
伊利诺伊大学厄巴纳-香槟分校、普林斯顿大学、康奈尔大学和字节跳动的研究人员推出新型轨迹感知过程奖励模型(PRM) ReasonFlux-PRM,专门用于评估大型语言模型(LLMs)在长链推理(Long Chain-of-Thought, Long-CoT)中的轨迹-响应型推理痕迹。该模型旨在解决现有PRMs在评估中间推理轨迹时的不足,特别是在处理前沿推理模型(如Deepseek-R1)生成的轨迹-响应输出时。
以数学问题解决为例,假设有一个复杂数学问题,模型需要先生成一系列中间思考步骤(轨迹),然后给出最终答案(响应)。例如,对于一个几何问题,模型可能先假设某些条件,进行计算,发现错误后回溯并重新计算,最终得出正确答案。这种中间思考过程和最终答案的结合就是轨迹-响应数据。现有PRMs在评估这种数据时存在局限性,而ReasonFlux-PRM正是为了解决这一问题而设计的。
主要功能
- 轨迹感知奖励建模:ReasonFlux-PRM能够对模型的中间思考轨迹和最终响应进行细粒度奖励分配,提供与结构化链式思考数据对齐的奖励信号。
- 多场景通用奖励监督:支持离线和在线设置,包括选择高质量模型蒸馏数据用于下游监督微调、在强化学习中提供密集过程级奖励以及在测试时进行奖励引导的最佳N选一扩展。
- 提高下游模型性能:通过提供高质量的训练数据和优化奖励信号,ReasonFlux-PRM能够显著提升下游模型在复杂推理任务上的性能。
主要特点
- 结合步级和轨迹级监督:ReasonFlux-PRM不仅考虑每个推理步骤的质量,还考虑整个推理轨迹的整体质量,确保模型的中间思考过程与最终答案一致。
- 适应多种推理模型:能够处理不同推理模型生成的轨迹-响应数据,如Deepseek-R1和Gemini Flash Thinking API。
- 高效资源利用:提供了1.5B和7B两种规模的模型,以适应资源受限的应用和边缘部署。
工作原理
- 奖励设计:
- 步级奖励:通过语义相似性(与最终响应的对齐)、逻辑质量(由专家模型评估)和上下文连贯性(相邻步骤的对比互信息)三个维度计算每个推理步骤的奖励。
- 轨迹级奖励:使用模板引导的方法,由专家模型从推理轨迹中提取推理模板,然后根据模板生成多个响应并评估其正确性,以此作为轨迹级奖励。
- 联合训练目标:结合步级和轨迹级奖励,通过最小化预测奖励与参考奖励之间的差异来训练ReasonFlux-PRM。
- 应用方式:
- 离线数据选择:对轨迹-响应数据对进行评分,筛选出高质量的数据用于下游模型的监督微调。
- 在线奖励建模:在强化学习中,将ReasonFlux-PRM生成的奖励信号整合到策略优化过程中,如GRPO(Group Relative Policy Optimization)。
- 测试时扩展:在推理阶段,对生成的多个候选响应进行评分,选择得分最高的响应作为最终输出。
测试结果
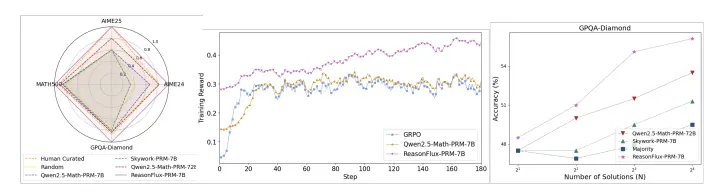
- 离线数据选择:在多个推理基准测试(如AIME、MATH500和GPQA-Diamond)中,使用ReasonFlux-PRM-7B选择的数据进行微调的模型性能优于使用人类标注数据和现有PRMs选择的数据。例如,在MATH500上,ReasonFlux-PRM-7B选择的数据使模型性能提升了6.0%,在GPQA-Diamond上提升了6.1%。
- 在线奖励建模:在强化学习中,ReasonFlux-PRM-7B作为奖励信号源时,策略模型的性能显著优于使用规则基奖励和现有PRMs的情况。例如,在Qwen2.5-7B-Instruct模型上,ReasonFlux-PRM-7B使AIME24的准确率提升了3.4%,AIME25提升了5.8%。
- 测试时扩展:在Best-of-N测试时扩展中,ReasonFlux-PRM-7B能够从多个候选响应中选择出质量最高的响应,从而提高推理性能。随着候选数量N的增加,ReasonFlux-PRM-7B的性能提升更为显著。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











