
Falcon 团队正式发布了 Falcon-Edge 系列模型——一组基于 BitNet 架构设计的三值格式语言模型。这些模型不仅具备高性能,还支持灵活的微调能力,为边缘设备上的高效部署提供了全新可能。
- GitHub:https://github.com/tiiuae/onebitllms
- 模型:https://huggingface.co/collections/tiiuae/falcon-edge-series-6804fd13344d6d8a8fa71130

为什么是 BitNet?
传统大型语言模型(LLM)通常依赖高精度浮点运算(如 FP32 或 BF16),这导致它们在资源受限的设备上难以高效运行。近年来,压缩模型成为研究热点,包括低精度量化、参数剪枝等方法。
而 BitNet 提出了一种完全不同的思路:直接使用三值权重({-1, 0, 1})进行训练,实现端到端的超低精度模型设计。这种“无矩阵乘法”的计算方式显著降低了推理时的内存占用与计算开销。
然而,尽管 BitNet 在推理效率方面具有巨大优势,其预训练过程仍面临两个主要挑战:
- 性能瓶颈:早期的 BitNet 模型在多个任务上的表现弱于同规模的传统 LLM。
- 可访问性问题:现有方法难以通过微调已有非 BitNet 模型来生成有效的 BitNet 版本,限制了其实用性。
Falcon-Edge 正是在这样的背景下诞生的。
Falcon-Edge 的核心创新
1. 统一训练流程,生成多版本模型
Falcon-Edge 引入了一种新的预训练范式:在一个统一的训练过程中,同时产出三种类型的模型:
- 非量化模型(bfloat16 格式):用于兼容传统框架,便于评估与迁移学习。
- 原生 BitNet 模型:适用于低资源环境下的高效推理。
- 预量化 BitNet 变体:专为后续微调设计,提升模型适应不同场景的能力。
这一机制极大提升了模型的灵活性,使得开发者可以根据具体需求选择合适的版本进行部署或进一步训练。
2. 多参数规模支持
目前 Falcon-Edge 提供两种参数量级:
- 1B(10亿参数)
- 3B(30亿参数)
每种规模都包含基础模型(base)和指令调优模型(instruction-tuned),以满足从通用理解到任务导向的不同需求。
架构优化与训练策略
1. 基于论文《1-bit LLM》的设计改进
Falcon-Edge 采用了《1-bit LLM: Training Ternary Weight Models at Scale》中的核心架构理念,并在此基础上做了关键调整:
- 移除了 BitNet 层中的 Layer Normalization(层归一化),但在注意力模块和前馈网络(MLP)前保留,确保与主流架构(如 Llama)兼容。
- 这一改动未对模型性能造成负面影响,反而简化了实现并增强了泛化能力。
2. Triton 内核优化
