励的权重——初期重过程、后期重结果,匹配智能体学习节奏;
- 高效优化:混合奖励结构让有效反馈更密集,梯度冲突更缓和,大幅提升策略优化效率。
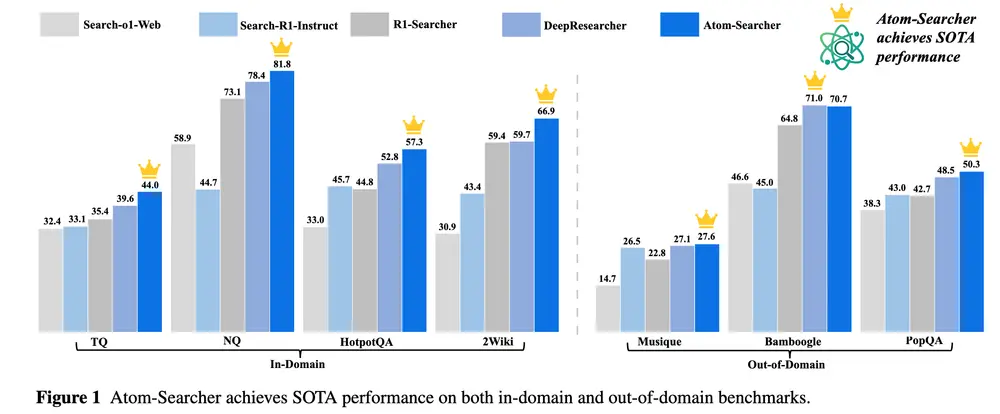
性能验证:7大基准测试斩获6个SOTA
为验证Atom-Searcher的有效性,研究团队在7个开放域问答(QA)基准测试集(NQ、TQ、HotpotQA、2Wiki、Musique、Bamboogle、PopQA)中,与基于提示(如Search-al-Web)、基于训练(如R1-Searcher、DeepResearcher)的主流模型展开对比,所有结果均以F1分数衡量。
1. 主实验:6个数据集刷新SOTA
从下表可见,Atom-Searcher在7个基准测试中的6个(除Bamboogle外)均取得最优成绩,整体性能显著超越现有模型:
| 类型 | 方法 | NQ | TQ | HotpotQA | 2Wiki | Musique | Bamboogle | PopQA |
|---|---|---|---|---|---|---|---|---|
| 基于提示 | Search-al-Web | 32.4 | 58.9 | 33.0 | 30.9 | 14.7 | 46.6 | 38.3 |
| 基于训练 | Search-R1-Instruct | 33.1 | 44.7 | 45.7 | 43.4 | 26.5 | 45.0 | 43.0 |
| R1-Searcher | 35.4 | 73.1 | 44.8 | 59.4 | 22.8 | 64.8 | 42.7 | |
| DeepResearcher | 39.6 | 78.4 | 52.8 | 59.7 | 27.1 | 71.0 | 48.5 | |
| Atom-Searcher(本文) | 44.0 | 81.8 | 57.3 | 66.9 | 27.6 | 70.7 | 50.3 |
与此前的SOTA模型DeepResearcher相比,Atom-Searcher在域内任务(如TQ、Bamboogle)平均提升8.5%,在域外任务(如NQ、PopQA)平均提升2.5%,验证了其在不同场景下的适应性。
2. 消融实验:原子化思想是性能关键
为明确各模块的作用,研究团队还进行了消融实验(移除关键模块后观察性能变化),结果显示:仅添加RRM而无原子化思想时,性能提升微乎其微;只有RRM与原子化思想结合,才能实现性能突破。
| 方法 | NQ | TQ | HotpotQA | 2Wiki | Musique | Bamboogle | PopQA |
|---|---|---|---|---|---|---|---|
| 基线 (DeepResearcher) | 39.6 | 78.4 | 52.8 | 59.7 | 27.1 | 71.0 | 48.5 |
| 基线 + RRM | 40.1 | 78.2 | 53.5 | 60.0 | 25.7 | 70.5 | 48.8 |
| Atom-Searcher(基线+RRM+原子化思想) | 44.0 | 81.8 | 57.3 | 66.9 | 27.6 | 70.7 | 50.3 |
为LLMs深度研究提供新范式
Atom-Searcher通过“原子化思想”与“过程监督强化学习”的结合,不仅解决了传统LLMs在深度研究任务中的推理不透明、训练效率低等问题,更在7大基准测试中验证了其先进性。其核心价值在于:
- 性能领先:6个数据集斩获SOTA,为LLMs深度研究树立新标杆;
- 可解释性强:分步推理模式让LLMs的思考过程更易理解、便于调试;
- 扩展性高:测试时可灵活扩展计算资源,适配更复杂的研究任务。
对于需要LLMs处理多步骤、高复杂度任务的场景(如学术研究辅助、复杂问题诊断等),Atom-Searcher提供了一套切实可行的技术方案,也为后续LLMs推理能力优化提供了新的研究方向。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











