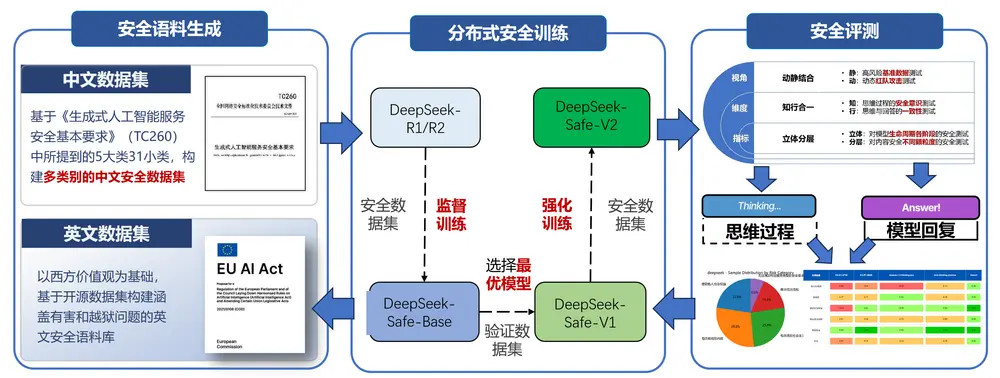
新加坡科技设计大学和清华大学的研究人员推出新型模型LongWriter-Zero,基于 Qwen 2.5-32B-Base 构建,通过强化学习(RL)从零开始训练大语言模型(LLMs),以实现超长文本生成。该模型不依赖于任何标注或合成数据,而是通过专门设计的奖励模型和训练策略,激励模型生成高质量、长篇幅的文本。
例如,LongWriter-Zero 可以生成长达数千词的连贯故事、报告或学术论文,这在以往的 LLMs 中是一个挑战。
主要功能
- 超长文本生成:能够生成超过 10,000 词的高质量文本,适用于多章节报告撰写、叙事故事创作、法律文件起草和教育内容生成等场景。
- 无需合成数据:完全从零开始训练,不依赖于任何标注或合成数据,避免了现有方法中数据构建的困难和成本。
- 强化学习驱动:通过强化学习优化模型的生成能力,使其能够更好地控制文本长度、提高写作质量和结构格式。
主要特点
- 复合奖励模型:设计了综合奖励模型,包括长度奖励、写作质量和格式奖励,以指导模型生成符合要求的文本。
- 显式推理步骤:在训练过程中引入显式的推理步骤(Think Prompt),使模型在生成最终回答前进行深入思考和规划,提高文本的连贯性和逻辑性。
- 持续预训练:在强化学习训练之前,对模型进行持续预训练,使其在长文本生成任务上达到更高的性能。
工作原理
- 强化学习框架:采用 Group Relative Policy Optimization (GRPO) 算法进行 RL 训练,通过采样多个候选输出并计算奖励来优化模型。
- 奖励设计:通过长度奖励模型(Length RM)、写作奖励模型(Writing RM)和格式奖励模型(Format RM)来评估生成文本的质量,确保文本长度合适、写作质量高且格式规范。
- 显式推理步骤:在训练和推理过程中,模型首先进行显式的推理步骤,然后生成最终回答,这有助于模型在生成过程中进行规划和反思。
- 持续预训练:在 RL 训练之前,对模型进行持续预训练,使其在长文本生成任务上具备更强的写作能力。
测试结果
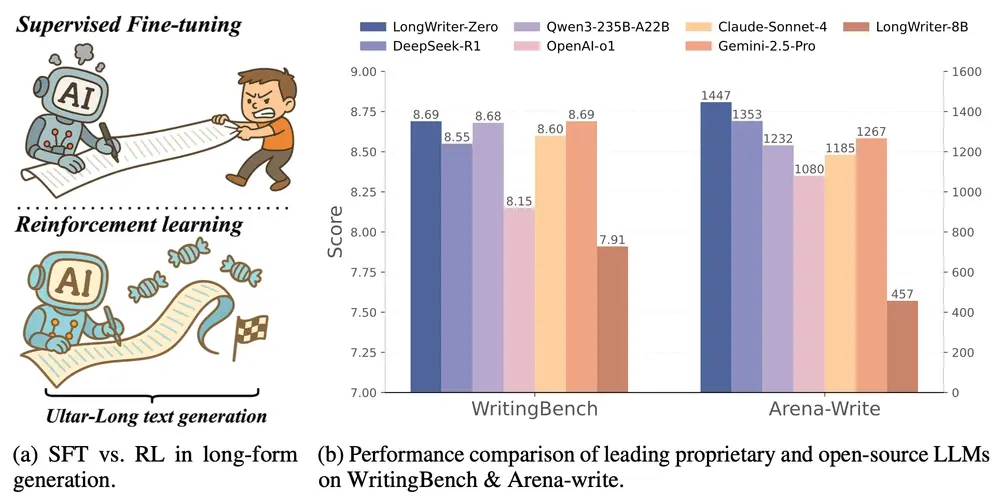
- WritingBench 基准测试:LongWriter-Zero 在 WritingBench 基准测试中取得了最高的总体评分 8.69,超越了所有其他模型,包括 Qwen-Max (8.37) 和 GPT-4o-2024-11-20 (8.16)。
- Arena-Write 基准测试:在 Arena-Write 基准测试中,LongWriter-Zero 的 Elo 评分达到了 1447,显著高于其他模型,如 DeepSeek-R1 (1343) 和 Qwen3-235B-A22B (1343)。
- 人类评估:在人类评估中,LongWriter-Zero 也表现出色,与人类评估者对文本质量的判断高度一致,验证了其在实际应用中的可靠性。
应用场景
- 创意写作:生成故事、小说、剧本等创意文本,帮助作家和内容创作者激发灵感。
- 学术写作:撰写学术论文、研究报告、文献综述等,提高学术写作的效率和质量。
- 商业写作:起草商业计划书、市场分析报告、产品说明书等,满足商业领域的长文本需求。
- 教育内容生成:创建教育材料、课程大纲、学习指南等,辅助教育工作者和学生。
- 法律文件起草:生成法律意见书、合同草案、法律分析报告等,提高法律文件的撰写效率。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











