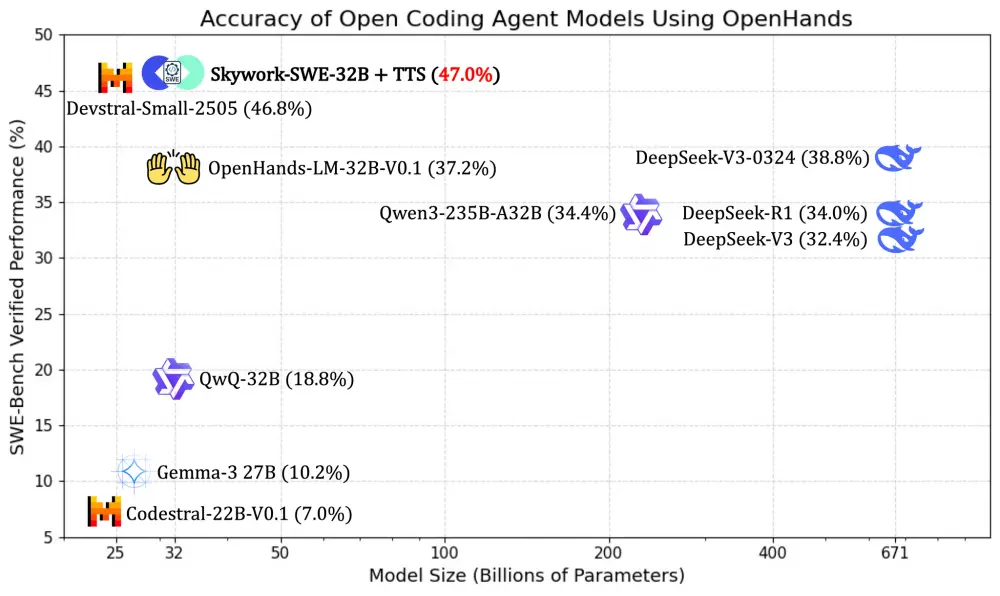
今天,昆仑万维正式宣布开源其最新推出的代码智能体 Skywork-SWE-32B,该模型专为软件工程(SWE)任务设计,在 SWE-bench Verified 基准测试中达到 38.0% 的 pass@1 准确率,并通过扩展策略进一步提升至 47.0%,成为当前同参数规模下性能最强的开源代码代理之一。
更重要的是,它让企业使用消费级显卡部署 AI 工程师成为现实,标志着开源生态在对抗闭源大模型巨头的道路上迈出关键一步。
🧠 模型亮点一览
- ✅ 高性能代码代理:在 SWE-bench Verified 中达到 38.0% pass@1,结合扩展策略可提升至 47.0%
- ✅ 高效训练数据支持:基于自动化收集构建的高质量 Skywork-SWE 数据集
- ✅ 数据扩展规律验证:训练数据越多,模型表现越强,尚未见性能饱和趋势
- ✅ 轻量化部署能力:可在消费级 GPU 上运行,显著降低部署门槛
🔬 技术核心:Skywork-SWE-32B 是什么?
Skywork-SWE-32B 是由昆仑万维开发的一种面向软件工程任务的代码代理模型,基于 Qwen2.5-Coder-32B 构建,并在 OpenHands 框架下进行了深度优化。
它不仅能够理解自然语言指令,还能执行复杂的多轮交互任务,如:
- 定位代码错误
- 修改源码文件
- 执行并验证单元测试
这一切都在模拟一个真实工程师的工作流程,是迈向“AI 工程师”落地的重要一步。
📊 性能表现:超越现有开源模型
| 模型名称 | pass@1 准确率 | 是否使用验证器/多次 rollout |
|---|---|---|
| Qwen2.5-Coder-32B(基线) | ~30.0% | 否 |
| Skywork-SWE-32B | 38.0% | 否 |
| Skywork-SWE-32B + 扩展策略 | 47.0% | 否 |
Skywork-SWE-32B 不仅超越了此前基于 OpenHands 的最佳开源模型 Qwen2.5-Coder-32B,还在不依赖验证器或多次 rollouts 的情况下达到了新的性能高峰。
📁 Skywork-SWE 数据集:支撑模型表现的核心资源
为了训练出真正具备软件工程能力的模型,昆仑万维构建了一套自动化、大规模、可执行的数据整理管道,最终生成了包含 10,169 个真实世界 Python 任务实例的 Skywork-SWE 数据集。
每个任务都配有:
- 自然语言描述的问题
- 可执行的运行时环境镜像
- 单元测试验证机制
这套数据集从 2531 个不同 GitHub 仓库中提取,经过严格的安装验证和执行测试,确保每一项任务都能被准确评估。
🔄 数据整理三阶段流程
A. 数据收集与预过滤
- 收集 GitHub 仓库元数据,排除已存在于 SWE-Bench 的项目
- 提取拉取请求(PR),筛选具有明确问题描述与修改记录的任务
- 验证项目是否可安装运行,过滤不可执行的代码片段
B. 环境设置与执行验证
- 配置运行命令,例如
pytest或unittest - 创建 Docker 镜像,标准化运行环境
- 执行前后测试,验证修复是否有效且无副作用(FAIL_TO_PASS & PASS_TO_PASS)
C. 代理轨迹生成
- 模拟 LLM 代理与环境的多轮交互
- 验证生成的修复路径是否成功解决问题
- 收集成功轨迹用于后续模型微调

📈 数据扩展规律:训练越多,表现越强
通过分析 8209 个训练轨迹,研究人员发现了一个重要现象:
随着训练数据量增加,模型在软件工程任务中的表现持续提升,未出现性能饱和迹象。
这表明,在代码生成与修复领域,数据依然是推动模型进步的关键因素。这也为未来更大规模的 SWE 数据集建设提供了理论依据。
💻 应用前景:AI 工程师离我们更近了
Skywork-SWE-32B 的发布,不仅刷新了开源代码代理模型的性能上限,也带来了实际应用层面的重大突破:
- 更低部署门槛:可在消费级显卡上运行,无需昂贵的算力资源
- 更强实用性:支持真实 GitHub 项目的代码修复与测试验证
- 更广适用性:适用于自动代码生成、CI/CD 流程辅助、开发者辅助工具等多个场景
对于中小型企业和研究团队而言,这意味着可以更快地将 AI 编程助手引入日常开发流程,提升效率,降低成本。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











