蚂蚁集团正式宣布开源 Ring-flash-2.0 ——一款基于 MoE(混合专家)架构的高性能“思考型”大语言模型。该模型总参数量达 100B,但在每次推理时仅激活 6.1B 参数(其中非嵌入部分约 4.8B),通过高度稀疏化设计实现效率与能力的平衡。
更重要的是,团队自主研发的 IcePop 算法 成功解决了 MoE 模型在长链思维(Long-CoT)强化学习训练中的核心难题:训练与推理分布不一致导致的训练崩溃问题。
这一进展不仅提升了模型在数学、代码、逻辑等复杂任务上的表现,也为大规模 MoE 模型的稳定 RL 训练提供了可复用的技术路径。
核心定位:什么是 Ring-flash-2.0?
Ring-flash-2.0 是在 Ling-flash-2.0-base 基础上深度优化的推理专用版本,属于“思考模型”(reasoning model)类别——即专为解决需要多步推导、严密逻辑的任务而设计。
它并非通用对话模型,而是面向:
- 数学证明
- 编程解题
- 科学推理
- 医疗诊断辅助
等高阶认知场景。
尽管如此,令人意外的是,它在创意写作任务中也展现出接近其“非思考”兄弟模型 Ling-flash-2.0 的能力,表明其表达能力并未因强化推理而牺牲。
性能表现:挑战闭源模型上限
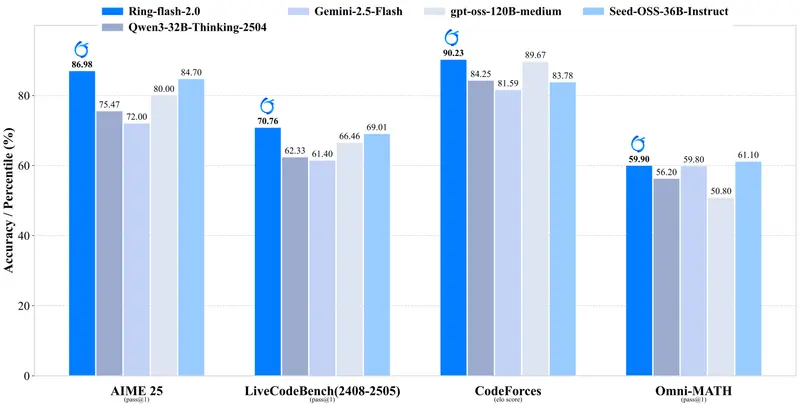
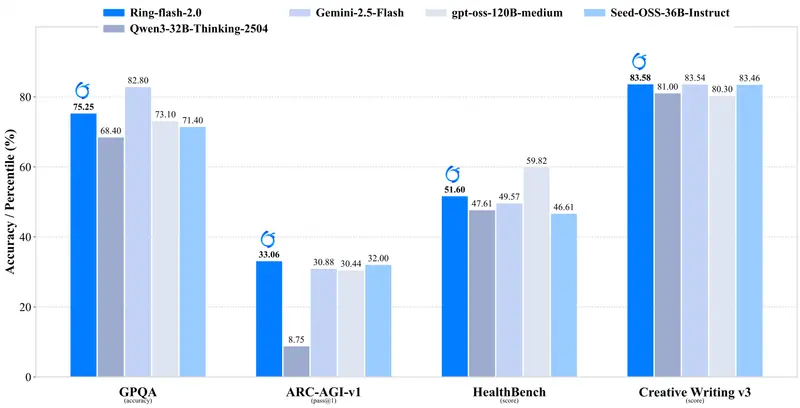
在多个具有挑战性的基准测试中,Ring-flash-2.0 表现出色,超越多数 40B 以下的密集模型,并与更大规模的开源 MoE 模型及部分闭源 API 相当。
✅ 关键评测结果概览
| 类别 | 基准 | Ring-flash-2.0 表现 |
|---|---|---|
| 数学竞赛 | AIME 25, Omni-MATH | 显著优于 Qwen3-32B-Thinking 和 Seed-OSS-36B-Instruct |
| 代码生成 | LiveCodeBench, CodeForce-Elo | 接近 GPT-OSS-120B(中等)水平 |
| 逻辑推理 | ARC-Prize | 在复杂问答任务中领先同类开源模型 |
| 专业领域 | GPQA-Diamond(科学)、HealthBench(医学) | 展现出强竞争力,适合专业辅助应用 |
| 创意写作 | Creative Writing v3 | 超越所有对比模型,匹配 Ling-flash-2.0 水平 |
对比模型包括:GPT-OSS-120B(中等)、Qwen3-32B-Thinking、Seed-OSS-36B-Instruct、Gemini-2.5-Flash。
这表明 Ring-flash-2.0 并未因专注推理而丧失通用性,反而实现了能力的协同提升。
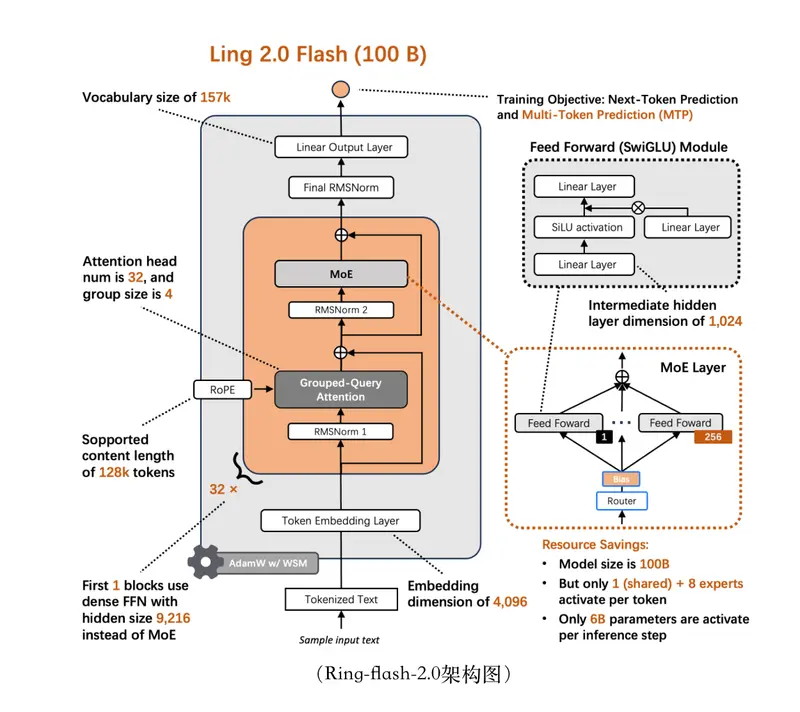
高效架构:低激活,高性能
Ring-flash-2.0 延续了 Ling 2.0 系列的高效 MoE 架构设计,关键指标如下:
- 总参数量:100B
- 每步激活参数:6.1B(含嵌入层),实际前馈网络激活仅约 4.8B
- 专家激活率:1/32(即每次仅调用 32 个专家中的 1 个)
- 结构优化:引入 MTP(Multi-Token Prediction)层,提升长序列建模效率
