一年前,微软推出了Phi-3,开启了小型语言模型(SLM)的新篇章。这些模型以其高效性和灵活性迅速吸引了广泛关注。如今,在 Phi 系列发布一周年之际,微软再次突破技术边界,推出了三款全新推理模型:Phi-4-reasoning、Phi-4-reasoning-plus和Phi-4-mini-reasoning。这不仅标志着小型语言模型在性能上的巨大飞跃,也为 AI 领域的未来发展提供了新的方向。
- 模型:https://huggingface.co/collections/microsoft/phi-4-677e9380e514feb5577a40e4
- GitHub:https://github.com/microsoft/PhiCookBook

推理模型:小型语言模型的新高度
推理模型是一类经过专门训练的语言模型,能够通过多步骤分解和内部反思来完成复杂任务。这类能力以往通常只存在于大型前沿模型中,而 Phi 系列通过创新的技术手段,将这种能力带入了小型语言模型领域。
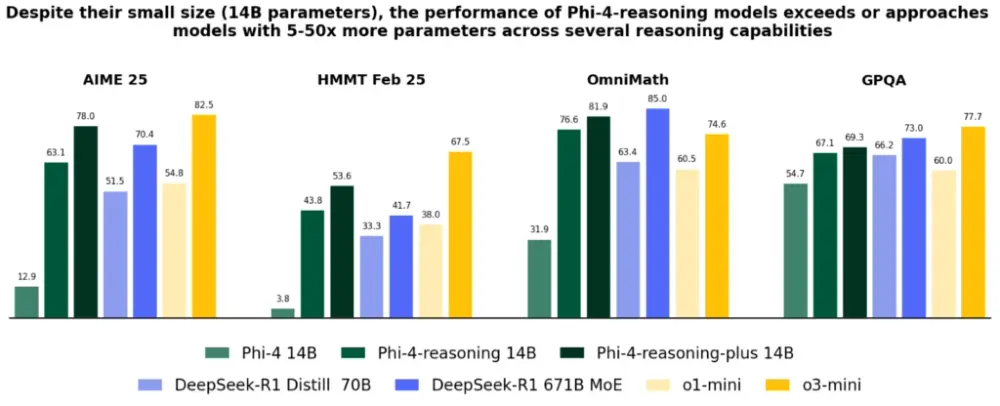
图1. 跨越数学和科学推理的代表性推理基准中的Phi-4推理性能。我们展示了通过Phi-4推理(SFT)和Phi-4推理+(SFT+RL)的推理后训练获得的性能提升,以及来自两个模型家族的代表性基线:DeepSeek的开放权重模型,包括DeepSeek R1(671B专家混合)及其蒸馏密集变体DeepSeek-R1 Distill Llama 70B,以及OpenAI的专有前沿模型o1-mini和o3-mini。Phi-4推理和Phi-4推理+始终以显著的优势超过基础模型Phi-4,超过DeepSeek-R1 Distill Llama 70B(大5倍),并展示出与更大模型(如Deepseek-R1)的竞争力。
为什么推理模型如此重要?
