
近年来,软件开发中的代码编辑需求日益增长,尤其是在维护和重构已有项目时。然而,现有的大语言模型在面对多样化的代码修改任务时,往往表现不佳。为了解决这一问题,微软联合相关研究团队提出了一套全新的方法,并在此基础上推出了名为 NextCoder 的新一代代码编辑语言模型系列。
- GitHub:https://github.com/microsoft/NextCoder
- 模型:https://huggingface.co/collections/microsoft/nextcoder-6815ee6bfcf4e42f20d45028
问题背景
在实际软件工程中,开发人员常常需要对已有代码进行修改,而非从零开始编写新代码。然而,目前主流的代码语言模型(Code LMs)在处理这种多样化、上下文依赖性强的编辑任务时存在明显短板。
更严重的是,传统的微调方法容易导致模型在获得编辑能力的同时,失去原本在代码生成、指令理解等方面的能力。因此,如何在提升代码编辑性能的同时保留通用能力,成为了一个关键挑战。
核心方法创新
为解决上述问题,研究人员提出了两个关键技术点:
1. 多阶段合成数据生成流程
该流程从少量种子代码示例出发,结合多种编辑标准,自动生成高质量的代码编辑样本。这些样本不仅包含原始代码和修改后的代码,还包括不同风格和详细程度的自然语言指令。
整个流程包括以下几个主要组件:
- 问题与源代码生成
- 目标代码生成
- 指令生成
- 质量过滤
通过 GPT-4o 和 Llama3.3-70B 等强模型辅助生成,并结合高质量提交数据集 CommitPackFT 进行微调,最终构建出一个涵盖 8 种编程语言、约 127K 条高质量样本的数据集。
2. 新型适应算法 SeleKT
为了在不损失原有能力的前提下提升编辑性能,研究团队提出了一种新的参数微调算法——SeleKT(Selective Knowledge Transfer)。
其核心思想是:
- 利用密集梯度计算识别对代码编辑最关键的模型权重;
- 通过稀疏投影机制防止过拟合,使更新过程更具选择性;
- 周期性地重新评估参数,确保整体模型结构稳定。
这种方法显著优于传统 SFT、LoRA 和 TIES 方法,在多个基准测试中展现出更强的泛化能力和稳定性。
