智谱 AI 今日正式开源 GLM-5.1,这是其面向智能体工程(Agent Engineering)的下一代旗舰模型。与以往追求“单次响应速度”的模型不同,GLM-5.1 的核心突破在于长时优化能力——它能在数百轮迭代和数千次工具调用中保持高效,通过自我反思和策略修订,持续解决复杂模糊的问题。
- 官方介绍:https://z.ai/blog/glm-5.1
- GitHub:https://github.com/zai-org/GLM-5.1
- 模型:https://huggingface.co/zai-org/GLM-5.1
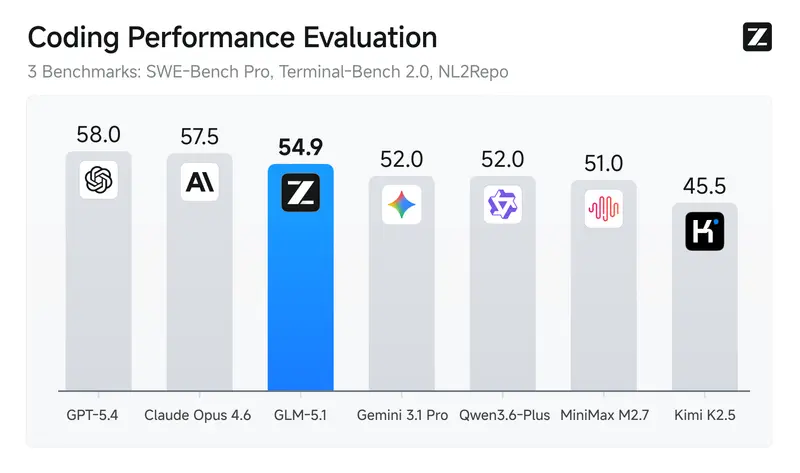
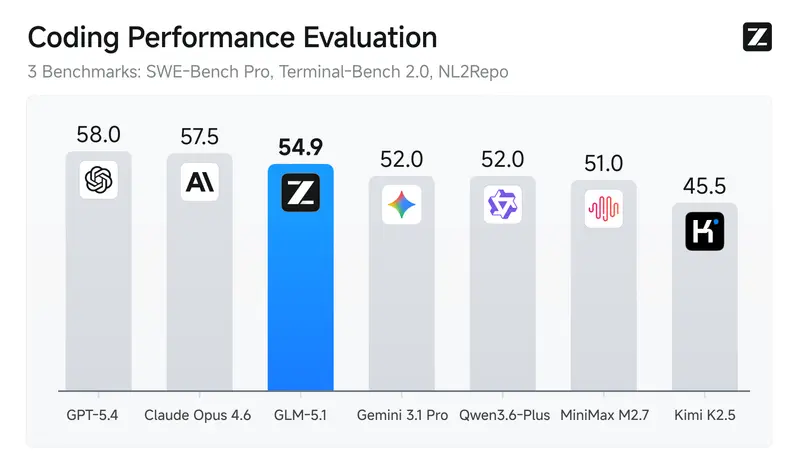
GLM-5.1 在 SWE-Bench Pro 上取得 SOTA 性能,并在 NL2Repo 和 Terminal-Bench 2.0 上显著超越前代 GLM-5。更重要的是,它打破了传统模型在长会话中过早进入“能力平台期”的瓶颈,实现了“运行时间越长,结果越好”的良性循环。
核心突破:从“快速试错”到“持续进化”
传统模型(包括 GLM-5)在面对复杂任务时,往往在初期利用熟悉技术获得快速收益,随后便陷入停滞,即使给予更多时间也无济于事。GLM-5.1 通过以下机制解决了这一痛点:
- 长效判断力:能更好地处理模糊需求,在长会话中不迷失方向。
- 结构化分解:将大问题拆解为可执行的小步骤,并通过实验验证每一步。
- 自我修正循环:反复审视推理过程,识别障碍并调整策略,支持数千次工具调用的连贯执行。
三大场景验证:长时优化的威力
1. 向量数据库优化:600+ 次迭代的奇迹
- 任务:在 VectorDBBench 挑战中,优化 Rust 实现的近似最近邻搜索算法。
- 对比:传统限制为 50 次工具调用,最佳结果为 Claude Opus 4.6 的 3,547 QPS。
- GLM-5.1 表现:
- 在开放迭代模式下,经过 600+ 次提交 和 6,000+ 次工具调用。
- 最终达到 21.5k QPS,是单次会话最佳结果的 6 倍。
- 阶梯式进化:模型自主发现了 6 次结构性转变(如引入 IVF 集群、u8 预评分+f16 重排),每次都在分析日志后突破瓶颈。
2. GPU 内核加速:持久优化的耐力赛
- 任务:在 KernelBench Level 3(全模型端到端优化)中,加速 PyTorch 实现。
- 表现:
- GLM-5:初期改进快,但较早 plateau。
- GLM-5.1:维持有效优化时间显著更长,最终实现 3.6 倍加速。
- 对比:虽略低于 Claude Opus 4.6 的 4.2 倍,但展现了极强的长尾优化潜力,且远超 torch.compile 默认模式(1.15x)。
3. Web 应用构建:8 小时打造 Linux 桌面
- 任务:从零构建一个功能完整的 Linux 风格 Web 桌面环境,无明确指标,仅靠主观审美和功能完整性评判。
- 表现:
- 传统模型:生成基本框架后很快宣布完成,缺乏自我质疑机制。
- GLM-5.1:在 8 小时的持续循环中,逐步添加文件浏览器、终端、文本编辑器、系统监视器等组件。
- 结果:最终交付了一个视觉一致、交互流畅、功能完备的桌面环境,证明了其在无数值指标任务中的自我评估与长期规划能力。
获取与使用
1. API 与订阅服务
- 平台:可通过 api.z.ai 和 BigModel.cn 调用。
- GLM Coding Plan:
- 所有订阅用户现已可用,只需将模型名改为
"GLM-5.1"。 - 配额消耗:高峰时段(14:00–18:00 CST)消耗 3 倍,非高峰时段消耗 2 倍。
- 限时优惠:截至 4 月底,非高峰时段按 1 倍 计费。
- 所有订阅用户现已可用,只需将模型名改为
- Z Code:提供图形化界面,支持多智能体协同、SSH 远程开发及移动端任务启动。
2. 本地部署与开源
- 许可证:MIT License,完全开源,可商用。
- 权重下载:
- 推理框架:支持 vLLM 和 SGLang,详细部署指南见官方 GitHub。
- 兼容性:完美适配 Claude Code、OpenClaw、OpenCode、Kilo Code 等主流智能体框架。
为什么 GLM-5.1 很重要?
GLM-5.1 标志着 AI 智能体从“聊天机器人”向“自主工程师”的关键转变。它证明了:
- 时间即智能:对于复杂工程任务,给予模型足够的时间和自我修正机制,能产生质的飞跃。
- 自我评估是关键:在没有明确指标的任务中,模型必须具备“退后一步审视全局”的能力。
- 开源赋能开发者:通过 MIT 协议开源,让全球开发者能在本地构建私有化的长时智能体工作流,无需依赖云端黑盒。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...