
月之暗面推出一款全新的开源编码大语言模型 Kimi-Dev-72B,专为软件工程任务设计。该模型基于 Qwen2.5-72B 微调而来,在 SWE-bench Verified 测试中取得了 60.4% 的通过率,刷新了开源模型在该基准上的性能记录。
- 项目主页:https://moonshotai.github.io/Kimi-Dev
- GitHub:https://github.com/MoonshotAI/Kimi-Dev
- 模型:https://huggingface.co/moonshotai/Kimi-Dev-72B
这一成绩不仅标志着代码理解与生成能力的重大进步,也展现了其在实际开发场景中的实用潜力。
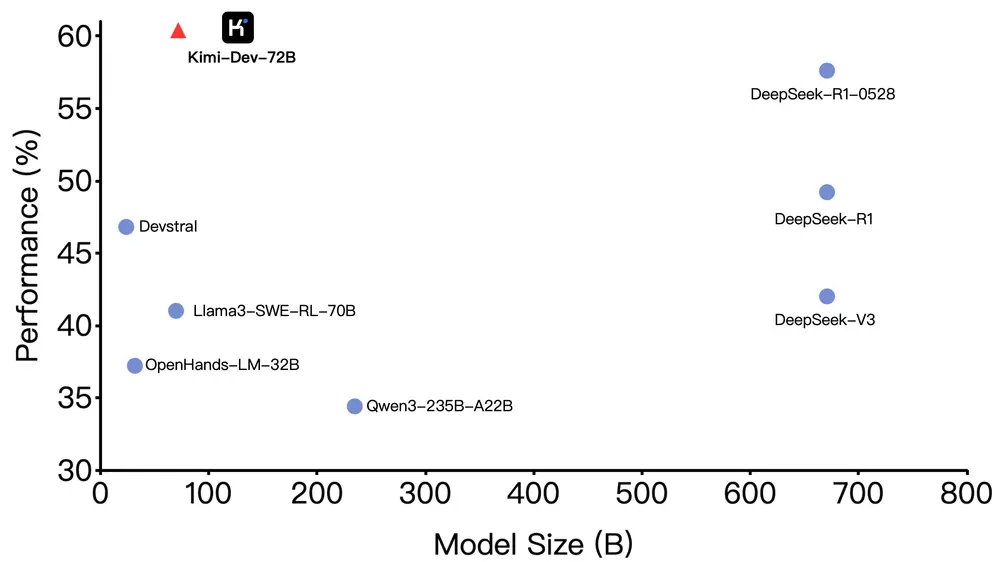
性能领先:SWE-bench 验证集上表现突出
在衡量代码修复能力的标准测试集 SWE-bench Verified 上,Kimi-Dev-72B 取得了目前开源模型中最佳的成绩——60.4% 的问题成功修复率,超越了所有已知竞品。
这一结果得益于其在训练过程中引入的大规模强化学习机制,并结合真实代码仓库的自动修补流程。只有当整个测试套件通过时,模型才会获得正向反馈,从而确保输出方案的准确性和稳定性。
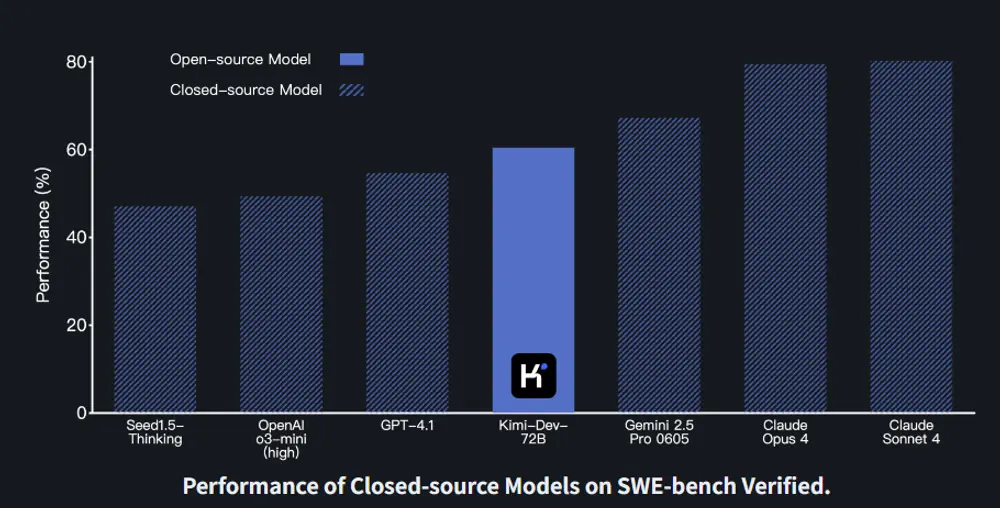
技术亮点:双角色协作 + 强化学习 + 自我博弈
1. BugFixer 与 TestWriter:协同工作的双人组合
Kimi-Dev-72B 的核心设计理念是“BugFixer”与“TestWriter”的双角色机制:
- BugFixer 负责识别并修复代码中的错误;
- TestWriter 则负责编写能够重现 bug 的单元测试。
这两个角色相辅相成:一个成功的补丁应能通过对应的测试用例;而一个有效的测试用例应在应用正确补丁后通过。这种互补关系使模型在代码理解和验证两个维度上都能保持高水准。
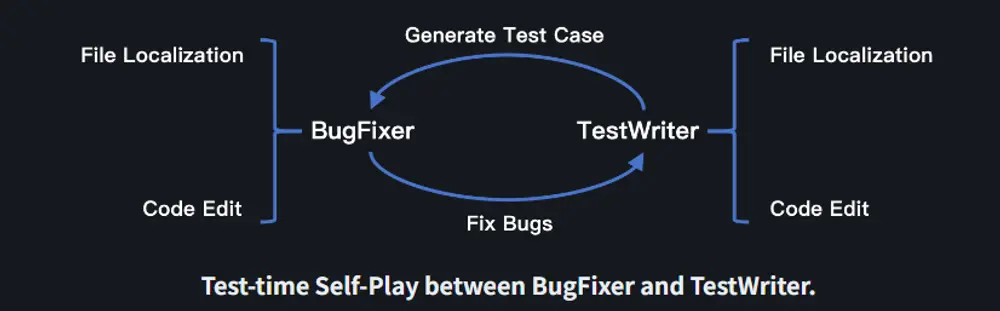
两者的处理流程一致,分为两个阶段:
- 定位需要修改的文件;
- 执行正确的代码变更。
这种统一架构简化了训练流程,也为后续优化打下基础。
2. 中间训练:提升代码修复与测试编写的先验能力
为了增强模型对实际开发任务的理解能力,团队使用约 1500 亿 token 的高质量数据 对 Kimi-Dev-72B 进行中间训练。