复杂任务处理:推理模型擅长执行需要多步骤逻辑推导的任务,例如数学推理、科学问题解答和复杂决策支持。这些能力使其成为构建智能代理应用程序的理想选择。 高效与性能的平衡:Phi 推理模型通过知识蒸馏、强化学习和高质量数据训练,在模型大小和性能之间取得了最佳平衡。它们足够轻量,可以在低延迟环境中运行,同时保持强大的推理能力。 资源受限环境的福音:这些模型非常适合边缘计算、移动设备和嵌入式系统等资源有限的场景,为开发者提供了更灵活的选择。
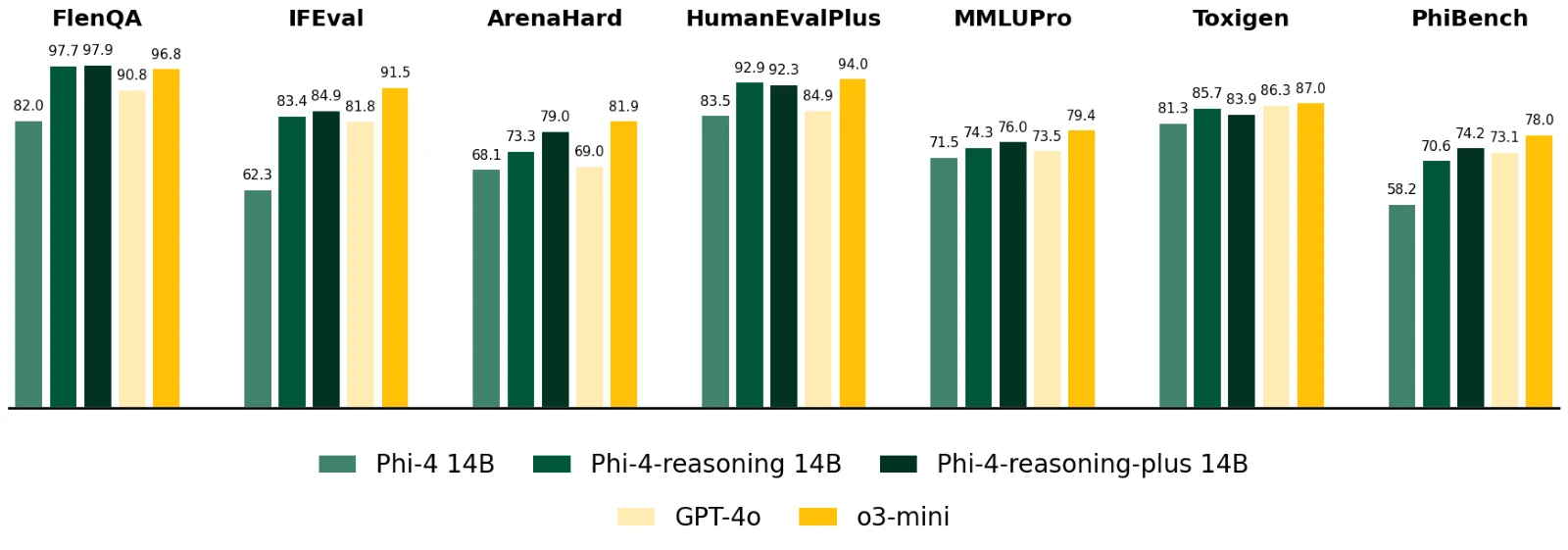
图2展示了各种通用基准测试中模型的准确性,包括长输入上下文问答(FlenQA)、指令跟随(IFEval)、编码(HumanEvalPlus)、知识和语言理解(MMLUPro)、安全检测(ToxiGen)以及其他通用技能(ArenaHard和PhiBench)。
Phi 推理模型家族详解
1. Phi-4-reasoning
参数规模:140亿参数 特点:Phi-4-reasoning 是一款高效的开放权重推理模型,能够在复杂的推理任务上与更大的模型竞争。它通过对 Phi-4 进行监督微调,并使用来自 OpenAI o3-mini 的高质量推理演示数据进行训练,生成详细的推理链,有效利用额外的推理时计算。 性能表现:在包括数学推理和博士级别科学问题在内的多项基准测试中,Phi-4-reasoning 的表现优于 OpenAI o1-mini 和 DeepSeek-R1-Distill-Llama-70B。甚至在 2025 年美国数学奥林匹克竞赛资格赛 AIME 2025 测试中,其性能超越了拥有 6710 亿参数的完整 DeepSeek-R1 模型。
2. Phi-4-reasoning-plus
特点:基于 Phi-4-reasoning,Phi-4-reasoning-plus 进一步通过强化学习进行了扩展训练,以利用更多的推理时计算。它的 token 使用量是 Phi-4-reasoning 的 1.5 倍,从而提供更高的准确性。 应用场景:适用于对精度要求极高的任务,例如科学研究、工程建模和高级数据分析。
3. Phi-4-mini-reasoning
特点:这款紧凑型推理模型专为计算或延迟受限的环境设计。通过使用 Deepseek-R1 模型生成的合成数据进行微调,Phi-4-mini-reasoning 在效率和高级推理能力之间取得了平衡。 训练数据:涵盖从中学到博士级别的超过一百万个数学问题,确保其在各种难度级别上的表现优异。 适用场景:教育应用、嵌入式辅导以及边缘设备上的轻量级部署。
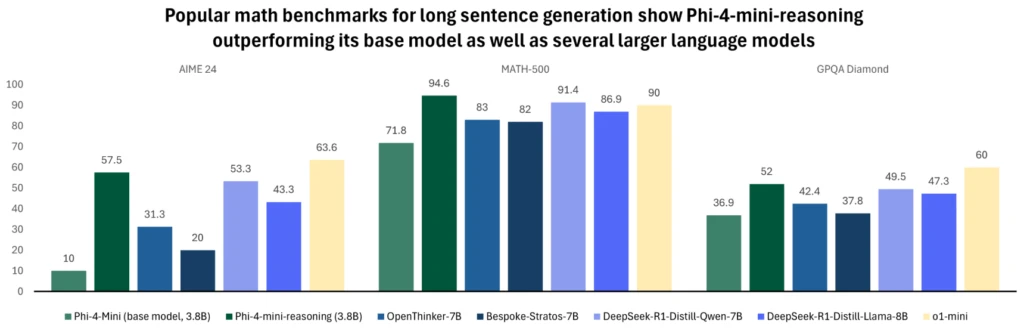
