
在 Qwen3-2507 系列全面上线后,阿里通义实验室正式推出 Qwen3-Max——迄今为止参数规模最大、综合能力最强的 Qwen 模型。
作为 Qwen3 系列的旗舰型号,Qwen3-Max 不仅在预训练和指令微调阶段实现全面突破,在代码生成、智能体任务、高难度推理等关键场景中也达到业界领先水平。
目前,Qwen3-Max-Instruct 已开放体验,可通过 Qwen Chat 或阿里云 API 调用;仍在训练中的推理增强版 Qwen3-Max-Thinking 亦展现出惊人潜力,已在多项数学基准测试中取得满分成绩。

核心定位:从“大”到“强”的跃迁
Qwen3-Max 并非简单的规模扩展,而是一次系统性升级:
- ✅ 总参数超 1T,预训练数据达 36T tokens
- ✅ 延续 Qwen3 MoE 架构设计,支持 原生 1M 上下文长度
- ✅ 在知识理解、逻辑推理、编程、多语言、指令遵循等方面全面领先
它代表了当前国产大模型在通用智能与工程落地之间的最佳平衡点。
三大版本:满足不同使用需求
1. Qwen3-Max-Base —— 高效稳定的基座模型
作为整个系列的基础,Qwen3-Max-Base 在训练效率与稳定性上实现了显著提升:
- 📉 训练 loss 平滑稳定:全程无尖刺,未使用回退或数据重采样策略
- ⚙️ 采用自研 global-batch load balancing loss,提升 MoE 路由均衡性
- 💡 训练效率提升:
- MFU(Model FLOPs Utilization)较 Qwen2.5-Max 提升 30%
- 通过 ChunkFlow 长序列优化策略,吞吐相较传统并行方案提升 3 倍
- 🔧 故障容错增强:借助 SanityCheck、EasyCheckpoint 等机制,因硬件故障导致的时间损失仅为前代的 五分之一
这些改进使得百万级 token 的长上下文训练成为常态,而非极限挑战。
2. Qwen3-Max-Instruct —— 全能型指令模型,已开放使用
该版本针对真实应用场景进行深度优化,是目前最接近“即开即用”的顶级模型之一。
性能亮点:
| 基准测试 | 成绩 | 行业对比 |
|---|---|---|
| LMArena 文本排行榜 | 全球第3 | 超越 GPT-5-Chat |
| SWE-Bench Verified(编程能力) | 69.6 分 | 进入全球顶尖梯队 |
| Tau2-Bench(Agent 工具调用) | 74.8 分 | 超过 Claude Opus 4 和 DeepSeek-V3.1 |
SWE-Bench Verified 是目前最具挑战性的现实编程任务评测集,要求模型修复开源项目中的真实 bug。69.6 分意味着每 10 个任务可成功解决近 7 个。
此外,在多语言理解、复杂指令解析、人类偏好对齐等方面,Qwen3-Max-Instruct 同样表现卓越,适用于客服、自动化办公、研发辅助等多种高阶场景。
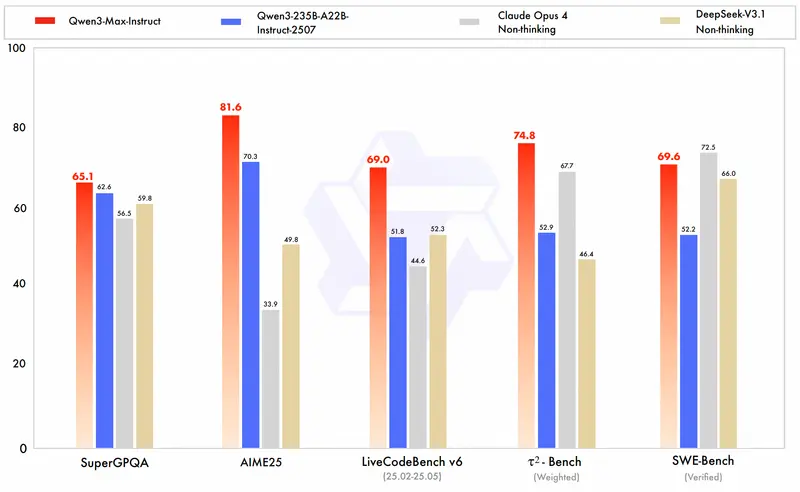
3. Qwen3-Max-Thinking —— 推理增强版,正在训练中
这是专为复杂逻辑与数学推理打造的“思考型”模型,尚未正式发布,但已有初步成果惊艳亮相:
- 结合 代码解释器 + 并行测试时计算 技术
- 在极具挑战的数学竞赛题评测中取得 100% 准确率:
- AIME 2025
- HMMT(哈佛-麻省理工数学锦标赛)
这一成绩表明,Qwen3-Max-Thinking 已具备处理高度抽象问题的能力,未来有望应用于科研建模、金融分析、算法设计等领域。
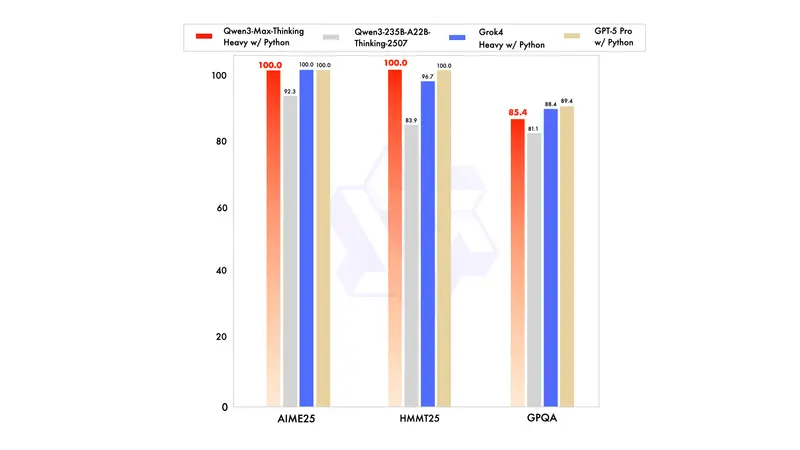
我们期待在不久的将来向公众开放该版本。
如何体验 Qwen3-Max?
目前,Qwen3-Max-Instruct 已全面开放,提供两种使用方式:
方式一:在线对话(免费试用)
访问 Qwen Chat 官网,选择 Qwen3-Max 模型,即可直接体验其强大能力。
方式二:API 接入(开发集成)
模型名称:qwen3-max
接入步骤如下:
- 注册阿里云账号
- 开通 阿里云 Model Studio 服务
- 登录控制台,创建 API Key
- 使用标准 OpenAI 兼容接口调用(无需修改代码)
✅ 完全兼容 OpenAI 格式,迁移成本极低
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











