在大型语言模型(LLM)领域,自回归(Autoregressive)架构长期占据主导地位,但其“逐字生成”的特性已成为高延迟场景的痛点。今日,Inception Labs 正式推出 Mercury 2,一款基于扩散模型(Diffusion Model)的全新 LLM,旨在彻底解决这一瓶颈,为多步推理和智能体应用带来革命性的速度提升。
- 试用地址:https://chat.inceptionlabs.ai
核心突破:从“串行”到“并行”的范式转移
传统 LLM 像打字机一样,必须按顺序从左到右一个接一个地生成 Token。这意味着复杂的推理任务需要漫长的等待时间,延迟随步骤线性累积。
Mercury 2 采用了截然不同的扩散式文本生成机制:
- 并行生成:模型能在少量步骤中同时生成并优化大量 Token,而非逐个输出。
- 快速收敛:通过迭代去噪过程,迅速收敛到最终的高质量文本。
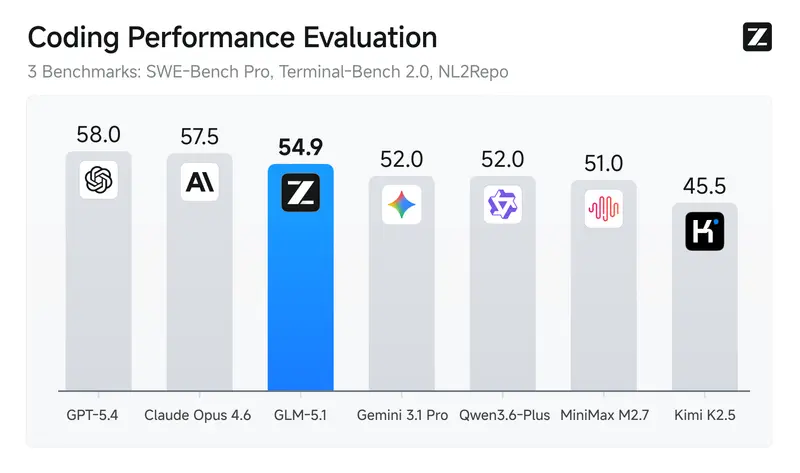
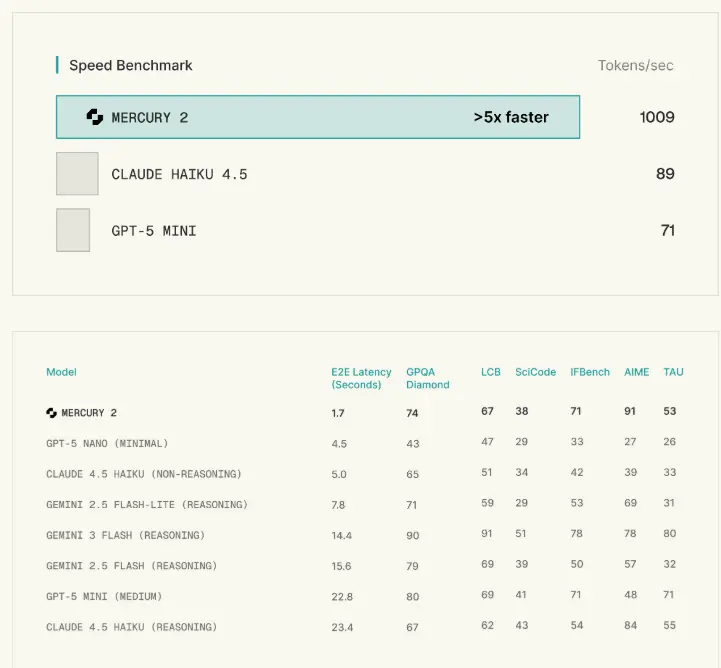
- 性能飞跃:在 NVIDIA Blackwell GPU 上,Mercury 2 实现了 1009 tokens/秒 的惊人吞吐量,远超同规模自回归模型。
“现代 AI 工作流不再是单次提示 - 响应,而是复杂的多步循环。自回归生成的延迟已成为系统瓶颈。” —— Inception Labs
专为推理与智能体打造
Mercury 2 并非通用聊天模型,而是专为高负载生产系统设计的推理引擎:
- 多步智能体循环:在 Agent 自主规划、执行、反思的闭环中,显著降低每一步的等待时间。
- 大规模数据提取:处理长文档检索、信息抽取任务时,利用 128K 原生上下文窗口 快速定位并输出结果。
- 可调推理能力:用户可根据任务复杂度动态调整推理步数,平衡速度与准确性。
- 原生工具与 JSON 支持:内置工具调用(Tool Use)能力和结构化 JSON 输出模式,无缝对接自动化工作流。
极具竞争力的定价与生态兼容
Inception Labs 不仅提供了技术突破,还制定了激进的市場策略:
- 超低定价:
- 输入:$0.25 / 1M tokens
- 输出:$0.75 / 1M tokens
- 相比主流闭源模型,成本降低了一个数量级。
- OpenAI API 兼容:完全兼容 OpenAI API 标准,开发者无需修改代码即可切换至 Mercury 2,实现无缝迁移。
- 企业级反馈:早期合作伙伴报告称,在转录清理和自动化工作流中,延迟显著降低,吞吐量大幅提升。
基准测试与实测表现
Inception Labs 公布的数据显示,Mercury 2 在多项推理基准测试中表现优异,尤其是在需要长上下文理解和多步逻辑推导的任务中。其吞吐量在同等硬件条件下是传统自回归模型的 5-10 倍,使得实时交互式 AI 应用成为可能。
行业意义:扩散模型的文字时代?
Mercury 2 的发布标志着扩散模型正式从图像生成领域进军文本生成核心地带。
- 技术验证:证明了非自回归架构在复杂文本任务中的可行性与优越性。
- 应用前景:为实时翻译、高频交易分析、即时客服等对延迟极度敏感的场景打开了新大门。
- 生态影响:随着更多厂商跟进,LLM 的架构多样性将大幅增加,打破自回归模型的垄断地位。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...