
Deep Cogito 今日正式发布 Cogito v2 预览版,推出四款开源混合推理模型:
- 70B 密集型
- 109B MoE
- 405B 密集型
- 671B MoE
其中,671B MoE 是当前全球最强的开源大模型之一,在多项任务上性能媲美甚至超越 DeepSeek R1 与 v3,并逼近闭源前沿模型如 o3 和 Claude 4 Opus。
- Huggingface:https://huggingface.co/collections/deepcogito/cogito-v2-preview-6886b5450b897ea2a2389a6b
- Unsloth:https://docs.unsloth.ai/basics/tutorials-how-to-fine-tune-and-run-llms/cogito-v2-how-to-run-locally
- Together AI:https://www.together.ai/models/cogito-671b-moe
- Baseten:https://www.baseten.co/library/cogito-v2-671b/
- RunPod:https://console.runpod.io/hub
但真正值得关注的,不是参数规模,而是其背后的方法论变革:Cogito 正在尝试让模型“学会思考”,而非仅仅“花更多时间思考”。
关键突破:从“推理时搜索”到“内化直觉”
当前主流推理模型的性能提升,大多依赖于延长推理链(如增加思考 token 数量),本质上是“用更多搜索弥补先验不足”。这种方式虽有效,但效率低下,且难以扩展。
Cogito 的目标不同:它试图通过 迭代蒸馏与放大(Iterative Distillation and Amplification, IDA),将模型在推理过程中学到的策略“蒸馏”回参数中,从而增强其智能先验(intelligent prior)。
这意味着:
模型不再需要每次都从头推理,而是能“凭直觉”接近正确答案。
这正是 AlphaGo 系列实现超人表现的核心机制——通过蒙特卡洛树搜索(MCTS)生成高质量策略,再将其训练回神经网络。Cogito 将这一思想迁移到语言模型领域,构建了一个可扩展的自我改进闭环。
方法论:构建超级智能的两步循环
Cogito 的方法基于一个已被验证有效的智能演化框架:
- 推理时推理(Reasoning-time Inference)
在回答前进行内部思考,探索可能的解法路径。 - 迭代策略改进(Iterative Strategy Improvement)
将成功的推理过程反向训练回模型参数,提升其下一次推理的起点质量。
这一循环使得模型不仅能“解决问题”,还能“学会如何更好地解决问题”。
“我们不是在训练一个更会搜索的模型,而是在训练一个更懂搜索的模型。”
Cogito v2 的核心进展在于:将第二步——策略蒸馏——系统化、规模化,并应用于超大规模模型。
四款模型,两种路径
本次发布的四款模型采用差异化训练策略,探索不同方向的优化边界。