训练数据来源于 GitHub 上的真实问题报告和 Pull Request 提交,涵盖大量真实世界的 bug 修复与测试用例编写案例。这些数据经过严格清洗,避免与 SWE-bench Verified 数据重叠,保证评估的公正性。
通过这段训练,模型掌握了开发者常见的行为模式,为其后续的强化学习打下了坚实基础。
3. 强化学习:聚焦代码编辑能力提升
在完成监督微调之后,Kimi-Dev-72B 已具备较强的文件定位能力。因此,强化学习阶段主要聚焦于代码编辑能力的提升。
采用的方法包括:
- 仅基于结果的奖励机制:只根据最终 Docker 执行结果(通过或失败)进行奖励反馈,不依赖格式或过程评分;
- 高效提示筛选:过滤掉多次尝试失败的无效提示,提升训练效率;
- 课程学习与正例强化:逐步增加任务难度,并将成功样本纳入后续训练批次,强化模型的成功路径。
此外,高度并行化的内部代理基础设施,使得大规模训练成为可能,显著提升了训练效率与模型表现。
4. 测试时自我博弈:协调 Bug 修复与测试生成
在推理阶段,Kimi-Dev-72B 采用一种自我博弈机制来协调 BugFixer 和 TestWriter 的能力。
每个问题会生成最多 40 个补丁候选和 40 个测试候选,通过多轮交互筛选出最优解。这种机制有效提升了修复成功率,并增强了模型对复杂问题的适应能力。
开源开放:欢迎开发者共建生态
Kimi-Dev-72B 已全面开源,相关资源包括:
- 模型权重
- 训练与推理代码
- 技术白皮书(即将发布)
月之暗面鼓励开发者与研究人员下载、部署并参与后续改进工作。GitHub 和 Hugging Face 平台均已提供模型访问入口。
作为一个开源项目,Kimi-Dev-72B 的发展离不开社区的持续贡献。月之暗面期待更多开发者将其应用于实际项目中,推动其在软件工程领域的进一步落地。
展望未来:更深入地融入开发者工作流
接下来,月之暗面将继续探索 Kimi-Dev-72B 在更广泛软件工程任务中的应用,包括:
- 与主流 IDE(如 VSCode、JetBrains 系列)集成;
- 支持 Git 版本控制系统的自动化建议;
- 无缝接入 CI/CD 管道,辅助自动化构建与测试。
月之暗面还将持续优化模型性能,开展红队测试以发现潜在问题,并计划在未来发布更强大的迭代版本。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











