
Liquid AI 正式发布新一代设备端基础模型 LFM2(Liquid Foundation Model 2),重新定义了边缘 AI 推理的速度、效率与部署灵活性。
作为专为嵌入式设备和本地计算环境设计的语言模型,LFM2 在 CPU 上的解码和预填充速度比 Qwen3 快达 2 倍,同时在训练效率上提升了 3 倍,成为目前市场上最高效的设备端基础模型之一。
LFM2 的核心优势
极速推理与训练
- CPU 解码/预填充速度提升 2 倍(对比 Qwen3)
- 训练效率提升 3 倍(相比上一代 LFM1)
- 支持快速原型到产品落地的全栈优化流程
多项基准测试领先
在多个关键能力维度中表现优异:
- 知识理解(MMLU、GPQA)
- 数学推理(GSM8K、MGSM)
- 指令遵循(IFEval、IFBench)
- 多语言支持(涵盖阿拉伯语、法语、德语、西班牙语、日语、韩语、中文)
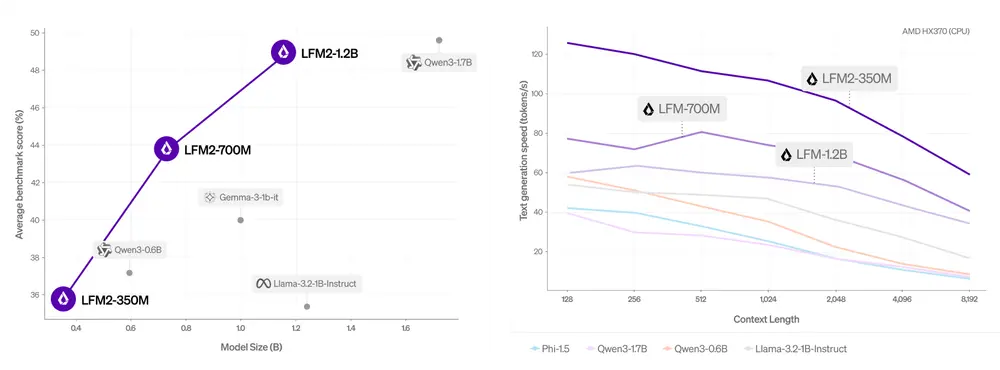
即使在参数规模较小的情况下,LFM2 依然能媲美甚至超越更大模型,例如:
- LFM2-700M 超越 Gemma 3 1B IT
- LFM2-350M 与 Qwen3-0.6B 和 Llama 3.2 1B Instruct 相当
创新混合架构
LFM2 是一种基于 LIV 操作符 的液体时间常数网络,融合了卷积与注意力机制,具备以下特点:
- 模块化设计:共 16 个模块,包括 10 个双门控短程卷积模块 + 6 个分组查询注意力模块
- 输入感知动态权重生成:使模型更适应实际设备负载
- 面向 SoC CPU 优化:特别适配高通 Snapdragon 等嵌入式芯片
该架构通过 Liquid AI 自研神经架构搜索系统 STAR 进行多目标优化,确保质量、延迟和内存的最佳平衡。
部署灵活,覆盖广泛终端设备
LFM2 可运行于多种硬件平台,包括:
- 手机(如三星 Galaxy S24 Ultra)
- 笔记本电脑(AMD Ryzen HX370)
- 汽车、机器人、可穿戴设备等嵌入式系统
得益于其轻量级设计和高效推理能力,LFM2 特别适用于以下场景:
- 毫秒级响应需求(如语音助手、实时翻译)
- 离线使用场景(如车载导航、无人机控制)
- 数据隐私要求高(如医疗记录处理、金融合规分析)
性能实测:从实验室到真实世界
Liquid AI 使用自动化评估套件 + LLM 评判机制,全面验证 LFM2 的能力:
| 模型 | 参数量 | 对比对象 | 表现 |
|---|---|---|---|
| LFM2-1.2B | 12 亿 | Qwen3-1.7B | 几乎持平 |
| LFM2-700M | 7 亿 | Gemma 3 1B IT | 更优 |
| LFM2-350M | 3.5 亿 | Llama 3.2 1B Instruct | 相当 |
此外,在多轮对话场景下,LFM2-1.2B 在 WildChat 数据集上的表现优于 Llama 3.2 1B Instruct 和 Gemma 3 1B IT,与 Qwen3-1.7B 持平。
开源可用,企业友好许可
LFM2 已在 Hugging Face 和 Liquid Playground 上开放下载,提供三种参数版本:
- LFM2-350M(3.5 亿)
- LFM2-700M(7 亿)
- LFM2-1.2B(12 亿)
许可证说明:
- 学术研究 & 小型企业(年收入 < $10M):可免费商用
- 中大型企业需联系 sales@liquid.ai 获取商业授权
推荐开发者结合 llama.cpp、TRL 等工具进行本地部署与微调,以适配具体业务场景。
市场前景广阔
据预测,到 2035 年,紧凑型私有基础模型市场规模将达到万亿美元级别,尤其在消费电子、机器人、智能家电、金融科技、教育等领域增长迅猛。
LFM2 的推出标志着 AI 正在从“云端集中”走向“本地智能”,为企业提供更安全、更快、更具成本效益的部署路径。
适用人群
- AI 工程师与研究人员
- 移动与嵌入式开发团队
- 需要本地化 AI 方案的企业
- 对生成式 AI 部署感兴趣的创业者
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