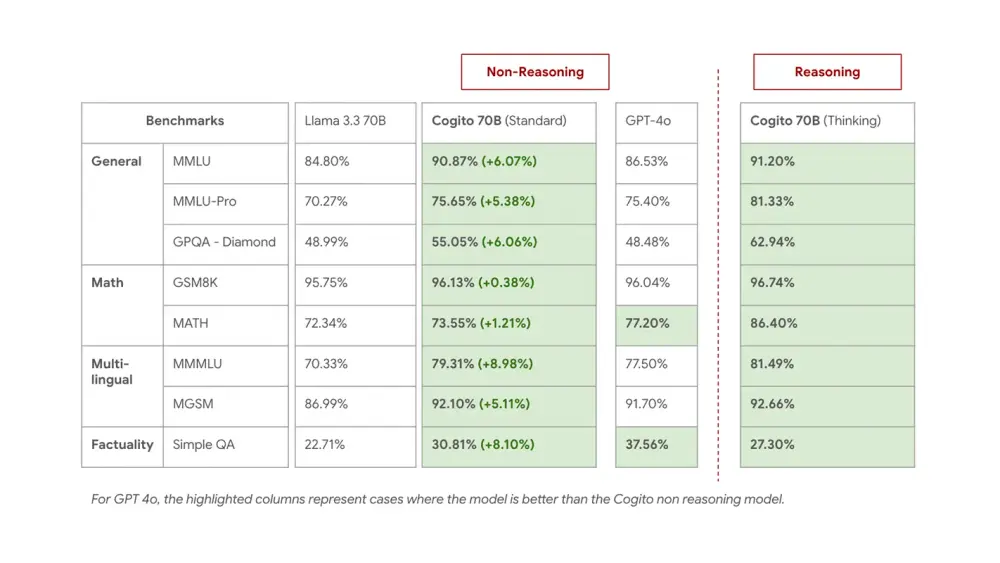
中等规模模型(70B、109B MoE、405B 密集型)
- 目标:提升非推理模式下的“直觉”能力
- 方法:将推理过程蒸馏回原始模型参数
- 效果:
- 在标准生成模式下表现显著优于同规模 Llama 基线
- 减少对回溯、重试等启发式技巧的依赖
- 更接近前沿模型的“自然流畅性”
这些模型适用于需要高响应速度、低延迟的场景,同时保持强推理能力。
超大规模模型(671B MoE)
- 目标:同时优化“直觉”与“推理过程”
- 方法:不仅蒸馏最终答案,还为思考过程本身提供训练信号
- 效果:
- 推理链长度比 DeepSeek R1 缩短 60%,性能持平或更优
- 在非推理模式下,性能匹敌 DeepSeek v3 0324
- 内部测试中,综合能力位列全球开源模型前列
这是目前唯一一个在训练中明确优化“推理路径质量”的开源模型,标志着从“输出正确”向“过程高效”的跃迁。
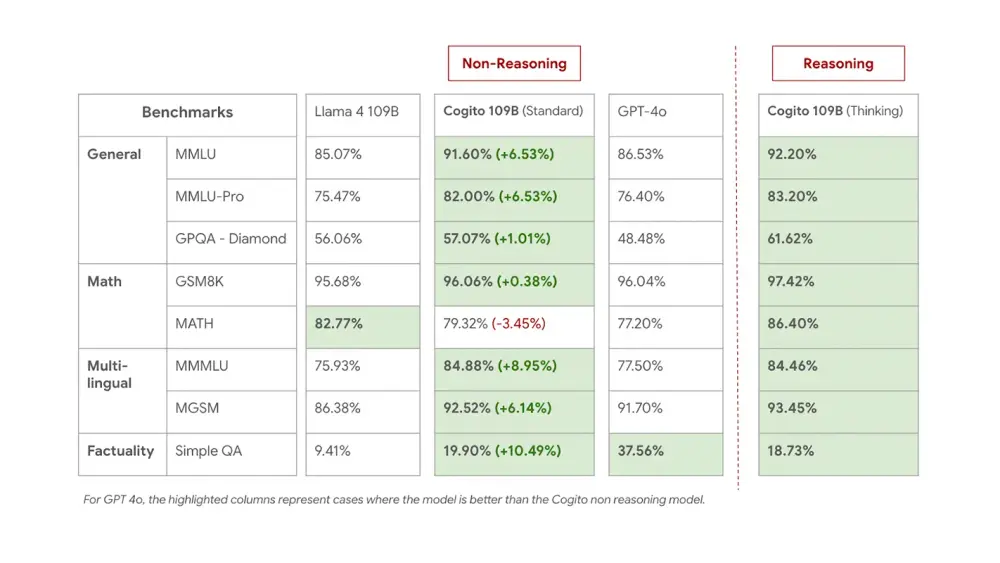
性能对比:开源模型中的佼佼者
| 模型 | 推理模式性能 | 推理链长度 | 非推理模式性能 |
|---|---|---|---|
| DeepSeek R1 | 高 | 长 | — |
| DeepSeek v3 | — | — | 高 |
| Cogito 671B MoE | ≥ R1 | -60% | ≥ v3 |
在闭源模型对比中:
- 略逊于 o3 和 Claude 4 Opus,但差距有限
- 显著优于其他开源模型(包括 Qwen、Llama 系列)
值得注意的是,这些模型尚未经历完整的后训练扩展(post-training scaling),当前性能仅为“概念验证”级别。团队计划后续通过梯度攀登进一步释放潜力。
成本效率惊人:总训练成本低于 350 万美元
一个常被忽视的事实是:许多“前沿”模型的训练成本高达数千万美元。而 Cogito 的全部八款模型(从 3B 到 671B)的总训练成本低于 350 万美元,涵盖:
- 合成数据生成
- 人工标注
- 超过 1000 次训练实验
- 基础设施与调优
这证明:超级智能的构建不一定依赖巨额资本投入,高效的训练范式同样关键。
意外能力:纯文本训练,却学会图像推理
尽管 Cogito 模型仅在纯文本数据上训练,且未接触任何图像-文本对,但在多模态任务中展现出惊人迁移能力。

例如,在给定两张图片(一只绿头鸭和一只雄狮)后,模型开启 enable_thinking 模式,能自主完成以下任务:
- 分析视觉元素(颜色、构图、情绪)
- 比较环境、行为、纹理差异
- 推断拍摄意图与美学特征
其输出逻辑严密、层次清晰,表现出类似人类的跨模态理解能力。
“我们没有训练它看图说话,但它学会了推理图像。”
这一现象表明:强大的语言推理能力本身可能蕴含通用感知先验,为未来多模态研究提供新思路。
⚠️ 注:该能力尚未在标准视觉基准上评估,仅作为研究观察。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











