
Meta推出了一款名为 KernelLLM 的大语言模型,该模型基于 Llama 3.1 Instruct,专注于使用 Triton 编写高效GPU内核的任务。KernelLLM的核心目标是通过自动化生成高性能的Triton代码,降低GPU编程的技术门槛,让更多开发者能够轻松参与到高性能计算领域。
KernelLLM的愿景与意义
随着计算工作负载的日益复杂化以及加速器架构的多样化,对定制化GPU内核的需求显著增加。然而,传统的内核开发需要深厚的专业知识和丰富的经验,限制了其普及性。KernelLLM的出现正是为了应对这一挑战——它通过智能化的方式自动生成高效的Triton实现,从而满足对高性能GPU内核不断增长的需求。
目前,大多数相关研究仅限于测试时间优化或特定问题的解决方案调整,这在一定程度上限制了模型的泛化能力。而KernelLLM的独特之处在于,它是首个在外部数据(如PyTorch和Triton)上进行微调的大语言模型。Meta希望通过开源KernelLLM,推动智能内核编写系统的快速发展。
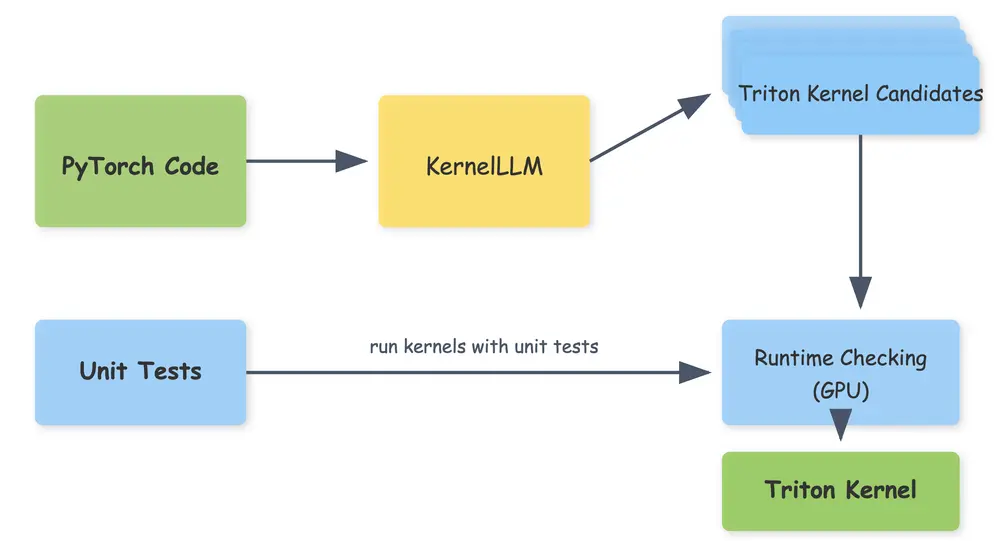
工作流程:从PyTorch到Triton内核
KernelLLM的工作流程非常直观:
- 输入一段 PyTorch代码(绿色),模型会将其翻译为 Triton内核候选。
- 生成的内核通过单元测试进行验证,这些测试运行带有已知形状的随机输入,以确保代码的正确性。
- 通过增加内核候选生成的数量(即 pass@k 方法),模型可以评估多个生成结果,并最终选择性能最优的内核实现(绿色输出)。
这种方法不仅提高了内核生成的效率,还确保了生成代码的质量和可靠性。
数据集与训练方法
KernelLLM的训练数据集包含约 25,000对PyTorch模块及其等效Triton内核实现 的配对样本,同时还包括一些通过合成生成的样本。这些数据来自多个来源:
- TheStack 中的过滤代码;
- 通过 torch.compile() 和额外提示技术生成的合成样本。
经过筛选和编译的数据集已公开,可在 GPU MODE Huggingface 上获取。
模型采用 监督指令微调 方法,在创建的数据集上对 Llama 3.1-8B-Instruct 进行了微调。训练过程中,torch代码使用了一个包含格式示例的提示模板作为指令。模型在训练数据的一个子集上进行了超参数选择,共训练了10个周期,每批大小为32。整个训练过程耗时约12小时(192个GPU小时),并在16个GPU上完成。
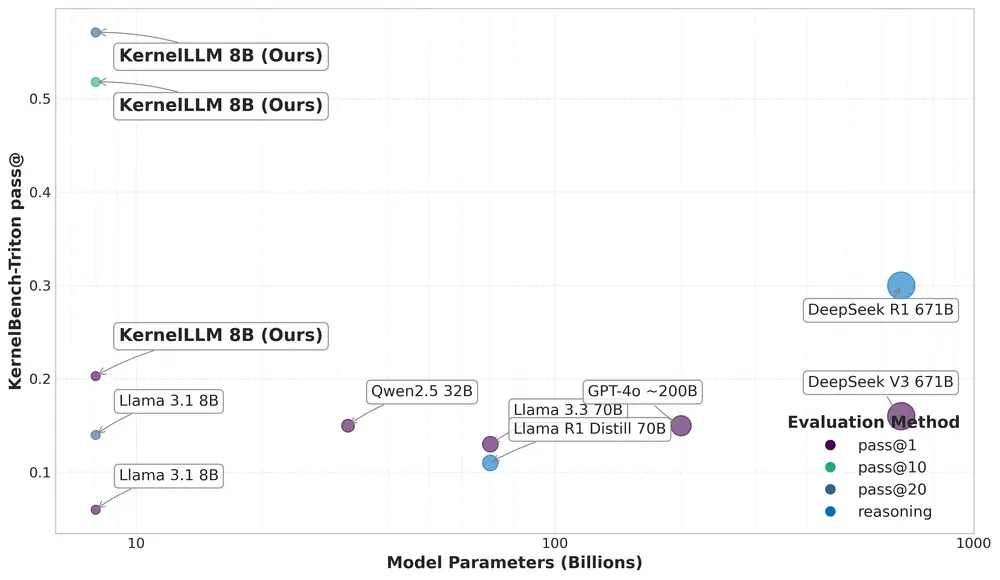
性能表现
尽管KernelLLM是一个规模较小的8B参数模型,但其在内核生成任务中的表现却与更大规模的语言模型相当甚至更优。这一优异表现得益于其针对 KernelBench Level 1 基准的专门训练方法。
KernelLLM在 KernelBench-Triton 上的表现尤为突出。这是一个专门为评估LLM生成Triton内核能力设计的基准测试,包含250个按难度分级的PyTorch模块,从单个操作(如Conv2D或Swish,级别1)到完整模型架构(级别3)。KernelBench通过以下两个维度衡量模型性能:
- 正确性:生成的代码是否与参考PyTorch输出一致;
- 性能提升:生成的Triton内核相比基线实现的加速效果。
所有测试均在 英伟达 H100 GPU 上进行。KernelLLM在推理时采用了温度为1.0、top_p为0.97的设置,确保生成结果的多样性和高质量。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











