
在软件开发领域,代码嵌入模型正逐渐成为提升开发效率和代码质量的关键工具。今天,Qodo 宣布推出其最新的代码嵌入模型系列 Qodo-Embed-1,该系列在保持较小模型体积的同时,实现了最先进的性能,为代码搜索、检索增强生成(RAG)和编程语言的上下文理解提供了强大的支持。

Qodo-Embed-1:高性能与高效率的结合
Qodo-Embed-1 提供两种尺寸:
- 精简版(Qodo-Embed-1-1.5B,15 亿参数):专为高效部署设计,适合资源受限的环境。
- 中等版(Qodo-Embed-1-7B,70 亿参数):在性能上进一步优化,适合需要更高精度的应用。
该模型系列在多个基准测试中表现出色,特别是在 CoIR(代码信息检索基准测试) 和 MTEB(多任务嵌入基准测试) 中,超越了所有以前的开源模型。
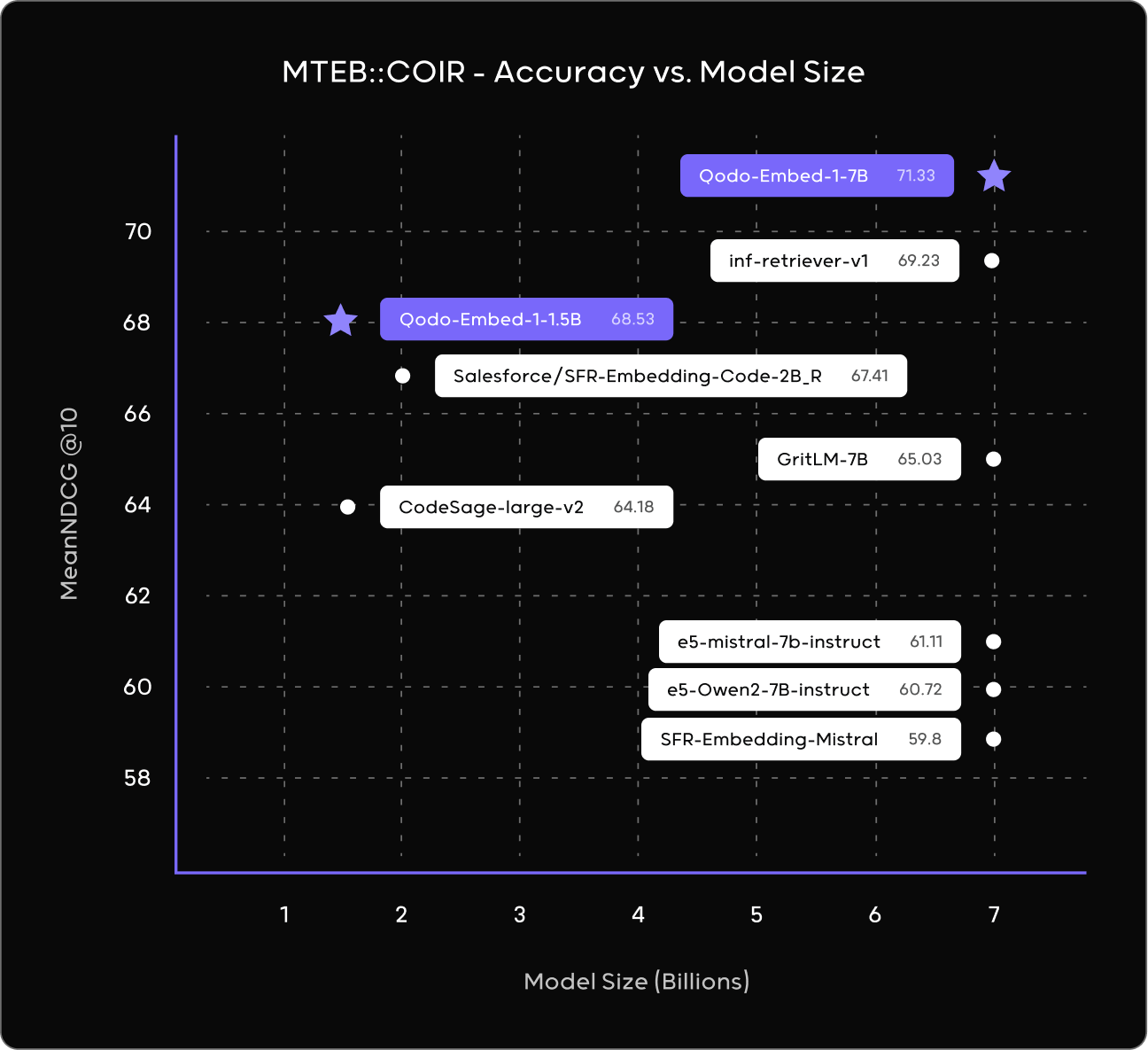
其中,15 亿参数的 Qodo-Embed-1-1.5B 在 CoIR 上得分 68.53,超过了 OpenAI 的 text-embedding-3-large(65.17 分)和 Salesforce 的 SFR-Embedding-2_R(67.41 分)。更大的 Qodo-Embed-1-7B 也表现出色,得分达到 71.5。
解决代码嵌入模型的核心挑战
现有代码嵌入模型的一个主要问题是难以根据自然语言查询准确检索相关的代码片段。许多通用嵌入模型(如 OpenAI 的 text-embedding-3-large)侧重于语言模式,而忽略了代码特有的元素,如语法、变量依赖性、控制流和 API 用法。这导致搜索结果不相关或不精确,严重影响了开发效率。
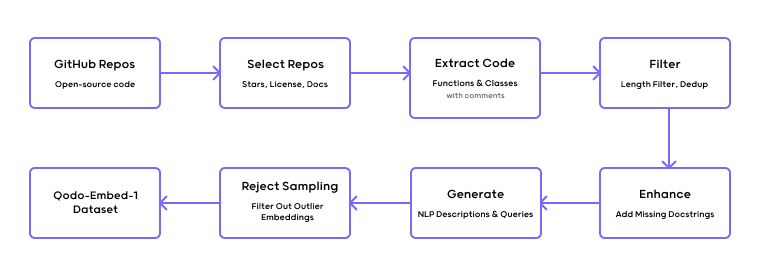
Qodo 通过以下方法解决了这一问题:
- 合成数据生成:通过从 GitHub 自动抓取开源代码,并注入合成函数描述和文档字符串,生成高质量的训练数据。