模型实现与特性
基于 Qwen2.5-Coder Instruct 变体,研究团队开发了 NextCoder 模型家族,提供 7B、14B 和 32B 三种规模,以满足不同场景下的需求。
其中,NextCoder-32B 是当前性能最强的版本,具备以下特点:
- 使用 SeleKT 后训练技术进行优化;
- 架构上支持 RoPE、SwiGLU、RMSNorm 和 Attention QKV 偏置;
- 支持高达 32K 的上下文长度;
- 参数总量为 32.5 亿,非嵌入参数为 31.0 亿;
- 层数为 64,注意力头数采用 GQA 设计(Q:40, KV:8)。
实验与结果分析
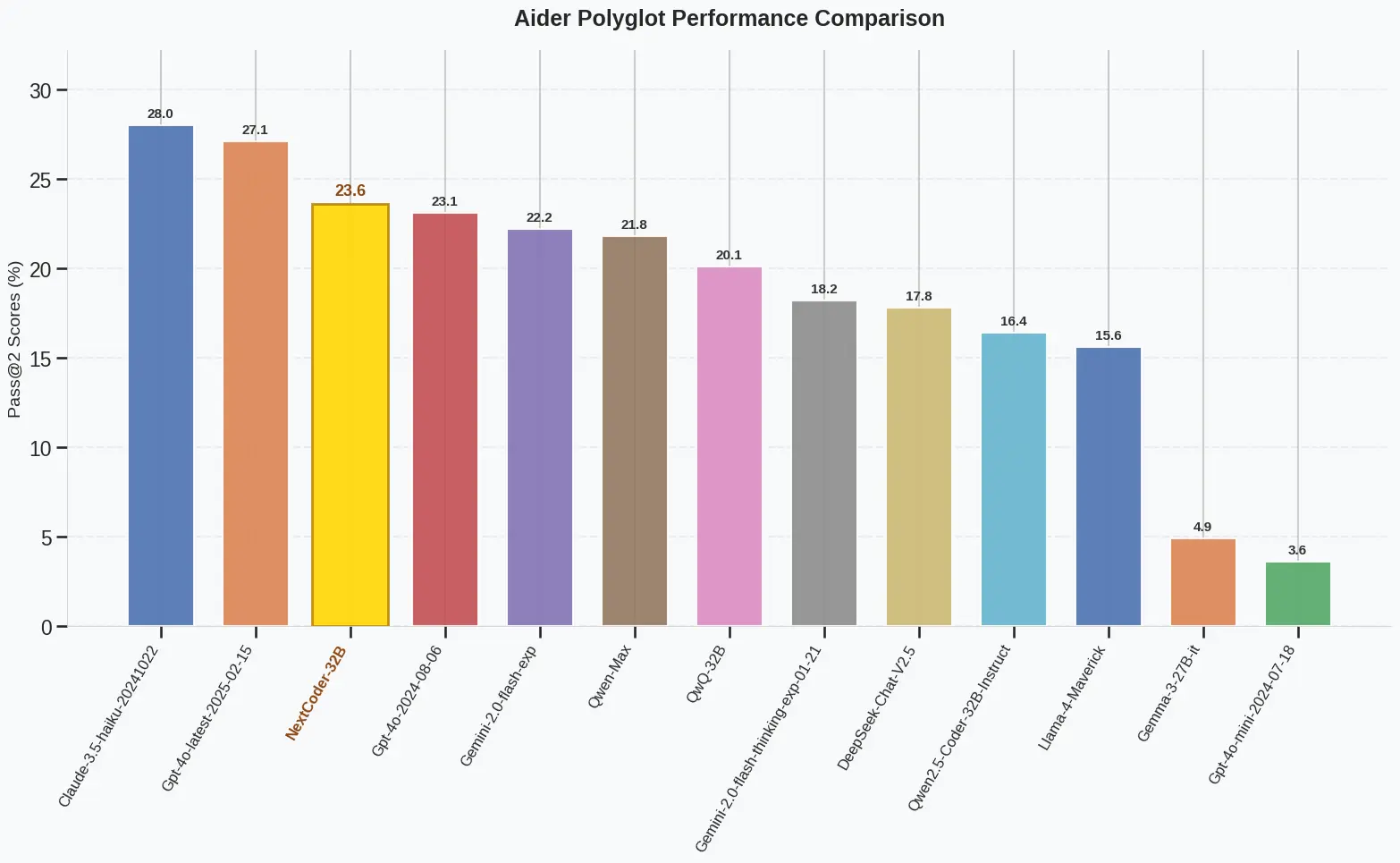
研究人员在多个代码编辑基准测试中评估了 NextCoder 的表现,包括 CanltEdit、HumanEvalFix、NoFunEval、Aider 和 Aider Polyglot。结果显示:
- NextCoder-7B 在所有基准测试中均优于同规模模型,甚至在部分任务上超越更大模型。
- NextCoder-32B 在 Aider Polyglot 测试中得分达 23.6%,超过 GPT-4o 的 18.2%。
- 在 HumanEvalFix 中,NextCoder-7B 准确率达 81.1%,远高于基础模型 QwenCoder-2.5-7B 的 73.8%。
此外,SeleKT 方法在保留代码生成和通用问题解决能力方面也表现出色。例如,在 HumanEval+ 基准中,SeleKT 的准确率为 84.8%,而传统方法如 SFT 和 LoRA 分别为 79.3% 和 81.7%。
总结
本研究通过引入合成数据生成流程和 SeleKT 适应算法,有效提升了代码语言模型在多样化编辑任务上的性能,同时保留了其原有的代码生成与理解能力。
未来的工作方向包括:
- 扩展数据生成管道,覆盖更多复杂编辑场景;
- 将 SeleKT 应用于其他类型的任务中,验证其通用性;
- 探索更高效的参数更新策略,进一步提升模型效率与效果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











