让语言模型“集体进化”:Gensyn推出去中心化强化学习新算法 SAPO在提升语言模型推理能力的道路上,传统方法往往依赖大量人工标注数据进行监督微调(SFT),或集中式强化学习系统完成后训练。然而,这类方式成本高昂、扩展困难,且对硬件资源要求严苛。 最近,AI初创公司 G...大语言模型# SAPO# 强化学习7个月前01120
清华、上交大等团队提出 SSRL:无需外部搜索的强化学习新范式在当前主流的“代理式搜索”(Agentic Search)系统中,大型语言模型(LLM)通常通过调用外部搜索引擎(如 Google、Bing 或专用 API)来获取实时信息,以回答复杂问题。这一模式虽...大语言模型# SSRL# 强化学习8个月前02120
INTELLECT-2 发布:首个通过全球分布式强化学习训练的 32B 参数模型Prime Intellect发布 INTELLECT-2,这是首个通过全球分布式强化学习训练的 32B 参数模型。与传统的集中式训练不同,INTELLECT-2 使用完全异步的强化学习(RL),在一...大语言模型# INTELLECT-2# 强化学习11个月前02800
Flow-GRPO:将在线强化学习与流匹配模型相结合,用于提升文生图模型生成任务的性能香港中文大学MM实验室、清华大学、快手科技、南京大学和上海人工智能实验室推出新方法Flow-GRPO,它将在线强化学习(Reinforcement Learning, RL)与流匹配(Flow Mat...新技术# Flow-GRPO# 强化学习# 流匹配11个月前04730
OpenAI宣布第三方开发者现在可通过强化学习微调o4-mini模型,打造企业专属AI助手OpenAI今天宣布,第三方开发者现在可以通过强化学习(RFT)对o4-mini语言推理模型进行微调。这一功能的推出,使企业能够根据自身需求定制专属的私有版本,从而更好地服务于内部沟通、知识管理、任务...早报# o4-mini# OpenAI# 强化学习11个月前01900
阿里通义实验室开源R1-Omni:用强化学习解锁全模态大模型的新潜力随着DeepSeek R1的发布,强化学习在大模型领域的潜力得到了进一步挖掘。Reinforcement Learning with Verifiable Reward(RLVR)方法为多模态任务提供...多模态模型# R1-Omni# 全模态大模型# 强化学习1年前02270
阿里Qwen团队推出强化学习增强的推理模型QwQ-32B阿里云的Qwen团队最近宣布了一项重要进展,他们通过整合大规模强化学习(RL)技术来提升大语言模型的智能水平,并推出了新的推理模型QwQ-32B。这款拥有320亿参数的模型,在性能上能够与具有6710...大语言模型# Qwen# QwQ-32B# 强化学习1年前03320
2024 年图灵奖授予强化学习领域的先驱:安德鲁·G·巴托和理查德·S·萨顿在计算机科学领域,两位杰出的科学家因其在强化学习领域的贡献而荣获2024年的图灵奖。这项技术让机器能够通过基于奖励的试错方法进行学习,从而适应各种受限或动态环境。 强化学习的奠基者 安德鲁·G·巴托...早报# 图灵奖# 安德鲁·G·巴托# 强化学习1年前02190
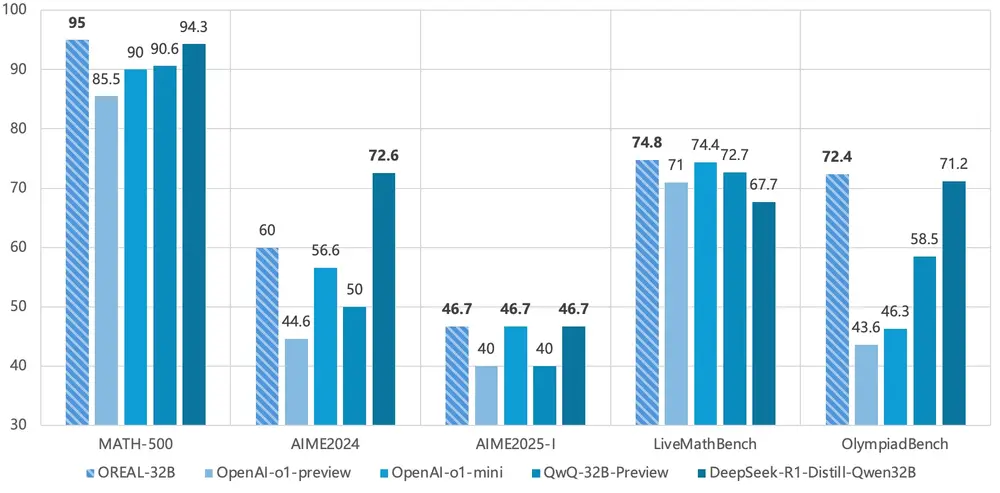
强化学习新范式OREAL:基于结果奖励的强化学习(RL)提升大语言模型在数学推理任务中的表现上海AI实验室、上海交通大学、香港中文大学和InnoHK的研究人员提出基于结果奖励的强化学习新范式OREAL,通过基于结果奖励的强化学习(RL)提升大语言模型(LLMs)在数学推理任务中的表现。该框架...新技术# OREAL# 大语言模型# 强化学习1年前04400