得益于高稀疏性与底层优化,仅需 4 块 H20 GPU 即可部署,并实现 200+ tokens/sec 的生成速度。
这意味着:
- 推理成本大幅降低
- 更适合高并发服务场景
- 可作为企业级复杂任务处理引擎使用
核心创新:IcePop 算法破解 MoE 强化学习难题
MoE 模型在强化学习(RL)阶段面临一个独特挑战:
训练与推理之间的行为偏差会随序列增长不断累积,最终导致训练崩溃。
具体表现为:
- 在 Long-CoT SFT 后接 RL 训练时,原始 GRPO 算法在有限步数内出现性能下降;
- 训练时预测 token 的概率分布与推理时差异逐渐扩大;
- 当相对差异超过 5%,模型开始输出无关或错误内容。
这个问题在密集模型中尚可控,但在 MoE 中更为严重——因为不同专家在训练/推理中可能被不同调度,加剧分布偏移。
为此,蚂蚁团队提出 IcePop(Iterative Calibration via Masked Probabilistic Pop-correction)算法,核心思想是:
对训练过程中的 token 分布进行动态校准,缩小训练与推理的差距。
IcePop 的关键技术机制
- 双向截断(Bidirectional Truncation)
- 不仅排除那些“训练概率远高于推理”的 token(防止过拟合训练信号)
- 还排除“训练概率远低于推理”的 token(防止忽略高频合理输出)
- 掩码梯度计算(Masked Gradient Update)
- 差异过大的 token 被从损失函数中剔除,不参与反向传播
- 保留稳定区域的学习信号,避免噪声干扰
- 迭代式分布对齐
- 在每个训练周期动态更新参考分布,逐步逼近推理状态
该方法有效延展了 MoE 模型在长序列、多步推理任务上的 RL 训练窗口,使复杂推理能力在整个训练过程中持续提升。
多阶段训练流程:SFT → RLVR → RLHF
为了系统性提升模型能力,团队采用三阶段训练 pipeline:
| 阶段 | 方法 | 目标 |
|---|---|---|
| 1. 轻量级 Long-CoT SFT | 使用多样化的思维链数据微调 | 赋予模型多种推理模式(如分步拆解、反证法等) |
| 2. RLVR(Reinforcement Learning with Verifiable Rewards) | 基于可验证信号(如执行结果、数学正确性)进行奖励建模 | 激发深层推理潜力,尤其适用于编程与数学任务 |
| 3. RLHF(Reinforcement Learning from Human Feedback) | 引入人类偏好数据优化输出风格与通用性 | 提升回答质量、可读性和安全性 |
为何选择两阶段 RL?
实验发现,将 RLVR 与 RLHF 联合训练虽效果相近,但容易引发长尾生成问题(即模型倾向于输出极端或罕见表达)。
考虑到工程稳定性与推理一致性,最终采用 先 RLVR、后 RLHF 的分阶段策略,在保证推理质量的同时控制风险。
局限与未来方向
当前版本仍存在一些限制:
- 对极长上下文(>32K)的支持有待加强
- 多语言能力集中在中英文,小语种覆盖有限
- 实时性要求极高的场景仍需进一步优化延迟
团队表示将持续迭代,重点推进:
- 更轻量化版本(如 30B 级别 MoE)
- 边缘设备适配方案
- 面向特定领域的垂直增强版本
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











