过去一年,编程智能体(Coding Agents)显著改变了软件开发流程——从自动调试、重构到提交 PR,它们正逐步成为开发者的新“协作者”。然而,主流系统多为闭源、训练成本高昂,且难以适配私有代码库(如内部 API、定制数据管道或组织规范)。
- 模型:https://huggingface.co/collections/allenai/open-coding-agents
- SERA CLI:https://github.com/allenai/sera-cli
- PyPi:https://pypi.org/project/ai2-sera-cli
今天,AI2(Allen Institute for AI)正式发布 Open Coding Agents 项目,首次提供一套完全开源、低成本、可复现的编码智能体方案。其核心模型 SERA 不仅性能领先,更关键的是:你只需约 400 美元,即可在自己的私有代码库上训练出媲美行业顶级模型的智能体。

核心突破:让私有代码库“教会”AI 编程
闭源模型从未见过你的内部代码,因此无法理解其上下文。传统解决方案是在私有数据上微调,但生成高质量的合成训练数据(如错误-修复对)一直成本高昂且依赖复杂测试基础设施。

AI2 提出三项创新,大幅降低门槛:
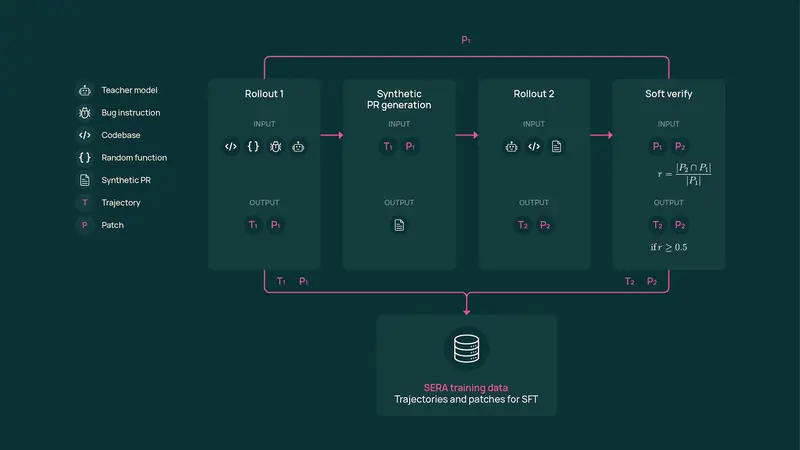
1. 软验证生成(Soft Validation Generation, SVG)
- 传统方法要求修复补丁必须完全正确,需完整测试套件验证
- SVG 允许“部分正确”的补丁——只要语义合理,即可用于训练
- 消除对完备测试的依赖,训练成本降低 57 倍
2. 错误类型菜单扩展
- 基于 51 种常见错误模式分类(如空指针、类型不匹配)
- 对每个函数自动生成多种错误变体,低成本产出数万条训练轨迹
3. 高保真工作流模拟
- 训练数据聚焦开发者实际解决问题的路径,而非仅追求最终代码正确性
- 使模型学会“如何思考”,而非死记“正确答案”
结果:仅用 8,000 条合成轨迹(成本约 1,300 美元),SERA-32B 在 Django 和 SymPy 上超越 110B 参数的教师模型。
SERA 模型:高性能、易部署、兼容 Claude Code
SERA 系列基于 Qwen3 构建,提供 8B–32B 多种规模,支持 32K–64K 上下文:
| 模型 | SWE-Bench Verified 性能 | 训练成本 | 推理速度(H100) |
|---|---|---|---|
| SERA-32B | 54.2%(64K 上下文) | 40 GPU 天 | 1,950 tokens/s(BF16) 3,700 tokens/s(FP8) 8,600 tokens/s(Blackwell B200) |
关键优势:
- ✅ 开箱即用支持 Claude Code,两行代码启动推理服务器
- ✅ 纯监督微调(SFT),无需强化学习(RL)基础设施
- ✅ 可微调至任意私有代码库,包括非标准结构或缺乏测试的项目
在 32K 上下文下,SERA-32B 以 52.23%(Django)和 51.11%(SymPy)的性能,超越 GLM-4.5-Air(51.20% / 48.89%),而模型体积小三分之一,推理更快、成本更低。
成本对比:开源 vs 行业方案
| 目标 | 传统方案成本 | Open Coding Agents 成本 | 降低倍数 |
|---|---|---|---|
| 复现最佳开源结果 | >10,000 美元 | ~400 美元 | 25× |
| 匹配行业顶级模型(如 Devstral Small 2) | >300,000 美元 | ~12,000 美元 | 25×+ |
所有组件(模型、训练代码、合成数据、Claude Code 集成)完全开源,一行命令即可启动。

为什么这很重要?
- 打破资源壁垒
无需大型工程团队或 RL 集群,单个研究者即可构建专业编码智能体。 - 私有代码库友好
企业可安全地在内部代码上微调,无需暴露敏感数据。 - 科学可复现
发布完整训练数据与方法,避免“黑箱比较”,推动社区协作。 - 高效推理
优化后的 SERA 在消费级硬件(如 RTX PRO 6000 Blackwell)上即可高效运行。
适用场景
- 企业内部工具:为私有 SDK、微服务架构定制智能助手
- 学术研究:探索编码智能体的泛化性、鲁棒性与可解释性
- 开源维护:自动修复 issue、生成测试用例、审查 PR
- 个人开发者:在本地代码库上训练专属编程协作者
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











