
在大模型进入“长上下文”与“超大规模参数”竞争的新阶段,如何平衡性能、训练成本与推理效率,成为决定落地能力的关键。
为此,阿里通义千问(Qwen)项目组正式推出 Qwen3-Next ——一个全新设计的高性能 MoE 架构模型系列,旨在通过系统性创新,在不牺牲质量的前提下,大幅降低训练与推理开销。
- 试用:https://chat.qwen.ai
- 官方介绍:https://qwen.ai/blog
- Hugging Face:https://huggingface.co/collections/Qwen/qwen3-next-68c25fd6838e585db8eeea9d
- 魔塔:https://modelscope.cn/collections/Qwen3-Next-c314f23bd0264a
其核心成果是:
一个总参数达800亿、但每次仅激活30亿参数的模型(Qwen3-Next-80B-A3B),
在多项任务上接近甚至超越旗舰级稠密模型,
而训练资源消耗仅为传统32B模型的9.3%,
在32k以上上下文下的推理吞吐提升超10倍。
这不仅是规模的跃升,更是一次对“性价比极限”的重新定义。
核心理念:Context Length Scaling 与 Total Parameter Scaling
Qwen 团队认为,未来大模型发展将围绕两大趋势展开:
🔹 Context Length Scaling:支持更长输入,满足复杂文档处理、代码理解等需求
🔹 Total Parameter Scaling:通过扩大总参数量增强知识容量与泛化能力
但传统架构在这两个方向上均面临瓶颈:
- 标准注意力计算复杂度随长度平方增长
- 稠密模型训练和推理成本过高
- MoE 模型易出现负载不均、训练不稳定问题
Qwen3-Next 正是在此背景下诞生的技术突破。
四大核心技术改进
1. 混合注意力机制:Gated DeltaNet + Gated Attention
为兼顾长序列建模效率与语义召回能力,Qwen3-Next 采用混合架构:
| 层类型 | 占比 | 特点 |
|---|---|---|
| Gated DeltaNet | 75% | 线性复杂度,高效处理长上下文 |
| 标准注意力(带门控) | 25% | 保留强关联建模能力 |
相比滑动窗口或 Mamba2,Gated DeltaNet 在上下文学习(in-context learning)任务中表现更优;而保留部分标准注意力层,则有效缓解了纯线性注意力在深层堆叠时的表达退化问题。
此外,还引入三项增强设计:
- 输出门控机制:缓解注意力低秩问题
- 注意力头维度从128扩展至256
- 仅对前25%位置添加旋转编码,提升外推能力
实验表明,该混合结构在多种基准测试中优于单一架构。
2. 极致稀疏 MoE:800亿参数,仅激活30亿
Qwen3-Next 采用高稀疏度 MoE 架构:
- 总参数:80B
- 每步激活参数:约3B(激活率仅3.7%)
- 专家总数:512个
- 路由专家:10个 + 1个共享专家
相比 Qwen3 的128专家配置,此次大幅扩容专家池,并优化路由策略。研究发现:
