
智谱 AI 正式推出 GLM-4.7-Flash——一款基于 30B 总参数、激活 3B(A3B)的稀疏混合专家(MoE)架构 的大语言模型。它在高性能与高效率之间取得出色平衡,成为本地部署场景下理想的编码助手与智能代理。
- 模型:http://huggingface.co/zai-org/GLM-4.7-Flash
- API:http://docs.z.ai/guides/overview/pricing
- Ollama:https://ollama.com/library/glm-4.7-flash
除了代码生成,该模型同样适用于创意写作、多语言翻译、长上下文理解与角色扮演等任务,最大支持 131,072 tokens 上下文长度。
性能表现:全面领先
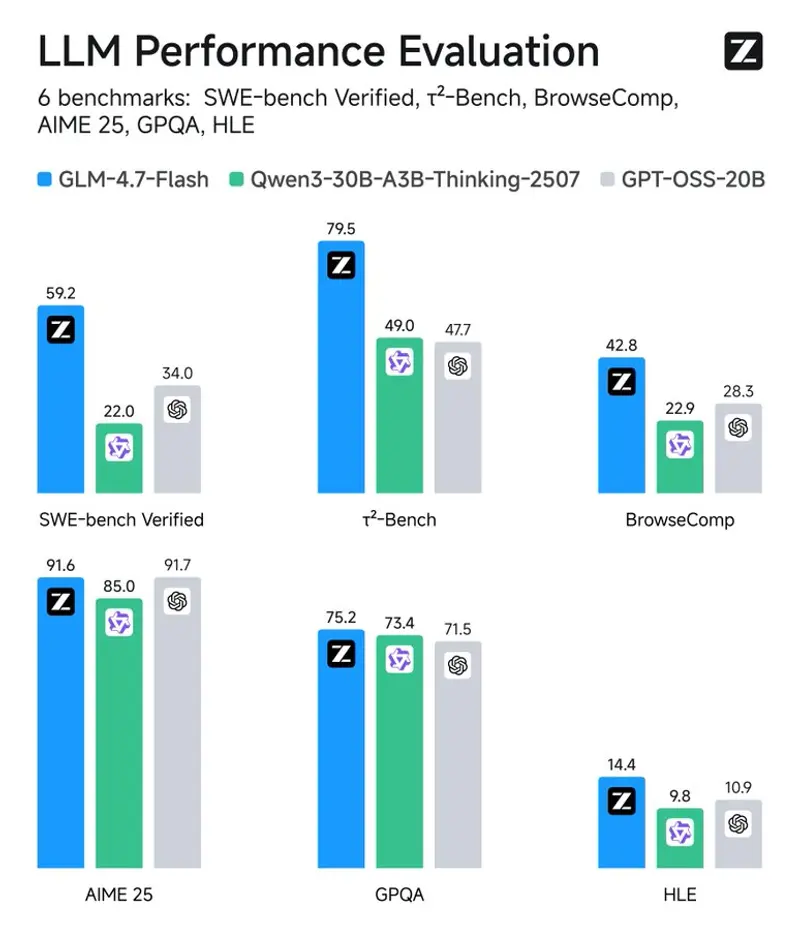
在多项权威基准测试中,GLM-4.7-Flash 表现亮眼,尤其在工程与代理任务上大幅超越同类模型:
| 基准 | GLM-4.7-Flash | Qwen3-30B-A3B-Thinking | GPT-OSS-20B |
|---|---|---|---|
| AIME 25(数学) | 91.6 | 85.0 | 91.7 |
| GPQA(知识推理) | 75.2 | 73.4 | 71.5 |
| SWE-bench Verified(真实代码修复) | 59.2 | 22.0 | 34.0 |
| τ²-Bench(多轮代理) | 79.5 | 49.0 | 47.7 |
| BrowseComp(浏览器自动化) | 42.8 | 2.29 | 28.3 |
在 SWE-bench 和 τ²-Bench 等复杂任务中,GLM-4.7-Flash 的得分几乎是竞品的 2–3 倍,展现出强大的工具调用与任务规划能力。
部署与使用
本地部署支持
- 支持主流推理框架:vLLM、SGLang(需使用主分支)
- 官方提供详细部署指南(见 GitHub 仓库)
云端 API
- GLM-4.7-Flash:免费使用(1 并发)
- GLM-4.7-FlashX:高速高并发版本,按量计费
文档地址:https://docs.z.ai
推理参数建议
| 场景 | Temperature | Top-p | Max Tokens |
|---|---|---|---|
| 通用任务 | 1.0 | 0.95 | 131072 |
| 代码任务(SWE-bench) | 0.7 | 1.0 | 16384 |
| 多轮代理(τ²-Bench) | 0(确定性) | - | 16384 |
对于代理类任务,建议启用 Preserved Thinking 模式,以保持推理链一致性。
适用场景
- 开发者:本地运行代码补全、调试、测试生成
- 研究者:构建可复现的智能体实验环境
- 创作者:长文本生成、多语言内容创作
- 企业用户:私有化部署,保障数据安全
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...










