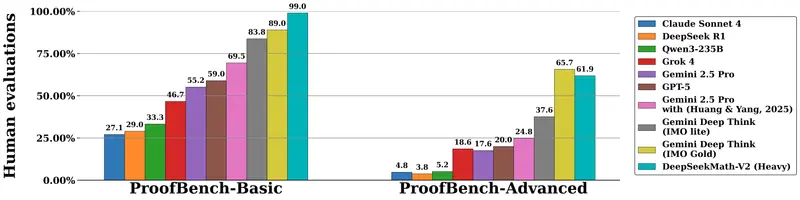
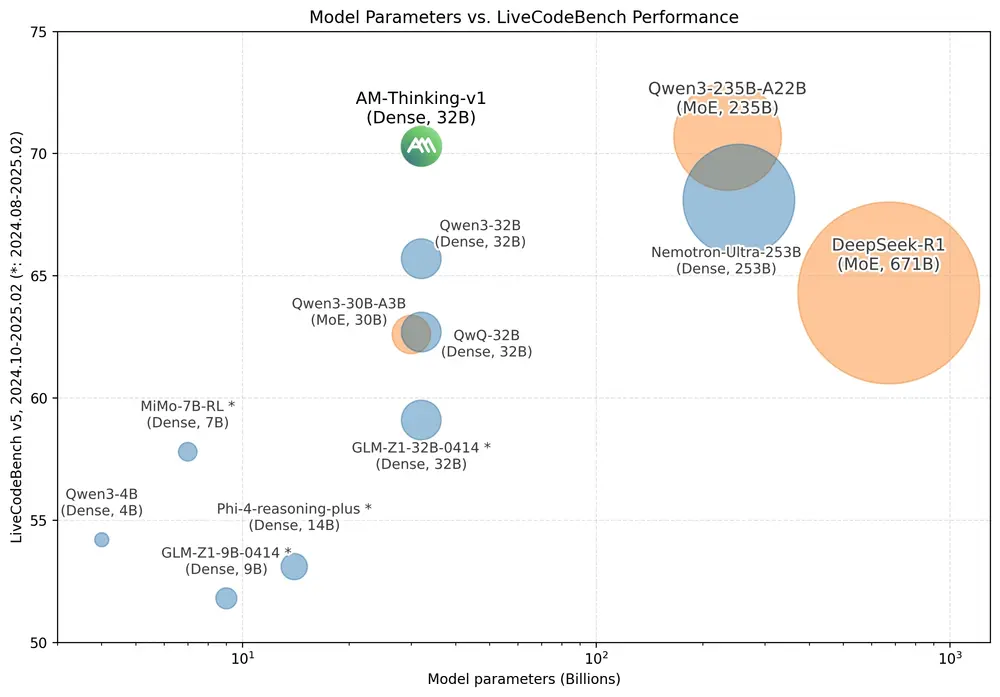
A-M-team推出了AM-Thinking-v1,一款基于Qwen 2.5-32B-Base构建的32B密集语言模型,专注于提升推理能力。在推理基准测试中,AM-Thinking-v1表现出色,可媲美更大的MoE模型(如DeepSeek-R1、Qwen3-235B-A22B、Seed1.5-Thinking)以及更大的密集模型(如Nemotron-Ultra-253B-v1)。
- 项目主页:https://a-m-team.github.io/am-thinking-v1
- 模型:https://huggingface.co/a-m-team/AM-Thinking-v1
- GGUF:https://huggingface.co/a-m-team/AM-Thinking-v1-gguf
AM-Thinking-v1 通过精心设计的后训练流程(包括监督微调和强化学习),在数学推理和代码生成等任务上达到了开源模型中的顶尖水平。例如,在 AIME 2024 和 AIME 2025 数学竞赛基准测试中,AM-Thinking-v1 分别取得了 85.3 和 74.4 的高分,在 LiveCodeBench 编程基准测试中也达到了 70.3 的成绩,展现出强大的推理能力。

主要功能
AM-Thinking-v1 的主要功能包括:
- 数学推理:能够解决复杂的数学问题,如 AIME 竞赛中的难题。
- 代码生成:能够生成高质量的代码,通过 LiveCodeBench 等基准测试。
- 科学推理:处理涉及自然科学和逻辑推理的问题。
- 指令遵循:准确执行给定的指令。
- 通用对话:支持开放性问题、常识和日常推理,支持单轮和多轮对话。
为什么32B推理模型很重要?
大型混合专家(MoE)模型如DeepSeek-R1或Qwen3-235B-A22B在排行榜上占据主导地位,但它们需要高性能GPU集群。许多团队只需要能在单张显卡上运行的最佳密集模型。AM-Thinking-v1填补了这一空白,且完全基于开源组件:
- 在AIME’24/’25和LiveCodeBench上超越DeepSeek-R1,接近Qwen3-235B-A22B,尽管参数量仅为其1/7。
- 基于公开可用的Qwen 2.5-32B-Base以及RL训练查询构建。
- 通过精心设计的后训练流程(SFT + 双阶段RL),从32B密集模型中榨取旗舰级推理能力。
- 可在单张A100-80GB上部署,延迟确定,无MoE路由开销。

🔧 后训练流程
为实现其强大的推理能力,AM-Thinking-v1经历了精心设计的后训练流程。以下是将其从基础模型转变为高性能推理模型的关键阶段:
步骤1 – 冷启动SFT
我们以开源的Qwen 2.5-32B-Base为基础,在数学、代码和开放域聊天的混合训练数据集上进行广泛的监督微调(SFT)。这赋予模型“先思考后回答”的行为模式,并为其提供初步的推理能力。
步骤2 – 通关率感知数据筛选
在进行强化学习(RL)之前,对SFT模型在每个数学和代码相关训练查询上进行评估,记录通关率。仅保留0 < 通关率 < 1的问题,剔除模型已完全掌握或完全失败的问题,集中学习真正有信息价值的内容。
步骤3 – 强化学习
我们采用双阶段GRPO方案:
- 阶段1:仅在数学和代码查询上训练。
- 阶段2:在第一阶段收敛后,移除模型100%正确回答的查询,并调整关键超参数,如最大生成长度和学习率。
测试结果
AM-Thinking-v1 在多个基准测试中表现出色:
- AIME 2024 和 AIME 2025:
- 在 AIME 2024 上,AM-Thinking-v1 的分数为 85.3,超过了 DeepSeek-R1(79.8)和 Qwen3-32B(81.4)。
- 在 AIME 2025 上,AM-Thinking-v1 的分数为 74.4,接近 Qwen3-235B-A22B(81.5)。
- LiveCodeBench:
- 在 LiveCodeBench 上,AM-Thinking-v1 的分数为 70.3,显著高于 DeepSeek-R1(64.3)和 Qwen3-32B(65.7)。
- Arena-Hard:
- 在 Arena-Hard 上,AM-Thinking-v1 的分数为 92.5,与 OpenAI-o1(92.1)和 o3-mini(89.0)相当,但低于 Qwen3-235B-A22B(95.6)。
⚠️ 局限性
虽然AM-Thinking-v1在纯语言推理和开放域聊天中表现出色,但尚未针对结构化函数调用或工具使用工作流进行训练,这限制了其在需要与外部系统交互的代理式应用中的实用性。提升模型遵循复杂指令的能力是我们未来的重要方向。此外,安全对齐仍处于早期阶段,需要更严格的红队测试以减少潜在风险。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











