
百度推出ERNIE-4.5-21B-A3B-Thinking,一款专为复杂推理任务优化的轻量级 MoE(Mixture of Experts)大模型。该模型在原有 ERNIE-4.5 基础上显著提升了推理能力,在逻辑、数学、科学、编程等任务中表现更优,同时具备高效的工具调用能力,支持联网查询、数据库访问等现实场景。
模型核心参数
| 项目 | 参数 |
|---|---|
| 模型类型 | 文本 MoE 后训练模型 |
| 总参数量 | 210 亿(21B) |
| 每 Token 激活参数 | 30 亿(3B) |
| 上下文长度 | 128K(131,072 tokens) |
| 层数 | 28 |
| 注意力头(Q/KV) | 20 / 4 |
| 文本专家(总数/激活) | 64 / 6 |
| 视觉专家(总数/激活) | 64 / 6 |
| 共享专家 | 2 |
该模型采用 稀疏激活架构,在保持高推理能力的同时控制计算开销,兼顾性能与效率。
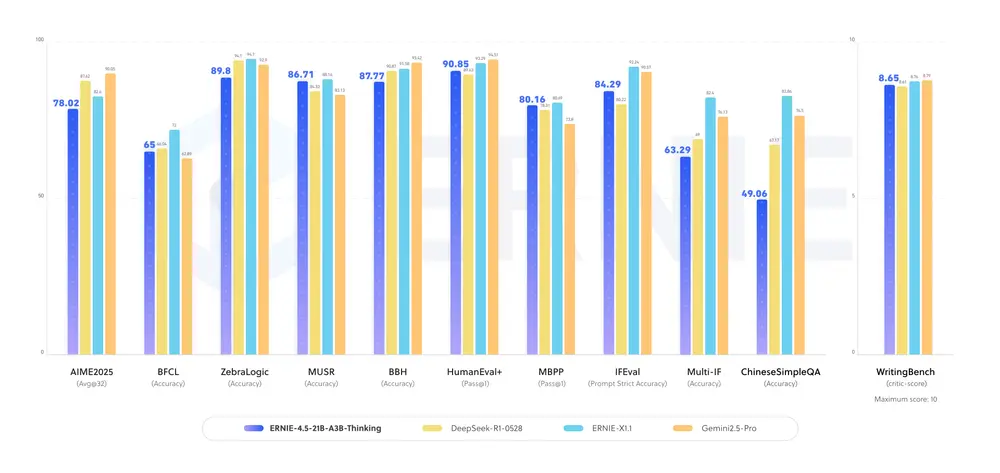
核心亮点
✅ 显著提升复杂推理能力
ERNIE-4.5-21B-A3B-Thinking 经过后训练优化,显著增强了在以下任务中的表现:
- 逻辑推理:如多步推导、因果分析
- 数学解题:支持代数、微积分、应用题求解
- 科学理解:物理、化学、生物等领域的知识推理
- 代码生成:理解复杂逻辑并生成可执行代码
- 学术任务:在需要专业知识的基准测试中表现优异
百度强调,该模型特别适用于高度复杂的推理场景,推荐在需深度思考的任务中使用。
✅ 高效工具使用能力
模型原生支持 函数调用(Function Calling),可无缝集成外部工具,实现:
- 联网查询实时信息(如天气、股价)
- 调用数据库执行 CRUD 操作
- 调用 API 完成自动化任务
这一能力使其从“纯语言模型”向“智能代理”演进,可应用于智能客服、数据分析、自动化办公等场景。
✅ 增强的长上下文理解
支持 128K 上下文长度,能够处理超长文档,如:
- 完整的技术白皮书
- 多章节小说或剧本
- 复杂法律合同
- 大型代码仓库
结合 MoE 架构,模型能在长文本中精准定位关键信息,避免信息丢失。
与前代模型的演进
ERNIE-4.5-21B-A3B-Thinking 是对 ERNIE-4.5-21B-A3B 的深度优化版本,主要改进在于:
- 增加“思考深度”:通过强化后训练,提升多步推理链的稳定性;
- 优化专家路由机制,提升任务匹配精度;
- 增强工具调用的准确性和响应速度。
尽管总参数为 21B,但因采用 MoE 架构,实际推理时仅激活 3B 参数,大幅降低计算资源消耗,适合部署在中高端 GPU 上。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











