当AI模型不再一味追求“更大”,而是转向“更高效”时,小型语言模型(SLM)的时代正悄然到来。
继麻省理工学院衍生公司 Liquid AI 推出可在智能手表上运行的视觉模型、谷歌发布手机端运行的轻量级AI之后,英伟达也正式加入这场效率革命——发布全新小型语言模型 Nemotron-Nano-9B-V2。
这款仅含90亿参数的模型,在同类产品中表现领先,不仅支持多语言、代码生成和长上下文处理,还引入了一项关键能力:用户可控制其是否“思考”——即在输出答案前进行内部推理。这标志着AI从“黑箱输出”向“可控智能”迈出了重要一步。
为什么是“小模型”?
近年来,主流大语言模型(LLM)动辄拥有700亿甚至上千亿参数,虽然能力强大,但对算力和部署成本要求极高,难以在边缘设备或实时系统中落地。
而随着Mamba等新型架构的出现,以及训练方法的优化,小型模型正在逼近甚至超越部分大模型的表现,同时显著降低推理延迟与资源消耗。
Nemotron-Nano-9B-V2 正是在这一趋势下的产物。它虽名为“Nano”,但并非牺牲性能换取体积——相反,它是目前同级别模型中性能最强者之一。
📌 参数说明:模型参数是其内部可学习的权重数量,通常越多代表模型越复杂。Nemotron-Nano-9B-V2 拥有90亿参数,相较前代120亿参数缩减25%,专为单块 NVIDIA A10 GPU 优化设计。
英伟达AI模型后训练负责人 Oleksii Kuchiaev 表示:
“从120亿缩减到90亿,是为了更好地适配A10这一广泛使用的部署GPU。该模型采用混合架构,能处理更大的批次,速度比同等规模的纯Transformer模型最高快6倍。”
混合架构:Mamba + Transformer
Nemotron-Nano-9B-V2 基于 Nemotron-H 系列,这是英伟达推出的混合Mamba-Transformer架构模型家族。
传统LLM依赖纯Transformer结构,其核心是“自注意力机制”。但随着输入序列增长,计算和内存开销呈平方级上升,限制了长文本处理效率。
而Mamba架构(源自卡内基梅隆大学与普林斯顿大学的研究)引入了选择性状态空间模型(SSM),通过维护内部状态来线性处理长序列,在保持精度的同时大幅降低资源消耗。
Nemotron-H 模型将大部分注意力层替换为线性时间SSM层,在长上下文任务中实现2-3倍吞吐量提升,且准确性不打折扣。
这类架构正成为高效模型的新方向。除英伟达外,Ai2 等机构也已发布基于Mamba的模型。
可控“思考”:开启或关闭推理过程
Nemotron-Nano-9B-V2 定位为统一文本聊天与推理模型,其最大亮点在于:用户可以控制模型是否生成推理轨迹。
默认情况下,模型会在输出最终答案前,先进行“思考”——生成中间推理步骤,类似于人类解题时的草稿过程。
但你可以通过简单的控制标记切换行为:
/think:启用推理模式(输出思考过程)/no_think:禁用推理,直接返回结果
此外,模型还支持运行时“思考预算”管理——开发者可设定模型用于内部推理的最大token数量。
这一机制让系统构建者能在准确性与响应延迟之间灵活权衡,特别适用于以下场景:
- 客服机器人:需快速响应 → 关闭思考
- 自主代理(Agent):需高准确决策 → 开启思考并设置预算
- 移动端应用:资源受限 → 控制推理深度
英伟达建议,在生产环境中结合预算控制,以优化质量与性能的平衡。
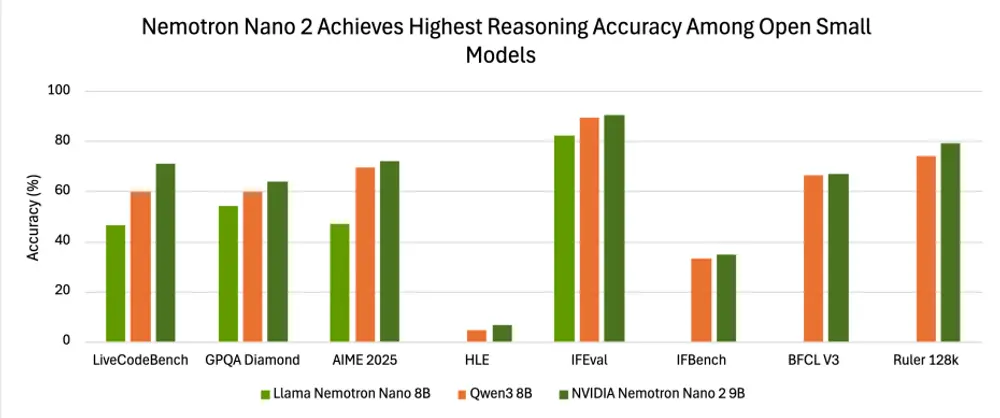
