
DeepSeek 最新发布了其旗舰模型 DeepSeek R1 的升级版本 —— DeepSeek-R1-0528。这次更新不仅在推理深度上有了显著提升,还在幻觉控制、函数调用支持和代码生成体验等方面进行了优化,使其在多个领域表现接近当前行业领先模型如 O3 和 Gemini 2.5 Pro。
- Hugging Face:https://huggingface.co/deepseek-ai/DeepSeek-R1-0528
- 魔塔:https://www.modelscope.cn/models/deepseek-ai/DeepSeek-R1-0528
更重要的是,基于该大模型提炼出的思维链(Chain-of-Thought)还被用于训练一个轻量级模型——DeepSeek-R1-0528-Qwen3-8B,在数学推理任务中达到了开源模型中的 SOTA 水平。
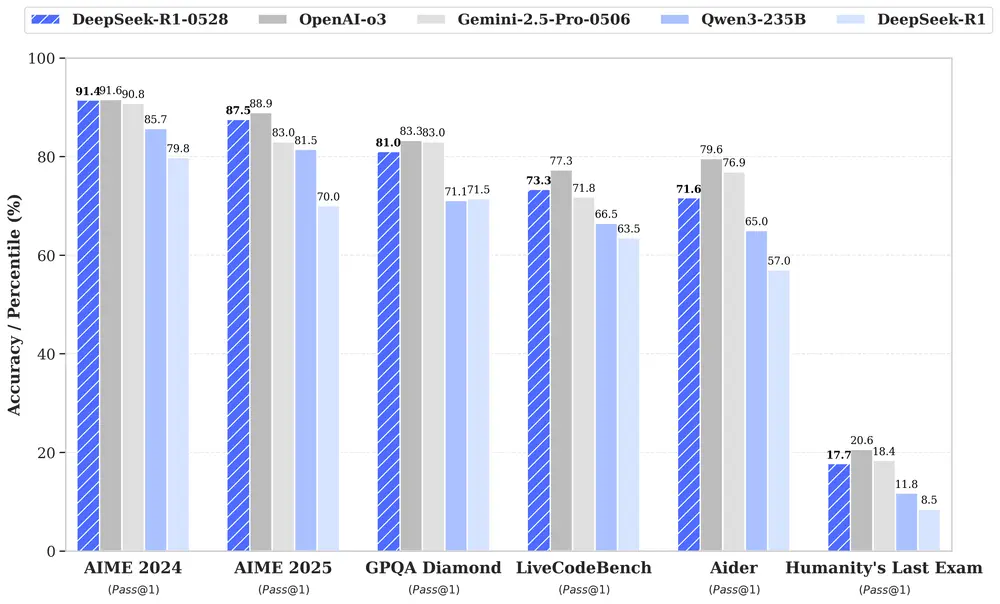
推理能力跃升:从70%到87.5%
DeepSeek R1 的核心升级体现在推理能力的大幅提升。以 AIME 2025 测试为例:
- 准确率从 70% 提高至 87.5%
- 平均每道题使用的 token 数从 12K 增加到了 23K
这说明新版本在处理复杂逻辑问题时,具备了更深层次的“思考”能力,能够通过更多中间步骤完成推理过程,从而提高最终答案的准确性。
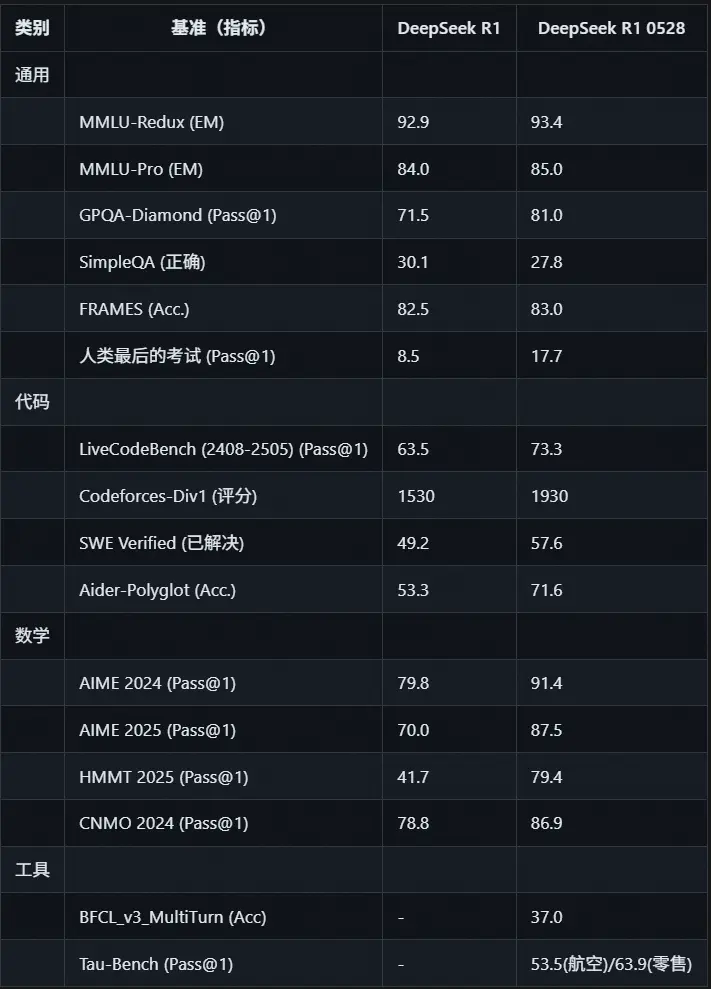
这种改进得益于两个关键因素:
- 更多计算资源的投入;
- 后训练过程中引入的算法优化机制。
不只是更强:幻觉减少 + 函数调用增强
除了推理能力的飞跃,新版本在以下几个方面也有明显进步:
✅ 幻觉现象减少
模型在回答不确定或超出知识范围的问题时,更加谨慎,减少了错误信息的输出。
✅ 函数调用支持增强
开发者可以更容易地将模型与外部系统集成,实现自动化流程、工具调用等功能。
✅ 编程与代码生成体验优化
无论是理解现有代码还是生成新代码,DeepSeek R1-0528 都表现出更高的准确性和可读性。
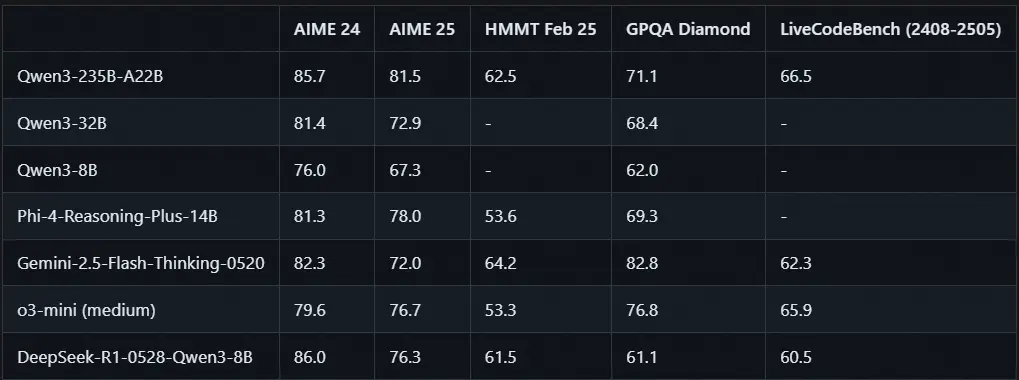
小模型也能有大作为:Qwen3-8B 版本惊艳登场
此次发布的另一个亮点是 DeepSeek-R1-0528-Qwen3-8B,这是一个基于 Qwen3-8B 构建的小型推理模型。
