蚂蚁集团 百灵大模型团队近日发布 Ling 2.0 —— 一个系统性构建的 稀疏混合专家(MoE)语言模型系列,核心理念是:模型容量可无限扩展,但每个 token 的计算成本应保持恒定。该系列通过统一的“1/32 激活率”架构,在总参数从 160 亿(16B)到 1 万亿(1T)的跨度内,实现了推理效率、质量与可扩展性的高度平衡。
- GitHub:https://github.com/inclusionAI/Ling-V2
- 模型:https://huggingface.co/collections/inclusionAI/ling-v2
关键亮点
- 统一 1/32 激活 MoE 架构,从 16B 到 1T 无缝扩展;
- Ling 缩放定律 实现超参自动设计,避免试错成本;
- 推理优先训练:早期注入代码/数学,全程强化思维链;
- 全栈 FP8 优化,在现有集群上实现 1T 模型实用化;
- 效率提升 7 倍,质量随规模可预测增长。
核心设计:稀疏 MoE 与 Ling 缩放定律
Ling 2.0 系列所有模型共享同一架构原则:
- 每层包含 256 个路由专家 + 1 个共享专家;
- 路由器为每个 token 动态选择 8 个路由专家,共享专家始终激活;
- 总激活专家数 ≈ 9 / 257 ≈ 3.5%,即 1/32 激活率;
- 相比同等性能的稠密模型,训练与推理效率提升约 7 倍。
为避免“试错式”超参调优,团队提出 Ling 缩放定律(Ling Scaling Law):
- 通过“Ling 风洞”(小型 MoE 实验集群)在固定数据与路由规则下训练;
- 拟合损失、激活率、专家负载的幂律关系;
- 以低成本预测万亿级模型的最佳配置,确保从 mini 到 1T 的一致性。
三层模型矩阵:小而快,大而强
| 模型 | 总参数 | 激活参数/token | 定位 |
|---|---|---|---|
| Ling mini 2.0 | 16B | 1.4B | 轻量级推理,H20 上超 300 token/s |
| Ling flash 2.0 | ~100B | 6.1B | 中等容量,平衡性能与成本 |
| Ling 1T | 1T | ~50B | 旗舰模型,支持 128K 上下文与复杂推理 |
所有版本均保持 1/32 激活率,质量随容量可预测提升,无需重新设计架构。
全栈协同优化:从架构到基础设施
1. 模型架构
- 使用 QK Norm、MTP 损失、部分 RoPE 保证深层稳定性;
- 无辅助损失路由,采用 Sigmoid 评分,简化训练流程。
2. 预训练策略
- 20T+ token 训练数据,早期即注入数学、代码等推理密集型内容(占比近 50%);
- 中期在 150B token 切片上扩展至 32K 上下文;
- 后期注入 600B 高质量思维链(Chain-of-Thought)数据;
- 最终通过 YaRN 实现 128K 长上下文,同时保留短上下文性能。
3. 后训练对齐
- 能力通道:通过系统提示,让模型在“快速响应”与“深度推理”间切换;
- 进化思维链(Evo CoT):扩展与多样化推理路径;
- 句子级策略优化(LPO):基于组竞技场奖励,细粒度对齐人类偏好。
4. FP8 基础设施
- 原生 FP8 训练,损失曲线与 BF16 基线差距极小;
- 异构流水线并行 + 交错前向/后向 + MTP 块感知分区,带来 ~40% 加速;
- Warmup Stable Merge 技术替代传统 LR 衰减,提升训练稳定性。
性能与效率:稀疏即优势
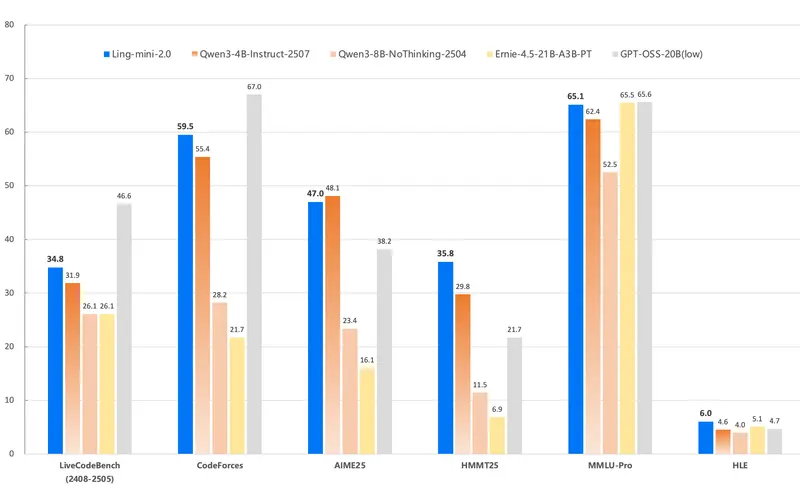
- Ling mini 2.0(16B/1.4B)性能对标 7–8B 稠密模型,但推理速度更快;
- Ling flash 2.0 在保持低激活成本下,提供更高知识容量;
- Ling 1T 在数学、代码、长上下文任务中展现 SOTA 水平,同时每个 token 计算量可控。
稀疏设计的核心价值:用“大容量”换取“高上限”,用“小激活”守住“低延迟”。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...