
在自动化软件工程领域,一个长期存在的挑战是:如何让 AI 代理不仅“能修代码”,还能“会总结、能举一反三”?
上海交通大学、华为、加州大学圣地亚哥分校与西安电子科技大学的联合研究团队近日提出 SWE-Exp ——一种面向代码修复与优化任务的经验驱动型实验框架。该框架通过从历史修复轨迹中提取结构化知识,实现了大语言模型(LLM)在软件问题解决中的经验积累与跨任务迁移,显著提升了自动化修复的效率和成功率。
为什么需要“有记忆”的软件工程代理?
当前基于 LLM 的代码修复方法大多遵循“单次推理、独立求解”模式:每次面对新问题时,模型都像“初次接触”一样重新探索解决方案。这种“无记忆”的行为导致:
- 重复尝试已知失败的修改路径
- 忽视过往成功的修复策略
- 在多文件、跨模块的复杂问题中效率低下
SWE-Exp 的核心思想正是打破这一局限:
让 AI 学会从经验中学习。
它借鉴人类工程师“复盘历史案例、提炼通用模式”的思维方式,构建了一个具备持续学习能力的自动化修复系统。
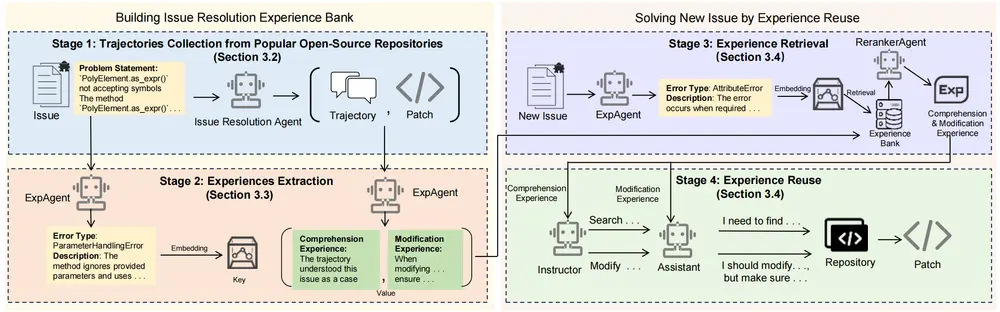
核心功能
🧠 经验提取(Experience Extraction)
从已完成的修复任务轨迹中,自动提取两类关键经验:
- 问题理解经验(Perspective):对问题本质的高层归纳,例如“此错误源于异步回调中的空指针检查缺失”。
- 代码修改经验(Modification):具体的变更操作,如“在
onResponse()函数入口添加if (data != null)判断”。
这些经验被结构化为可读、可检索的知识单元,而非原始日志或代码片段。
💾 多面经验库(Multi-faceted Experience Bank)
提取的经验存储于一个向量化的经验数据库中,支持语义级检索。
每条经验包含:
- 问题上下文嵌入
- 高层理解描述
- 具体修改指令
- 执行结果标签(成功/失败)
这一设计使得系统不仅能记住“做了什么”,还能理解“为什么做”。
🔍 动态经验检索(Dynamic Retrieval)
当处理新问题时,系统会:
- 将当前问题编码为查询向量
- 在经验库中进行语义相似性搜索
- 返回最相关的几条历史经验
检索结果将作为上下文提示,指导后续决策过程。
🤝 双代理协作架构(Dual-Agent Architecture)
SWE-Exp 采用分工明确的双代理设计:
| 代理 | 角色 | 职责 |
|---|---|---|
| 指导者(Instructor) | 策略层 | 分析问题、检索经验、制定修复计划 |
| 执行者(Assistant) | 操作层 | 根据计划定位文件、生成补丁、执行测试 |
这种分层架构避免了单一代理在战略与战术之间频繁切换的认知负担,提升了解决问题的系统性和成功率。
工作流程
- 经验积累阶段
在历史任务执行过程中,系统自动记录成功与失败的完整轨迹,并从中提取结构化经验,存入经验库。 - 新任务求解阶段
- 指导者代理接收新问题
- 检索最相关的历史经验
- 结合当前上下文生成修复策略
- 交由执行者代理实施具体修改
- 反馈闭环
无论成功与否,新的执行轨迹都将被分析并用于更新经验库,实现自监督的持续进化。
实验结果
在权威基准 SWE-bench-Verified 上的测试表明:
| 方法 | Pass@1 成功率 |
|---|---|
| SWE-Exp(DeepSeek-V3-0324) | 41.6% |
| 其他同模型基线方法 | 均低于 41.6% |
这是目前使用 DeepSeek-V3-0324 模型所取得的最高成绩,验证了经验驱动机制的有效性。
消融实验:关键组件贡献分析
| 移除组件 | 性能下降 |
|---|---|
| 理解经验(Perspective) | -3.2% |
| 修改经验(Modification) | -2.6% |
| 双代理架构 | -2.2% |
结果表明,三者均对最终性能有显著贡献,其中高层问题理解经验的影响最大,凸显了“先想清楚再动手”的重要性。
经验数量的影响
研究发现:
并非经验越多越好。
- 使用 1 条最相关经验时,性能达到峰值(41.6%)
- 引入更多经验反而导致性能下降
原因在于:过多的经验可能引入噪声或冲突信息,干扰决策。这也说明 SWE-Exp 的选择性利用机制至关重要。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