图3.该图比较了各种模型在流行数学基准上的长句生成性能。Phi-4-mini-reasoning在每个评估中都优于其基础模型和更大的模型,如OpenThinker-7B、Llama-3.2-3B-instruct、DeepSeek-R1-Distill-Qwen-7B、DeepSeek-R1-Distill-Llama-8B和Bespoke-Stratos-7B。在数学基准测试中,Phi-4-mini-reasoning与OpenAI o1-mini相当,在Math-500和GPQA Diamond评估中超越了该模型的性能。正如上图所示,具有3.8B参数的Phi-4-mini-reasoning的性能优于其两倍大小的模型。
实际应用场景:Phi 模型的落地实践
过去一年中,Phi 模型家族不断扩展,满足了不同场景的需求。以下是其在实际应用中的几个亮点:
Windows 设备上的本地运行
Phi 模型优化后可在 Windows 11 设备的 CPU 和 GPU 上本地运行,无需依赖云端资源,显著提升了响应速度和隐私保护。Copilot+ PC 的核心组件
微软推出的 Copilot+ PC 配备了针对 NPU(神经网络处理单元)优化的Phi Silica变体。这种高效版本预加载到内存中,具有极快的首个 token 响应时间和节能的 token 吞吐量,可与其他应用程序无缝协作。例如,Phi Silica 被用于Click to Do功能,为屏幕内容提供智能化文本工具。生产力应用的集成
Phi 模型已集成到多个生产力应用程序中,如 Outlook 的离线 Copilot 摘要功能。这些小巧而强大的模型为用户提供流畅的体验,同时降低了资源消耗。
安全性和负责任的 AI 方法
在开发 Phi 模型的过程中,微软始终遵循其负责任的 AI原则,包括问责性、透明度、公平性、可靠性和安全性。具体措施包括:
后训练安全方法:结合监督微调 (SFT)、直接偏好优化 (DPO) 和人类反馈强化学习 (RLHF) 技术。 多样化数据集:利用公开数据集和安全相关的问题与答案,确保模型的有用性和无害性。 模型局限性说明:微软提供了详细的模型卡片,帮助用户理解模型的潜在局限性并采取相应措施。
尽管 Phi 模型在许多任务中表现出色,但所有 AI 模型都有其局限性。微软鼓励用户在实际应用中充分了解这些限制,并根据需要调整使用方式。
未来展望:小型语言模型的无限可能
Phi 推理模型的成功证明了小型语言模型同样可以具备强大的推理能力和广泛的应用潜力。随着 AI 技术的不断发展,Phi 系列将继续推动小型高效模型的边界,为更多场景提供支持——无论是教育资源的普及、嵌入式系统的智能化,还是企业生产力的提升。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