- 文档字符串生成:为缺乏文档的函数生成多种风格的合成文档字符串,确保代码片段有清晰的自然语言描述。
- 代码查询生成:通过提示生成与代码片段相对应的自然语言查询,增强代码和查询之间的语义对齐。
基准测试表现卓越
在 CoIR 基准测试中,Qodo-Embed-1-1.5B 和 Qodo-Embed-1-7B 的表现尤为突出:
- Qodo-Embed-1-1.5B:得分 68.53,超越了 OpenAI 的 text-embedding-3-large(65.17 分)和 Salesforce 的 SFR-Embedding-2_R(67.41 分)。
- Qodo-Embed-1-7B:得分 71.5,优于同等规模的模型。
这些结果表明,Qodo-Embed-1 不仅在性能上达到了行业领先水平,而且在效率上也表现出色。较小的模型体积使其能够处理和搜索庞大的代码库,而无需大量的计算资源。
为什么模型大小很重要?
虽然大型模型在功能上非常强大,但它们的体积往往限制了其可访问性和部署能力。Qodo-Embed-1 的设计目标是以更少的参数提供顶尖性能,使其更适合开发人员集成到现有工作流程中。较小的模型不仅部署速度更快,所需的计算资源更少,还更易于针对特定用例进行微调。
未来展望
Qodo-Embed-1 模型系列已经在 Hugging Face 上提供:
- Qodo-Embed-1-1.5B:在 OpenRAIL++-M 许可下开放权重,开发人员可以免费使用。
- Qodo-Embed-1-7B:以商业方式提供,适合需要更高性能的企业用户。
通过这些模型,Qodo 不仅为企业开发团队提供了更智能的代码检索和分析工具,还推动了 AI 在软件开发中的广泛应用。未来,Qodo 将继续优化模型性能,支持更多编程语言,并进一步降低部署成本。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











