今天凌晨,阿里巴巴正式开源 Qwen3 Embedding 系列模型,作为 Qwen 模型家族的最新成员,该系列专注于文本语义表征、信息检索与排序任务,在多语言理解、跨语言检索和代码相关性建模等方面展现出卓越性能。
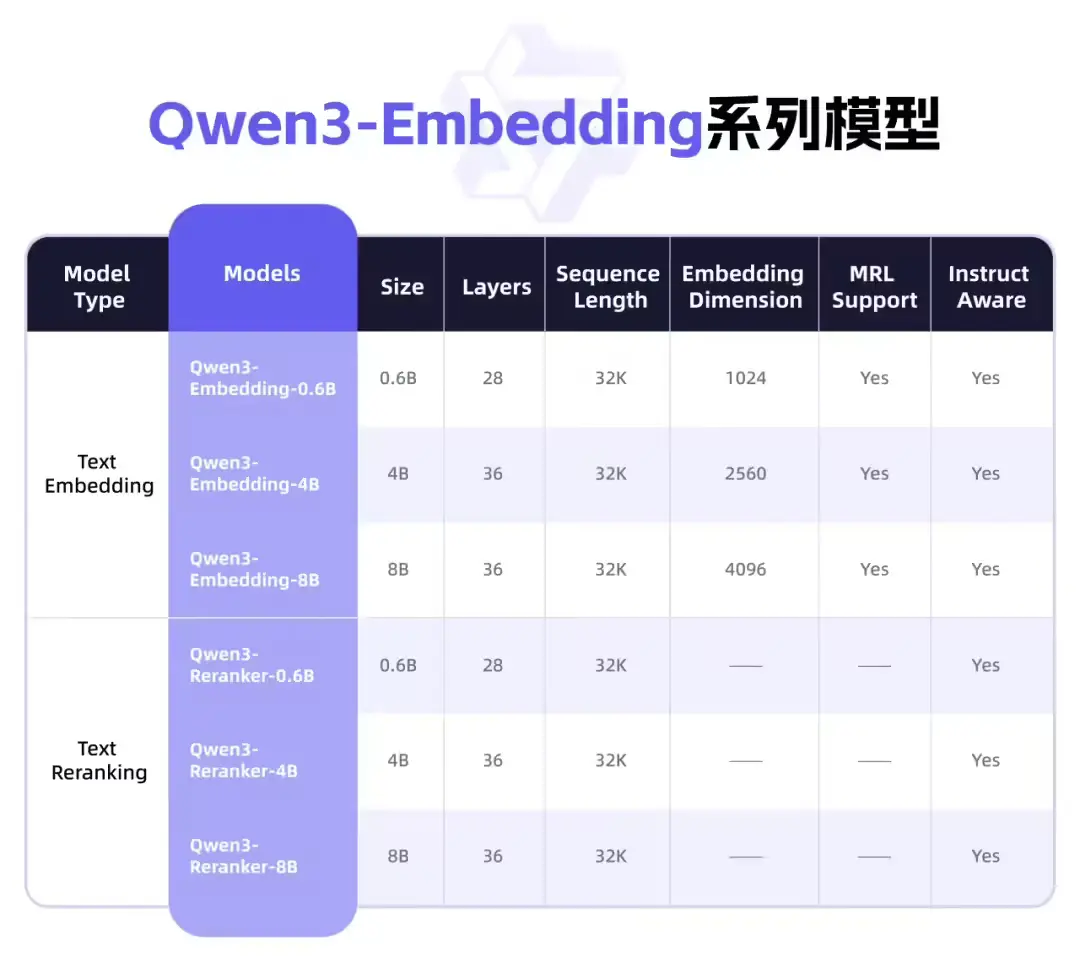
目前,该系列模型已通过 Apache 2.0 协议在 Hugging Face 和 ModelScope 上开源,配套的技术报告与训练代码也已在 GitHub 发布,供研究人员与开发者自由使用。
- Hugging Face: Qwen3 Embedding | Qwen3-Reranker
- ModelScope: Qwen3 Embedding | Qwen3-Reranker
- GitHub :https://github.com/QwenLM/Qwen3-Embedding
核心亮点
✅ 行业领先的泛化能力
Qwen3 Embedding 系列在多个下游任务中表现优异:
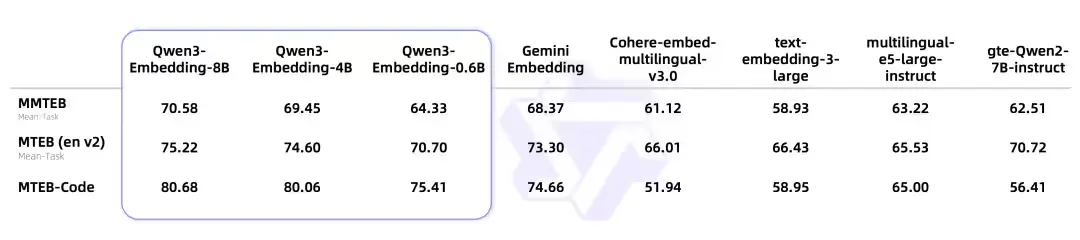
- 8B 参数规模的 Embedding 模型 在 MTEB 多语言排行榜上位列第一(截至 2025 年 6 月 5 日,综合得分为 70.58),超越多个商业 API。
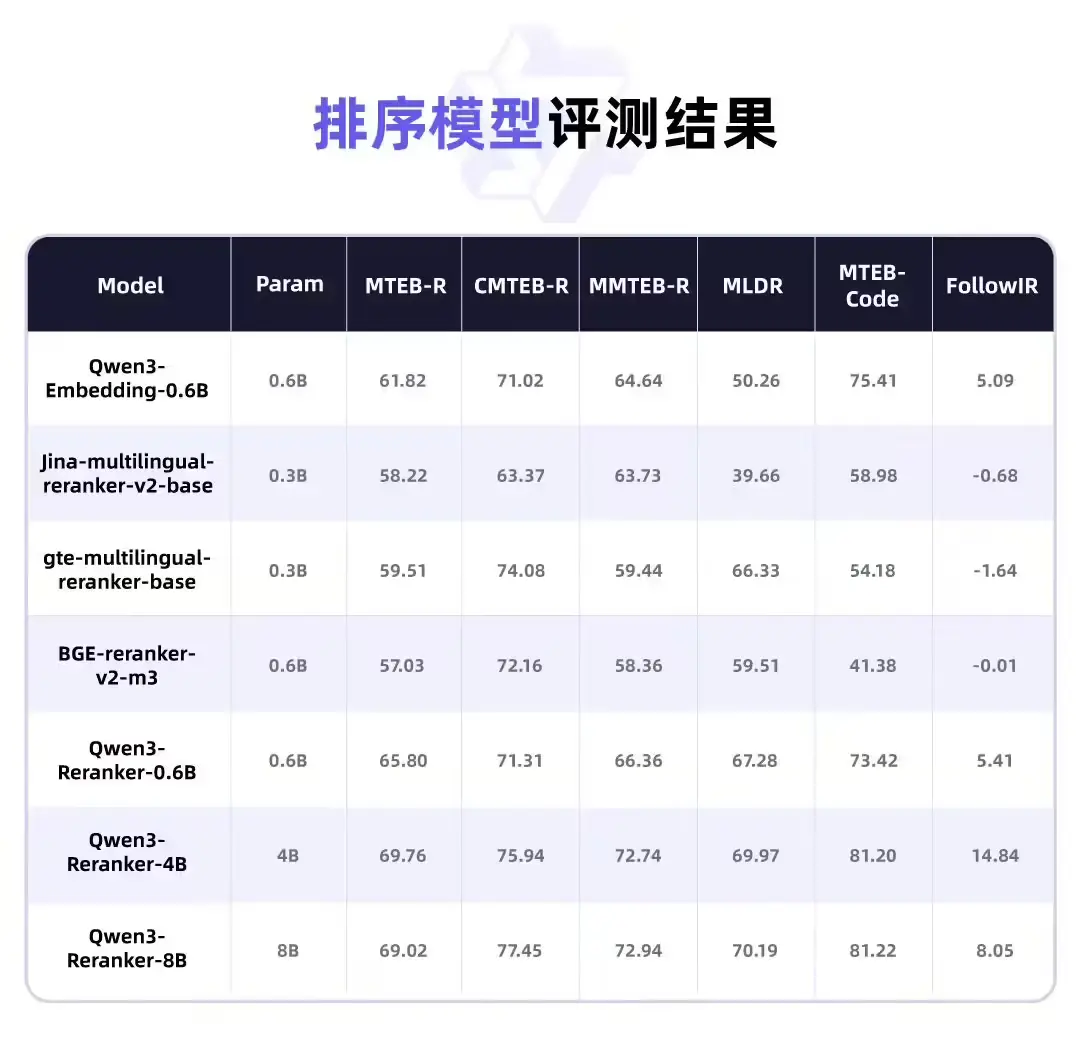
- 排序模型在各类文本检索场景中显著提升搜索结果的相关性,尤其在长尾查询和复杂语义匹配方面表现突出。
🔄 灵活的模型架构
