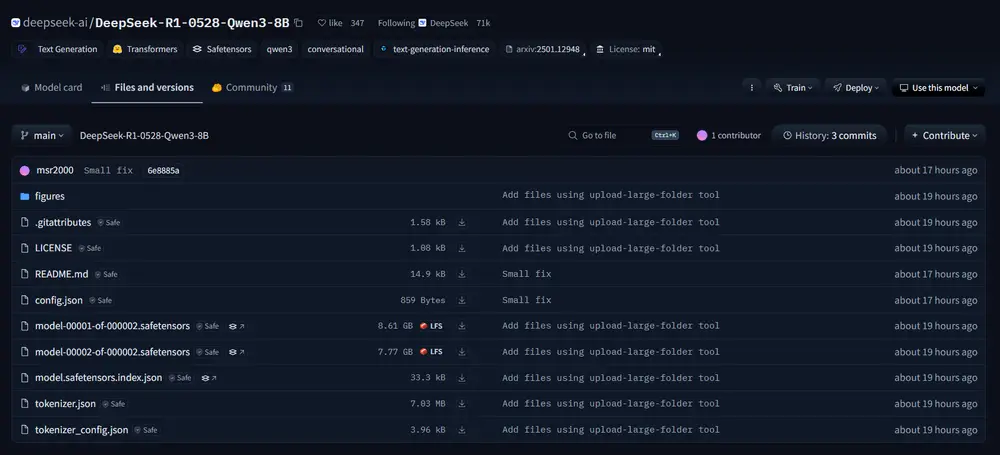
深度求索在本周对DeepSeek R1进行了升级,还开源了此版本模型DeepSeek-R1-0528,官方还推出了一个基于Qwen3-8B的小型推理模型:DeepSeek-R1-0528-Qwen3-8B。这款模型虽小,却在多个数学推理测试中表现亮眼。
1. 模型背景与性能亮点
这款模型是基于阿里巴巴于5月发布的Qwen3-8B进行优化和微调而来。虽然体积远小于完整版的R1模型,但在一些关键基准测试中,它的表现甚至超过了同级别竞品。
例如,在2025年AIME(美国高中数学邀请赛)的数据集上,DeepSeek-R1-0528-Qwen3-8B的表现优于谷歌的Gemini 2.5 Flash。而在另一项更具挑战性的数学竞赛测试HMMT中,它的成绩也接近微软最新推出的Phi 4推理增强模型。
2. 小模型的优势:轻量与高效
尽管这类精简模型通常在能力上限上无法与大模型相比,但它们的最大优势在于计算资源需求低,更适合部署在资源有限的环境或边缘设备中。
根据云平台NodeShift提供的数据:
- Qwen3-8B可在约40GB–80GB GPU内存下运行(如NVIDIA H100);
- 而完整的R1模型则需要十几块80GB的GPU才能流畅运行。
这意味着,对于中小型开发者或研究者来说,使用DeepSeek-R1-0528-Qwen3-8B将更加经济、实用。
3. 训练方式与应用场景
DeepSeek团队通过使用新版R1生成的文本对Qwen3-8B进行了微调,从而提升了其推理能力。这一方法有效利用了大模型的知识迁移能力,使得小型模型也能具备更强的逻辑处理能力。
在Hugging Face上的官方页面中,DeepSeek明确表示该模型适用于以下场景:
- 推理模型的学术研究;
- 工业界中小规模模型的实际应用开发。
4. 开源许可与商业友好性
值得一提的是,该模型采用了MIT开源许可证,这意味着它可以在不设限制的情况下用于商业用途。这种开放策略无疑将进一步推动其在实际项目中的落地应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