它通过使用新版 R1 模型生成的思维链数据进行微调,在 AIME 2024 测试中:
- 达到了开源模型中最先进水平(SOTA)
- 相比原始 Qwen3-8B,性能提升了 +10.0%
- 表现甚至接近 Qwen3-235B-thinking 的水平
这个模型虽然参数规模较小,但因其推理能力突出、资源消耗低,非常适合用于:
- 推理模型的学术研究
- 工业界中小规模模型的实际应用开发
此外,该模型采用了 MIT 开源许可证,完全支持商业用途。
使用方式 & 技术细节
🧠 如何访问 DeepSeek R1?
你可以通过以下方式体验 DeepSeek R1 的强大功能:
- 官方网站聊天界面:chat.deepseek.com(记得开启 “DeepThink” 按钮)
- API 接口服务:platform.deepseek.com(兼容 OpenAI 格式)
💻 如何本地部署?
如果你希望在本地运行该模型,可以前往官方仓库获取详细文档。以下是几个重要的配置建议:
- 支持系统提示(system prompt)
- 不再需要在输出开头添加
\n来触发思考模式 - 温度参数 T 设置为 0.6(适用于网页和应用程序环境)
- 最大生成长度为 64K token
⚙️ 模型架构说明
- DeepSeek-R1-0528-Qwen3-8B 的架构与 Qwen3-8B 相同
- 分词器配置与 DeepSeek-R1-0528 一致
- 可像 Qwen3-8B 一样部署和运行
评估方法说明
为了全面评估 DeepSeek R1 的性能,团队设定了统一的标准:
- 所有模型最大生成长度设置为 64K token
- 对于采样类任务,温度设为 0.6,top-p 设为 0.95,并为每条查询生成 16 个响应以估计 pass@1
- 使用无代理框架在 SWE-Verified 上进行评估
- 在 Tau-bench 测试中,GPT-4.1 被用来扮演用户角色
开源许可说明
DeepSeek R1 的代码仓库采用 MIT License 许可,模型本身也遵循相同的授权协议。这意味着:
- 可自由用于商业用途
- 支持模型蒸馏与二次开发
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