提供三种参数规模(0.6B / 2B / 8B)以满足不同应用场景的需求:
- 支持 表征维度自定义,降低部署成本;
- 提供 指令适配模板,便于针对特定任务、语言或领域进行优化;
- 可灵活组合 Embedding + Reranking 模块,实现端到端检索系统构建。
🌍 全面支持多语言与代码
覆盖 100+ 种自然语言 与多种编程语言,具备强大的:
- 多语言语义理解能力
- 跨语言检索能力
- 代码片段表示与匹配能力
适用于全球化业务场景与软件开发需求。
模型架构详解
基于 Qwen3 基础模型,Qwen3 Embedding 系列采用两种主流架构设计:
| 模型类型 | 架构形式 | 输入方式 | 输出目标 |
|---|---|---|---|
| Embedding 模型 | 双塔结构 | 单段文本输入 | 文本语义向量表示 |
| Reranking 模型 | 单塔结构 | 文本对输入(如 query-doc) | 相关性打分 |
具体实现如下:
- Embedding 模型:取最后一层
[EOS]标记的隐藏状态作为文本表征; - Reranking 模型:基于单塔结构计算文本对之间的语义相关性得分;
- 所有模型均通过 LoRA 微调,保留基础模型的语义理解能力。
训练方法与技术创新
Qwen3 Embedding 系列继承了 GTE-Qwen 的多阶段训练范式,并进行了深度优化:
Embedding 模型训练流程
采用三阶段训练策略:
- 弱监督预训练:利用 Qwen3 的生成能力,动态生成大规模弱监督数据对;