在全局负载均衡机制下,持续增加专家总量可带来训练 loss 的稳定下降。
这意味着:即使单次激活参数很少,也能通过更大的“知识库”提升模型容量与泛化能力。
3. 训练稳定性优化:让高稀疏结构“稳得住”
高稀疏 MoE 和混合注意力容易引发训练波动。为此,团队做了多项关键改进:
✅ Zero-Centered RMSNorm:替代 QK-Norm,防止某些层 norm weight 异常飙升
✅ Norm Weight Decay:避免归一化权重无界增长
✅ MoE Router 参数初始化归一化:确保每个专家在初期被公平选择,减少启动偏差
这些看似细微的设计,显著提升了训练过程的鲁棒性,也为后续强化学习阶段打下基础。
4. 多 token 预测(MTP):加速推理,提升接受率
Qwen3-Next 原生集成 Multi-Token Prediction (MTP) 机制,支持 speculative decoding,实现更快解码速度。
关键优化包括:
- 设计高接受率的 MTP 模块
- 采用“训练-推理一致”的多步预测目标
- 在实用场景中进一步提升 speculative decoding 的命中率
这使得模型在保持主干性能的同时,显著缩短生成延迟。
训练与推理效率:十倍级提升
训练效率
- 使用数据:Qwen3 36T 语料的均匀子集(15T tokens)
- 所需 GPU Hours:仅为 Qwen3-32B 的 9.3%
- 性能表现:全面超越 Qwen3-32B-Base
这意味着:用十分之一的计算资源,训练出更强的 base 模型。
推理吞吐
得益于混合架构与 MTP,Qwen3-Next 在长上下文场景下优势尤为明显:
| 上下文长度 | Prefill 吞吐提升 | Decode 吞吐提升 |
|---|---|---|
| 4k | ~7x | ~4x |
| >32k | >10x | >10x |
对于需要处理整本书、大型代码库或企业文档的应用来说,这是质的飞跃。
后训练模型表现:媲美旗舰,超越竞品
基于 Qwen3-Next-80B-A3B-Base,团队同步发布了两款后训练模型:
✅ Qwen3-Next-80B-A3B-Instruct
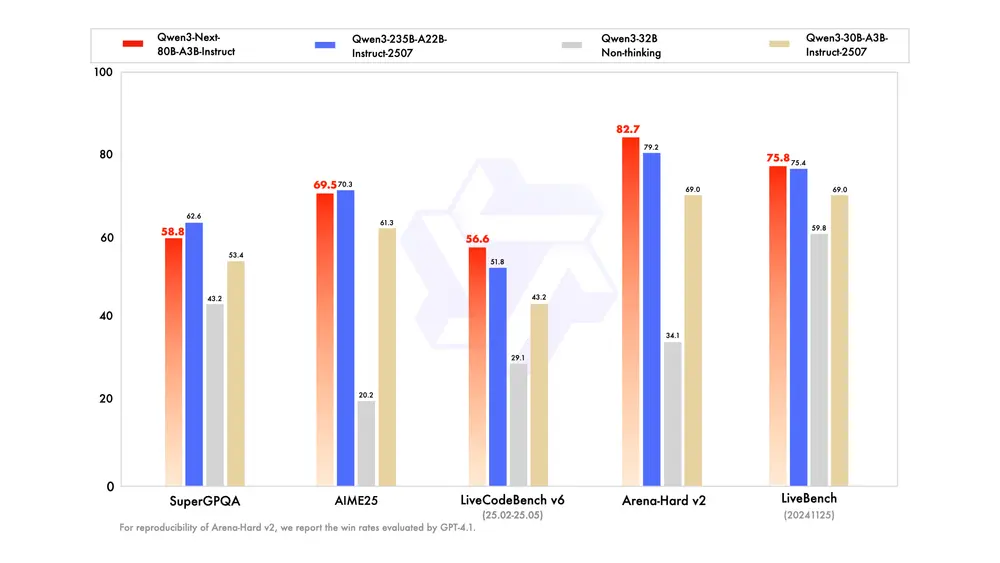
- 性能接近 Qwen3-235B-A22B-Instruct-2507(旗舰模型)
- 在 RULER 测试中,所有长度下均优于 Qwen3-30B-A3B-Instruct-2507
- 在 256K 超长上下文任务中表现突出,展现混合架构的长文本优势
✅ Qwen3-Next-80B-A3B-Thinking
- 在复杂推理任务上显著优于预训练成本更高的 Qwen3-30B-A3B-Thinking 和 Qwen3-32B-Thinking
- 超过闭源模型 Gemini-2.5-Flash-Thinking
- 部分指标已逼近 Qwen3-235B-A22B-Thinking-2507
说明该架构不仅适合通用指令跟随,也具备强大的深度推理潜力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