实测表现:多项基准领先
在多个权威基准测试中,Nemotron-Nano-9B-V2 展现出强劲竞争力(“推理开启”模式下):
| 基准测试 | 得分 |
|---|---|
| AIME25(数学推理) | 72.1% |
| MATH500 | 97.8% |
| GPQA(高难度问答) | 64.0% |
| LiveCodeBench(代码生成) | 71.1% |
| IFEval(指令遵循) | 90.3% |
| RULER 128K(长上下文理解) | 78.9% |
在对比中,其整体准确性超过通义千问Qwen3-8B,成为当前开源小型模型中的佼佼者。
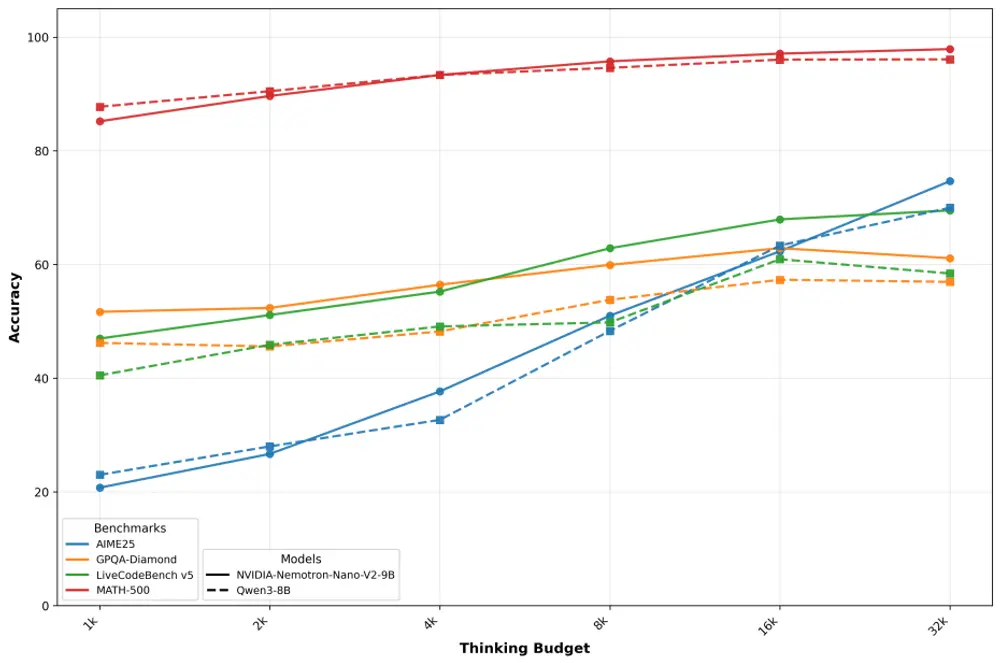
英伟达还提供了“准确性 vs 推理预算”曲线,展示随着推理token增加,性能如何逐步提升,帮助开发者合理配置资源。
训练方式:精选数据 + 合成推理增强
该模型基于高质量的混合数据集训练,包括:
- 通用文本
- 编程代码
- 数学与科学文献
- 法律与金融文档
- 对齐风格的问答数据
尤为关键的是,英伟达使用其他大型模型生成的合成推理轨迹,对训练数据进行增强,从而提升其在复杂任务上的表现。
这种“合成数据蒸馏”策略,已成为提升小模型推理能力的重要手段。
开源许可:企业友好,可直接商用
Nemotron-Nano-9B-V2 已发布于 Hugging Face 和 NVIDIA Model Registry,并采用 2025年6月更新的英伟达开放模型许可协议(NVIDIA Open Model License)。
该许可具有以下特点:
✅ 允许商业使用:可直接用于产品开发,无需额外授权
✅ 允许衍生模型:可微调、再分发,甚至构建闭源应用
✅ 无所有权主张:模型生成内容的权利归使用者所有
✅ 无分级收费:不按用户数、收入或调用量收费
这意味着企业可以零门槛将模型投入生产环境,无需担心后续授权成本。
当然,许可也包含若干责任条款:
- 🔒 安全护栏:不得绕过内置安全机制,除非提供同等替代方案
- 📄 重新分发要求:必须附带许可文本和归属声明(“由英伟达公司根据英伟达开放模型许可授权”)
- 🌍 合规义务:遵守出口管制等法律法规
- ⚖️ 可信AI原则:部署需符合负责任AI指南
- ⚠️ 诉讼自动终止条款:若起诉他人称该模型侵权,许可自动失效
这些条款聚焦于合法、安全、可追溯的使用,而非限制商业规模。
支持语言与应用场景
Nemotron-Nano-9B-V2 支持多种语言,包括:
- 英语、德语、西班牙语、法语、意大利语
- 日语、韩语、葡萄牙语、俄语、中文
适用于:
- 多语言客服系统
- 本地化内容生成
- 边缘设备上的AI助手
- 代码补全与解释
- 自主代理决策引擎
市场定位:为效率与可控性而生
英伟达推出 Nemotron-Nano-9B-V2,并非为了挑战LLaMA或GPT级别的“巨无霸”,而是瞄准一个更现实的需求:
在有限资源下,构建响应快、可解释、可控的AI系统。
它的目标用户是:
- 需要在A10等主流GPU上高效部署的开发者
- 构建低延迟客户服务系统的团队
- 开发自主Agent、工作流自动化工具的技术人员
- 希望在移动端或私有环境中运行AI的企业
通过混合架构、推理控制与企业友好的许可,英伟达正在为AI落地提供一条更务实、更可控的路径。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