- 监督微调:基于高质量标注数据进一步提升模型性能;
- 模型融合:融合多个候选模型输出,增强整体泛化能力。
⭐ 创新点:我们构建了多任务 Prompt 体系,突破传统依赖社区数据筛选的限制,实现了高效的大规模弱监督数据生成。
Reranking 模型训练
直接基于高质量标注数据进行监督训练,兼顾训练效率与排序精度。
测试基准与性能表现
我们在多个标准评测集上验证了 Qwen3 Embedding 系列的性能,包括:
| 测试集 | 类型 | 主要用途 |
|---|---|---|
| MTEB-R (eng, v2) | 英文检索任务 | 英文通用语义检索 |
| CMTEB-R (cmn, v1) | 中文检索任务 | 中文语义匹配与检索 |
| MMTEB-R (Multilingual) | 多语言检索任务 | 跨语言检索与理解 |
| MTEB-Code | 编程语言任务 | 代码语义表示与匹配 |
所有测试中,Qwen3 Embedding 系列均表现出色,尤其在中文和多语言任务中具有明显优势。
未来展望
Qwen3 Embedding 系列的发布,标志着我们在构建高性能语义检索系统道路上迈出了重要一步。
未来,阿里将持续优化:
- 提升训练效率与推理速度,增强实际部署性能;
- 拓展至多模态语义表征领域,构建图像、语音与文本的统一语义空间;
- 推动模型在企业级应用中的落地,如智能客服、搜索引擎、推荐系统等。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











