
香港中文大学MM实验室、清华大学、快手科技、南京大学和上海人工智能实验室推出新方法Flow-GRPO,它将在线强化学习(Reinforcement Learning, RL)与流匹配(Flow Matching)模型相结合,用于提升文本到图像(Text-to-Image, T2I)生成任务的性能。
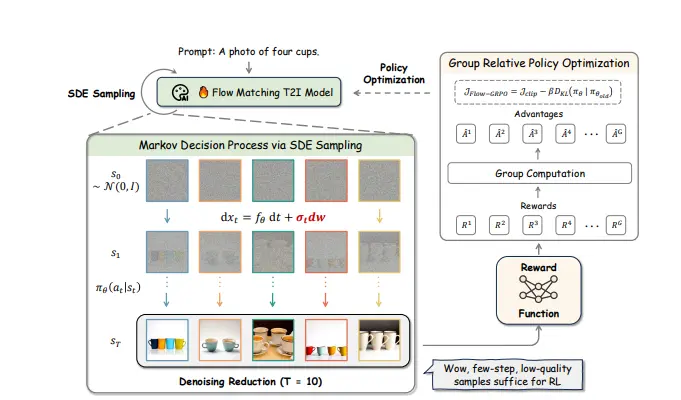
Flow-GRPO 是一种创新的 T2I 模型训练方法,通过在线强化学习提升流匹配模型在复杂场景生成、文本渲染等任务中的表现。流匹配模型是一种基于连续时间归一化流的生成模型,能够通过少量的常微分方程(ODE)步骤高效生成高质量图像。然而,传统流匹配模型在处理复杂场景(如多个对象、属性和关系的组合)和文本渲染任务时存在挑战。Flow-GRPO 通过引入在线 RL,克服了这些限制,显著提升了模型的性能。

模型
| Task | Model |
|---|---|
| GenEval | GenEval |
| Text Rendering | Text |
| Human Preference Alignment | PickScore |
主要功能
Flow-GRPO 的主要功能包括:
- 复杂场景生成:能够精确控制对象的数量、空间关系和细粒度属性。例如,在 GenEval 基准测试中,Flow-GRPO 将 Stable Diffusion 3.5 Medium(SD3.5-M)的准确率从 63% 提升到 95%。
- 文本渲染:能够准确渲染提示中指定的文本内容。在视觉文本渲染任务中,Flow-GRPO 将准确率从 59% 提升到 92%。
- 人类偏好对齐:通过人类偏好奖励模型(如 PickScore)对生成的图像进行优化,使其更符合人类审美标准。
主要特点
Flow-GRPO 的主要特点包括:
- 在线强化学习集成:首次将在线 RL 与流匹配模型结合,通过策略优化提升模型性能。
- ODE 到 SDE 转换:将确定性的常微分方程(ODE)转换为随机微分方程(SDE),为 RL 探索引入随机性。
- 去噪步骤减少:在训练时减少去噪步骤,显著提高采样效率,同时在推理时保留完整的去噪步骤以保持图像质量。
- KL 约束防止奖励欺骗:通过 Kullback-Leibler(KL)散度约束,防止模型在优化奖励时降低图像质量或多样性。
工作原理
Flow-GRPO 的工作原理基于以下几个关键策略:
- ODE 到 SDE 转换:通过将 ODE 转换为 SDE,为模型引入随机性,使其能够在 RL 探索中进行统计采样。
- 去噪步骤减少(Denoising Reduction):在训练时减少去噪步骤,加快数据生成速度,同时在推理时保留完整的去噪步骤以生成高质量图像。
- 策略优化(GRPO):采用 Group Relative Policy Optimization(GRPO)算法,通过计算奖励优势来更新模型策略,优化生成图像的质量和多样性。
测试结果
Flow-GRPO 在多个任务上的测试结果如下:
- 复杂场景生成:在 GenEval 基准测试中,Flow-GRPO 将 SD3.5-M 的准确率从 63% 提升到 95%,显著优于其他模型。
- 文本渲染:在视觉文本渲染任务中,Flow-GRPO 将准确率从 59% 提升到 92%,大幅提高了文本生成的准确性。
- 人类偏好对齐:在人类偏好对齐任务中,Flow-GRPO 在 PickScore 上的表现优于其他模型,且在图像质量上没有明显下降。
- 图像质量评估:在 DrawBench 基准测试中,Flow-GRPO 在审美评分、DeQA 评分、ImageReward 和 UnifiedReward 等指标上均表现出色,证明了其在提升性能的同时保持了图像质量和多样性的能力。
总之,Flow-GRPO 通过将在线 RL 与流匹配模型相结合,显著提升了 T2I 模型在复杂场景生成、文本渲染和人类偏好对齐等任务中的性能,同时保持了图像质量和多样性,具有广泛的应用前景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