为了降低训练成本,团队开发了针对 activation_quant 和 weight_quant 的 Triton 加速内核,并在开源库 onebitllms 中提供。
这些优化大幅提升了训练效率,使得大规模 BitNet 模型的训练更具可行性。
3. 分词器优化
为了控制模型体积,Falcon-Edge 使用了一个精简的词汇表(共 32,678 个 token),训练语料以英文为主,并额外加入了常用 LaTeX 符号,增强科学文本处理能力。
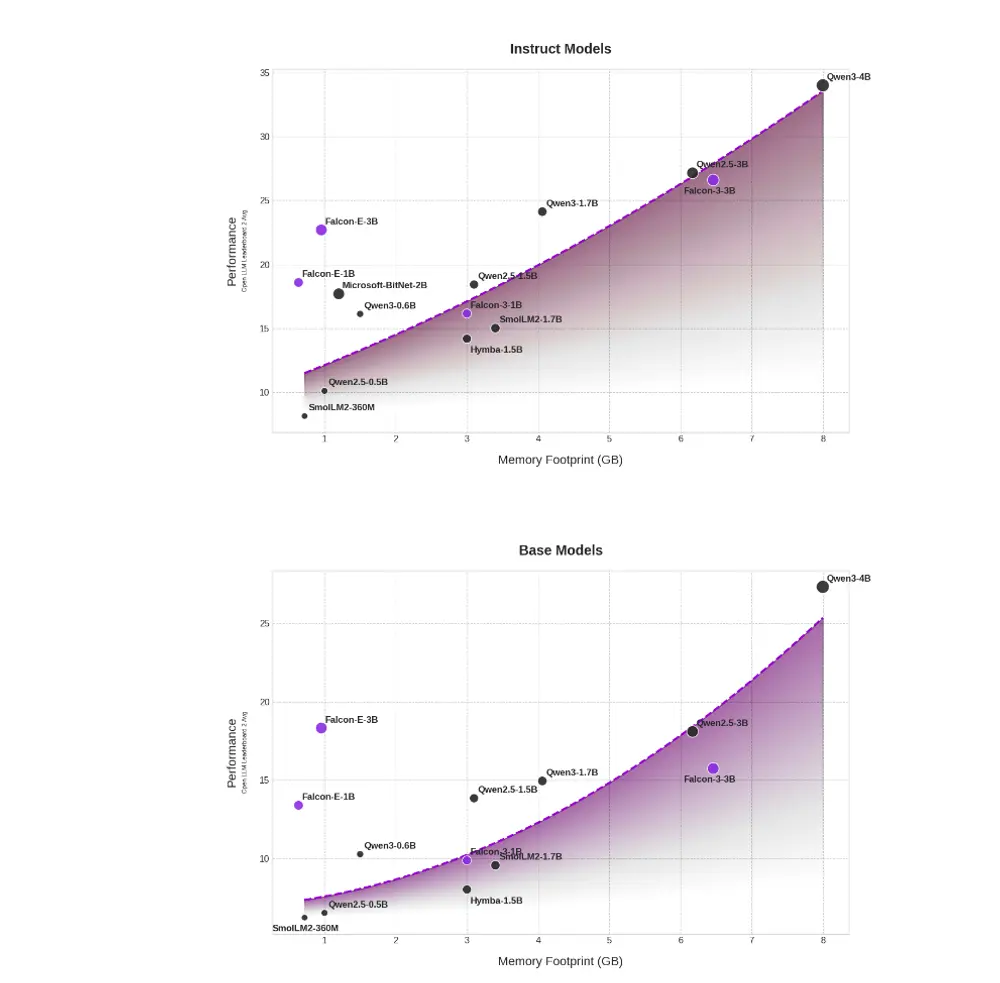
性能评估与竞争力分析
Falcon-Edge 在 Hugging Face 排行榜 v2 上进行了全面测试,涵盖了多种自然语言理解和生成任务。结果显示:
- Falcon-Edge 在多个任务中表现出与同规模传统模型相当甚至更优的性能。
- 即便采用三值权重,模型在目标领域仍能保持强竞争力,验证了 BitNet 路线的可行性。
支持微调的 BitNet 生态构建
以往的 BitNet 发布大多仅提供最终的量化模型,无法进行再训练。Falcon-Edge 则首次实现了完整的训练-微调闭环。
用户可通过以下步骤轻松进行微调:
- 将
nn.Linear替换为BitnetLinear; - 使用预量化检查点继续训练;
- 训练完成后,导出为 BitNet 格式用于推理。
为了支持这一流程,Falcon 同步推出了一个轻量级 Python 工具包:onebitllms。
onebitllms:面向未来的研究工具
onebitllms 是一个专注于 1 位语言模型训练与微调的开源库,具备以下核心功能:
- 模型转换工具:将预量化模型转换为可训练格式,兼容主流微调框架(如 Hugging Face 的
trl)。 - 检查点量化工具:将训练后的模型导出为 BitNet 或 bfloat16 格式。
- 底层 API 支持:提供裸
BitnetLinear模块和 Triton 内核,便于高级用户自定义训练流程。
该库当前支持全量微调,未来计划扩展支持参数高效微调(PEFT)方法,以进一步降低训练门槛。
未来展望与开放问题
Falcon-Edge 的发布不仅是一次技术突破,也为 BitNet 方向的研究开辟了新路径。我们认为以下几个方向值得持续探索:
- 更高效的 GPU 推理内核:目前推理速度仍有提升空间,尤其在 GPU 上的表现值得关注。
- BitNet 的 PEFT 方法研究:当前微调依赖全量参数更新,探索参数高效方案将是重要课题。
- BitNet 检查点的通用性研究:如何最小化 BitNet 与其原始 bfloat16 版本之间的性能差距,是一个关键问题。
- 多模态 BitNet 模型探索:将 BitNet 扩展至视觉语言模型(VLM)等领域,有助于推动更多实际应用。
- 更高效的训练内核优化:当前训练开销约为传统 LLM 的 1.2 倍,仍有进一步压缩空间。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











